文章目录
时间过得真快,2021年就过去了,又到了一年总结的时候了。本文将延续之前的惯例来总结一下过去一年大数据相关的项目顺利毕业成 Apache 顶级项目。在2021年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® DataSketches™、Apache® Gobblin™、Apache® DolphinScheduler™ 以及 Apache® Pinot™;同时有两个项目进入到 Apache 孵化器,主要是 Apache Kyuubi 以及 Apache SeaTunnel。值得关注的是,国内主导的 Apache 开源项目越来越多了,这个还是很不错的现象。
关于过去几年毕业成 TLP 的大数据项目可以参见《盘点2017年晋升为Apache TLP的大数据相关项目》、《盘点2018年晋升为Apache TLP的大数据相关项目》 、 《盘点2019年晋升为Apache TLP的大数据相关项目》 以及《盘点2020年晋升为Apache TLP的大数据相关项目》 。下面我们来按照毕业的顺序简单介绍一下这些新晋的 Apache 顶级项目。
Apache® DataSketches™:高性能大数据流算法库
Apache DataSketches 是一个用于可扩展近似算法的高性能大数据分析库。该项目于2012年由雅虎发起,2015年开源,并于2019年3月进入Apache孵化器,2021年02月03日正式毕业成为 Apache 顶级项目。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
在大数据分析中,经常会出现一些不能伸缩的查询问题,因为它们需要大量的计算资源和时间来生成精确的结果。包括 count distinct、分位数(quantiles)、最频繁项(most-frequent items)、joins、矩阵计算(matrix computations)和图分析(graph analysis)。
如果近似结果是可以接受的,那么有一类专门的算法,称为流算法(streaming algorithms),或 sketches,可以更快地产生结果,并具有数学证明的误差界限。对于交互式查询,可能没有其他可行的替代方案,而在实时分析的情况下,sketches 是唯一已知的解决方案。
对于任何需要从大数据中提取有用信息的系统,这些 sketches 都是必需的工具包,应该紧密地集成到它们的分析功能中。这项技术帮助雅虎成功地将其内部平台上的数据处理时间从数天或数小时减少到数分钟或数秒。
Apache DataSketches 具有以下特点:
- 非常快:产生近似结果的速度比传统方法快几个数量级——用户可配置的大小与精度的权衡;
- 高效:sketch 算法可以在同一个进程处理实时和批数据;
- 针对处理大数据的计算环境进行优化,如 Apache Hadoop、Apache Spark、Apache Druid、Apache Hive、Apache Pig、PostgreSQL等;
- 兼容多种语言和平台:Java, C++ 和 Python;
关于 Apache® DataSketches™ 的更多介绍可以到 https://datasketches.apache.org/ 查看。
Apache® Gobblin™:开源分布式大数据集成框架
Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
多年来,LinkedIn 的数据基础架构团队构建了自定义的数据摄取解决方案,用于将不同的数据引入到 Hadoop 生态系统。最终,LinkedIn 运行了 15 种类型的摄取管道,这给数据质量、元数据管理、开发和操作带来了重大挑战。
上面这个问题促使 LinkedIn 构建了 Gobblin。 Gobblin 是一种通用数据摄取框架,用于从各种数据源