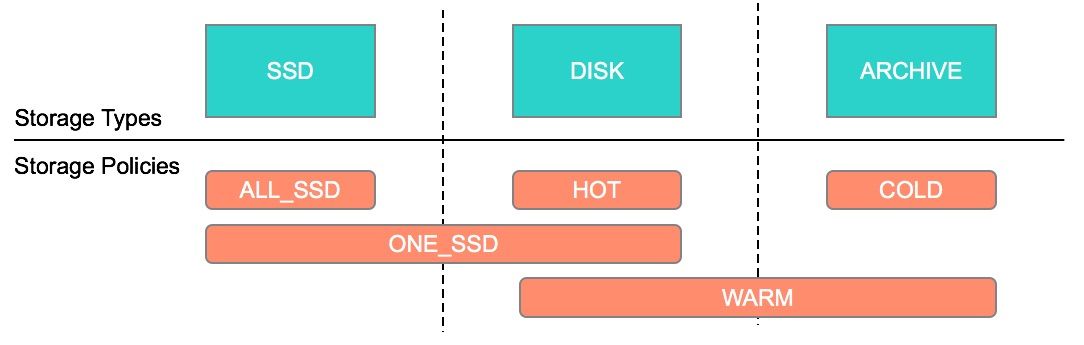
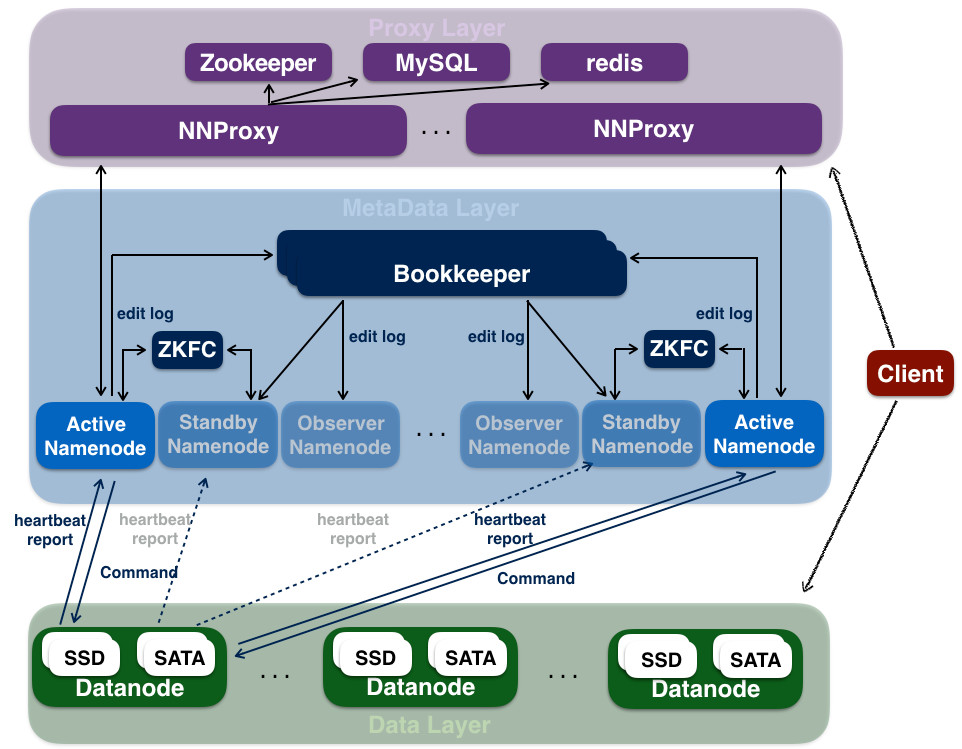
HDFS 架构介绍 HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。 首先我们来介绍一下B站的HDFS离线存储平台的总体架 w397090770 3年前 (2022-04-01) 1175℃ 0评论4喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 469℃ 0评论3喜欢
背景 现状 HDFS 全称是 Hadoop Distributed File System,其本身是 Apache Hadoop 项目的一个模块,作为大数据存储的基石提供高吞吐的海量数据存储能力。自从 2006 年 4 月份发布以来,HDFS 目前依然有着非常广泛的应用,以字节跳动为例,随着公司业务的高速发展,目前 HDFS 服务的规模已经到达“双 10”的级别: 单集群节点 10 万台级别单 w397090770 4年前 (2021-07-29) 569℃ 0评论2喜欢
背景随着集群规模的不断扩张,文件数快速增长,目前集群的文件数已高达2.7亿,这带来了许多问题与挑战。首先是文件目录树的扩大导致的NameNode的堆内存持续上涨,其次是Full GC时间越来越长,导致NameNode宕机越发频繁。此外,受堆内存的影响,RPC延时也越来越高。针对上述问题,我们做了一些相关工作:控制文件数增长 w397090770 4年前 (2021-07-02) 1368℃ 0评论4喜欢
本文来自车好多大数据离线存储团队相关同事的投稿,本文作者: 车好多大数据离线存储团队:冯武、王安迪。升级的背景HDFS 集群作为大数据最核心的组件,在公司承载了DW、AI、Growth 等重要业务数据的存储重任。随着业务的高速发展,数据的成倍增加,HDFS 集群出现了爆炸式的增长,使用率一直处于很高的水位。同时 HDFS文件 w397090770 4年前 (2020-11-24) 1401℃ 0评论2喜欢
HDFS集群随着使用时间的增长,难免会出现一些“性能退化”的节点,主要表现为磁盘读写变慢、网络传输变慢,我们统称这些节点为慢节点。当集群扩大到一定规模,比如上千个节点的集群,慢节点通常是不容易被发现的。大多数时候,慢节点都藏匿于众多健康节点中,只有在客户端频繁访问这些有问题的节点,发现读写变慢了, w397090770 4年前 (2020-11-12) 1646℃ 0评论7喜欢
Hadoop 社区推出了新一代分布式Key-value对象存储系统 Ozone,同时提供对象和文件访问的接口,从构架上解决了长久以来困扰HDFS的小文件问题。本文作为Ozone系列文章的第一篇,抛个砖,介绍Ozone的产生背景,主要架构和功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop背景HDFS是业界默认的 w397090770 5年前 (2020-05-26) 1944℃ 1评论1喜欢
介绍HDFS 归档存储(Archival Storage)是从 Hadoop 2.6.0 开始引入的(参见 HDFS-6584)。归档存储是一种将增长的存储容量与计算容量解耦的解决方案。我们可以在集群中部署一些具有更高密度、更便宜的存储且提供更低计算能力的节点,并且可以用作集群中的冷数据存储器。根据我们的设置,可以将热数据移到冷存储介质中。通过添加更 w397090770 5年前 (2020-04-15) 1814℃ 0评论3喜欢
本文来自 2019年9月23日至26日在纽约举办的 Strata Data Conference,分享者是来自 Cloudera 的 Wangda Tan 和 Wei-Chiu Chuang,会议页面 https://conferences.oreilly.com/strata/strata-ny-2019/public/schedule/detail/77506。请关注 过往记忆大数据 微信公众号,并在后台回复 hadoop_3 关键字获取本文的 PPT 下载地址。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 5年前 (2020-02-04) 2421℃ 2评论5喜欢
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 5年前 (2020-01-10) 2410℃ 0评论4喜欢