

本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Tencent at Scale Usability Extension Stability Improvement》,分享者Junyi Huang 和 Pan Liu,均为腾讯软件工程师。Presto 已被腾讯采用为不同业务部门提供临时查询和交互式查询场景。在这次演讲中,作者将分享腾讯在生产中关于 Presto 的实践。
关注 过往记忆大数据公众号回复 10110tx 获取本文资料。
本次分享主要有以下几个内容:
Presto 在腾讯的使用状况
- 可用性扩展
- 稳定性改善
- 性能优化
- 未来工作
Presto 在腾讯的使用状况

上面是目前 Presto 在腾讯的使用状况。集群规模为 500+ 台 Worker,每天10W+查询,处理 2+PB 的数据,P50 查询时间在50s内。
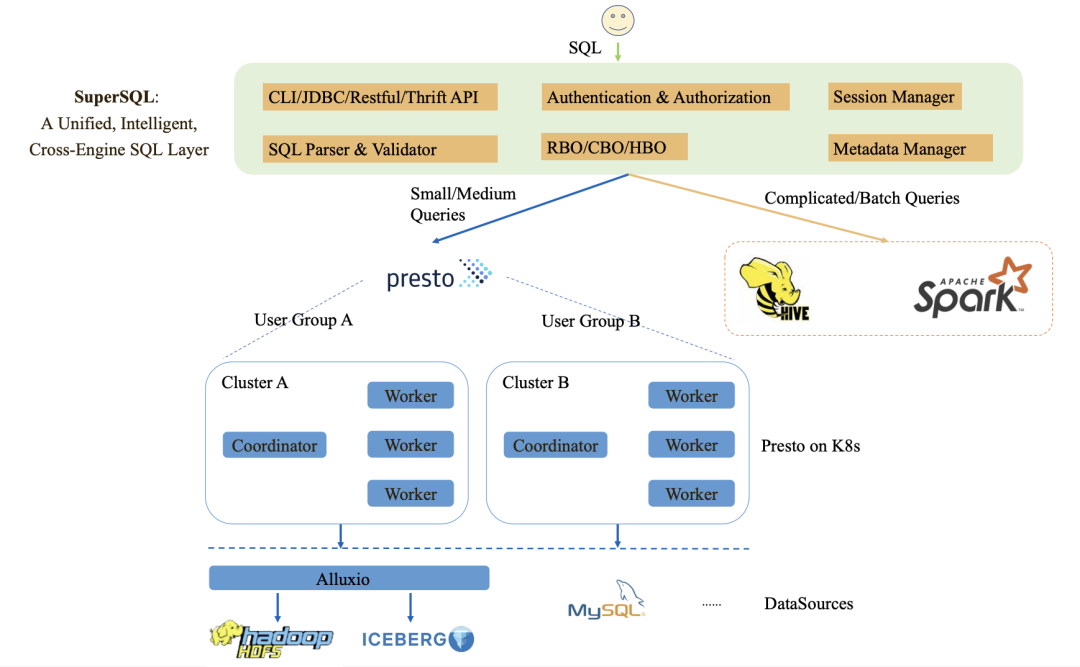
用户的 SQL 提交到一个称为 SuperSQL 的中间件中,其实腾讯内部一个统一、智能、跨引擎的 SQL 处理层。 SuperSQL 会解析用户提交过来的 SQL,校验并利用 RBO、CBO 以及 HBO 的东西将 SQL 转发到 Presto 或者 Spark 集群中。比如小或者中等规模的查询转发到 Presto 处理;ETL 转发到 Spark 中。
可用性扩展
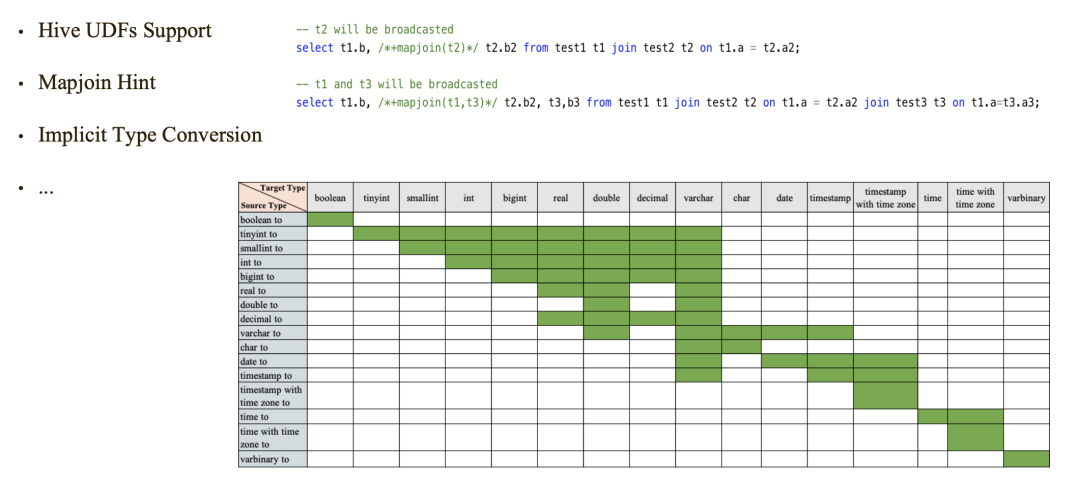
在可用性方面,腾讯对 Presto 进行了改造,使其支持 Hive UDF、MapJoin Hint 以及 隐形类型转换等。

查询的 Metrics 会进行保存,供 HBO 、性能分析等使用,同时腾讯 Presto 团队还在做 Presto 历史服务器等功能。

我们知道,原生的 Presto 配置 Catalog 是需要重启集群的。而腾讯对这个进行了改造,使得 Presto 支持动态 Catalog 配置,动态 Catalog 信息是保存到 Catalog Store(猜想应该是元数据等服务)。对 Catalog 的增删操作都是发到 Coordinator,然后再由 Coordinator 同步到 Worker。
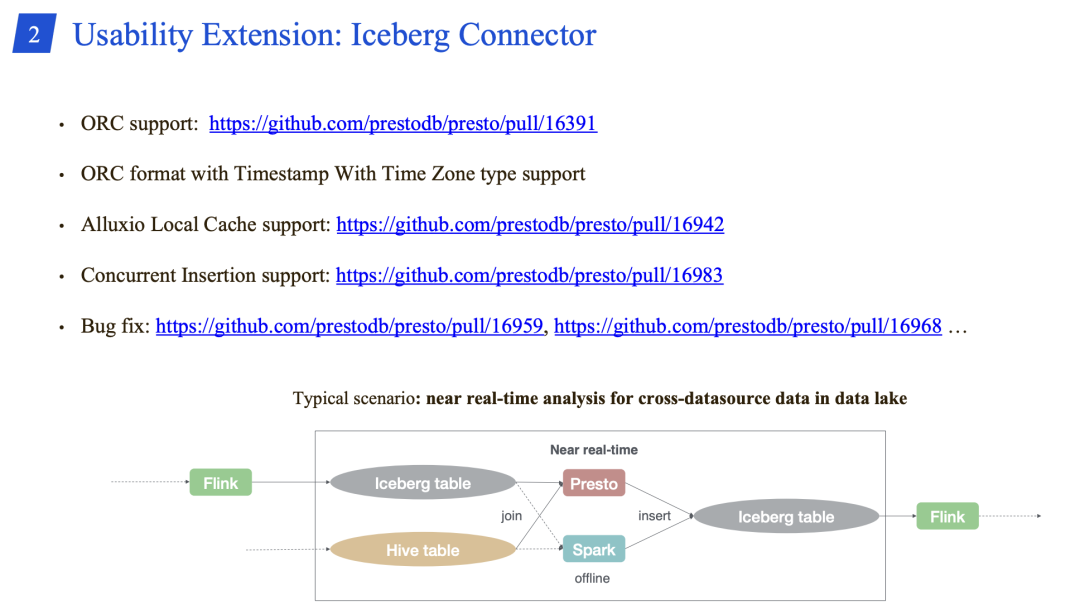
Presto 的 Iceberg 数据源的社区进行了一些功能提升,腾讯 Presto 团队将一些有用的 Patch Merge 到自己分支。
稳定性改善
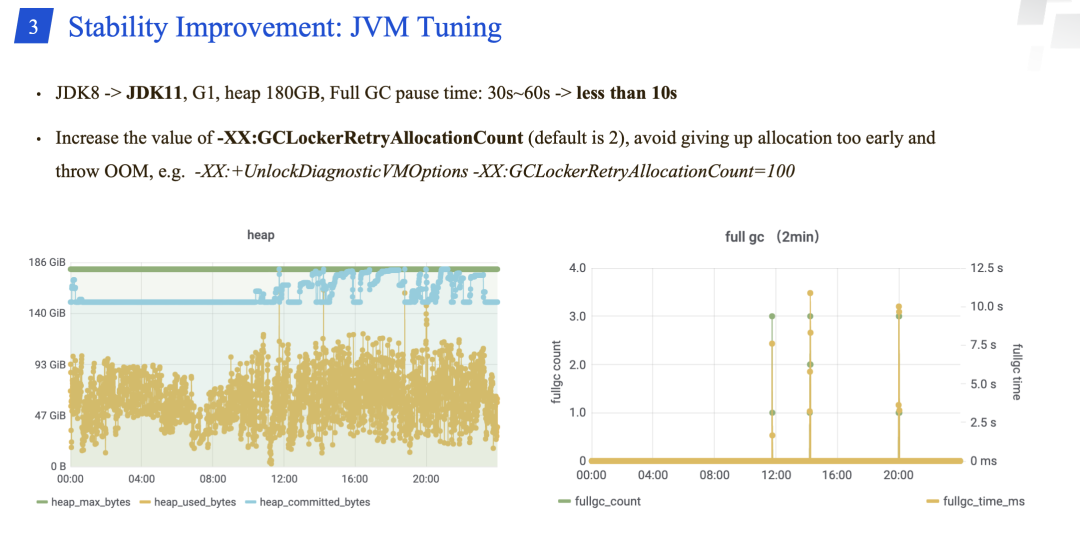
稳定性建设之一是 JVM 调优。主要包括 JDK 由8升级到11. -XX:GCLockerRetryAllocationCount 增加到 100。
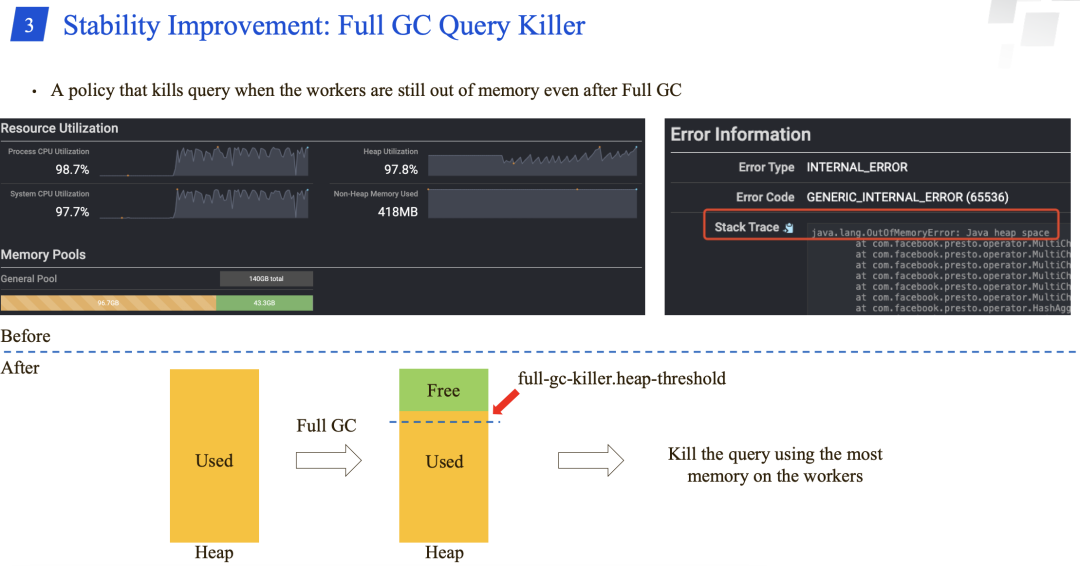
腾讯 Presto 团队弄了一个新的策略:在 Full GC 之后,如果 workers 还出现 OOM 的问题,就会 kill 掉 workers 上使用内存最多的查询。

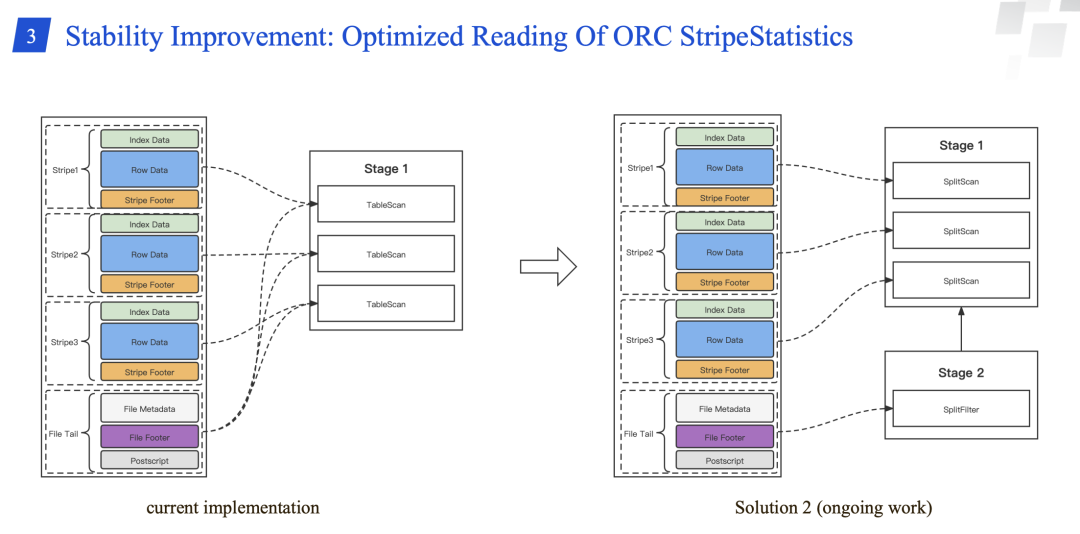
ORC 文件如果有很多 stripes 的话,很容易导致 Worker 出现 OOM,对于这个问题主要有以下两个解决办法:
-
将大的 ORC 文件拆分成 stripe 比较合适的小文件,但是这个需要修改用户的数据。
-
优化 Presto ORC Reader,不需要在不同的 splits 中读取相同 ORC文件的重复 StripeStatistics。

其他扩展性提升:
-
对重要业务的不同类型工作负载使用独立集群处理;
-
限制查询的 split 数,避免大查询以及处理许多小文件的查询;
-
转发到 Presto 的查询失败时会通过 SuperSQL 自动转发到 Hive/Spark,这个操作对用户是无感知的。
-
减少 hive.dfs-timeout 来避免从 HDFS DataNode 读取数据时等待过长的时间。
性能优化
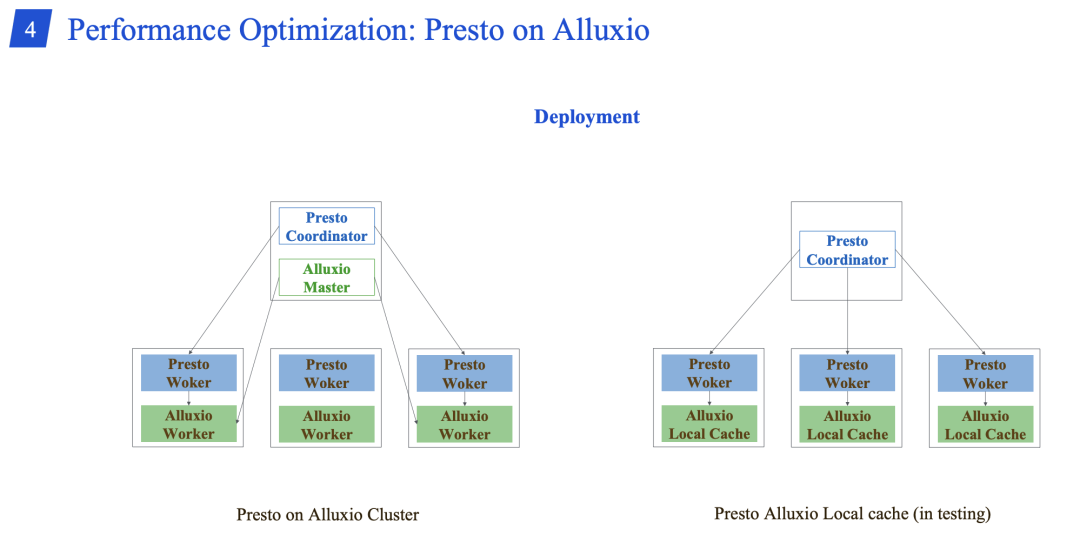
引入了 Presto on Alluxio,目前 Alluxio 节点和 Presto 是混部的,Presto Alluxio Local Cache 正在测试中。

-
对不同的数据源使用不同的路由策略。
-
当路由的时候,会检查 Alluxio 集群的健康,如果 Alluxio 路径不可访问时自动使用 HDFS 路径;
-
热数据范围是由用户在白名单中指定的,其可以支持多个 Alluxio 集群;
-
第一次读取数据时,把数据缓存到 Alluxio 中。数据的过期和 evict 都是自动的。
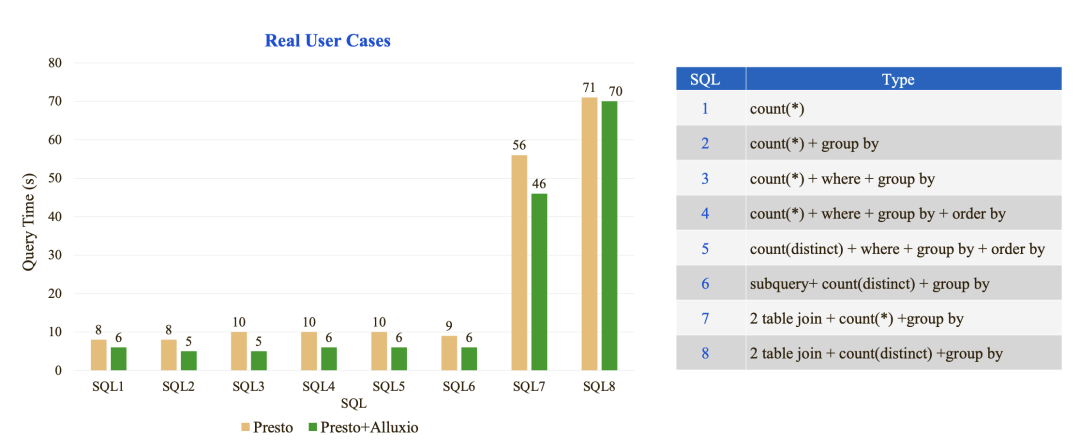
上面是 Presto on Alluxio 的性能测试,主要选取了8中类型的 SQL 进行了测试。(过往记忆大数据备注:性能提升看起来不明显啊?)
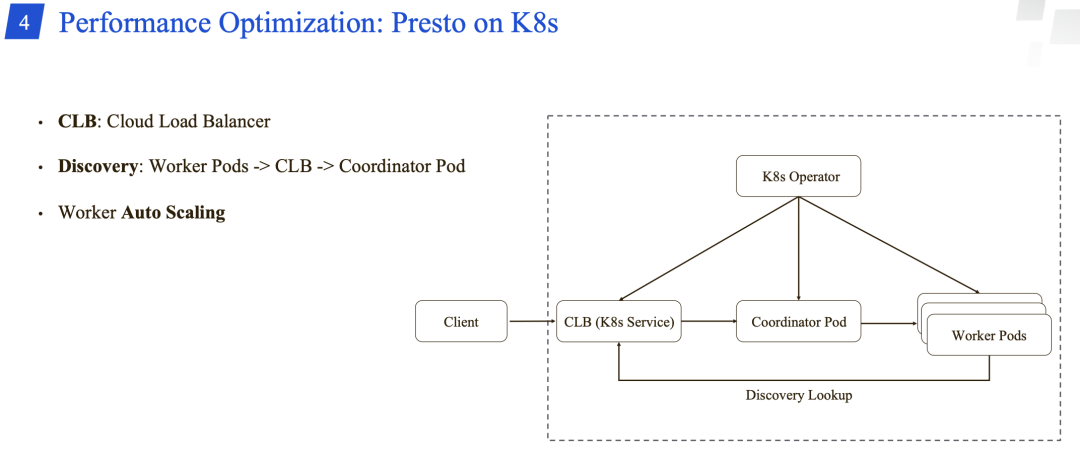
目前,腾讯的 Presto 是部署在 K8S 上的。
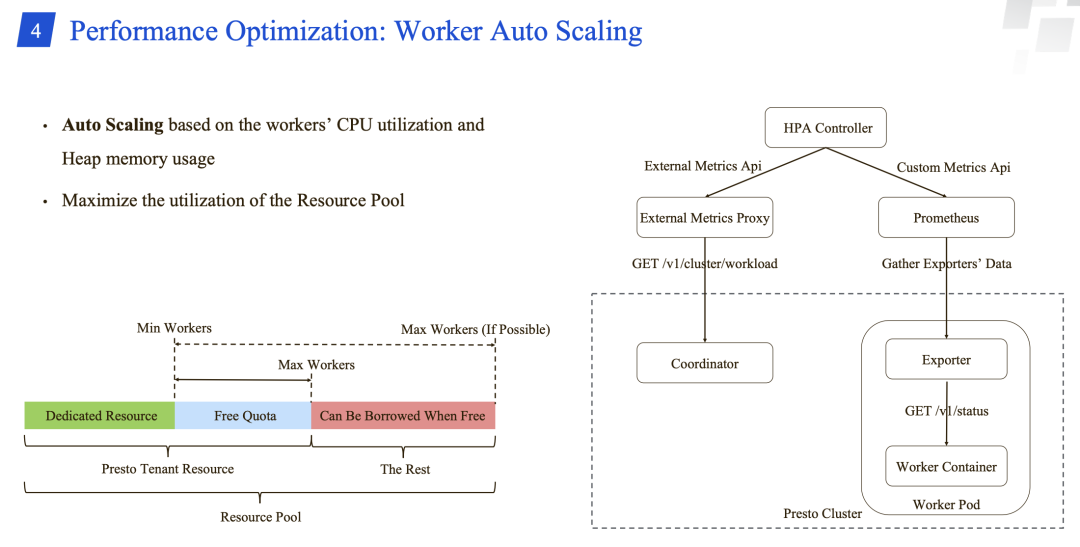
支持通过节点的 CPU 和 内存的使用情况自动扩缩容。

对 distinct Count 查询进行了重写,将其转换成 grouping sets,从而通过部分聚合消除数据倾斜。同样场景下的用户场景性能提升了2-3倍。
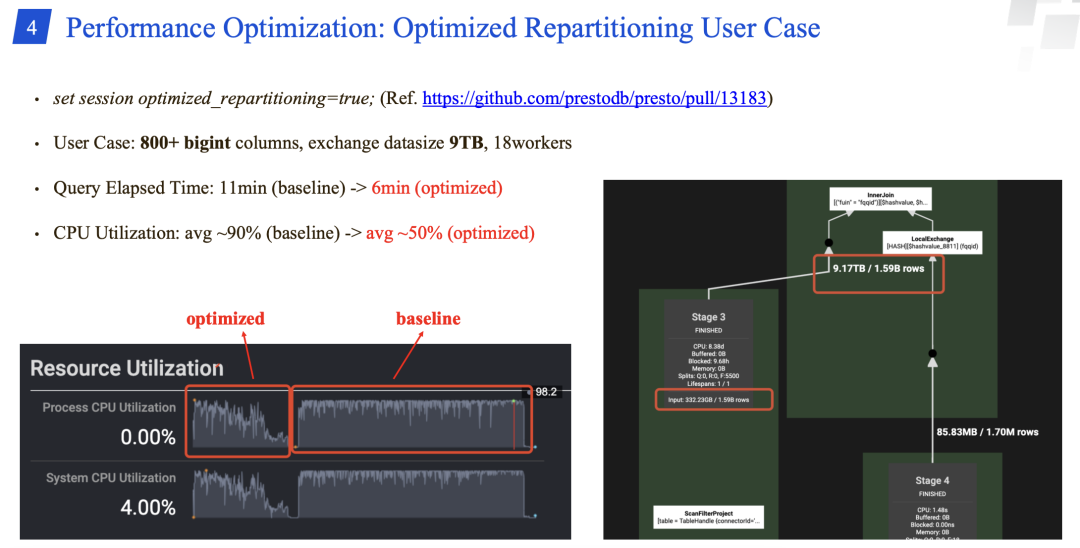
优化重分区的用户场景,性能从11分钟提升到6分钟;CPU 利用率从 90% 降为50%。
未来工作

未来工作主要是支持临时表/视图;Presto 历史服务器的实现;在具有不同硬件资源的机器上进行自适应执行。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Presto 在腾讯的应用】(https://www.iteblog.com/archives/10110.html)







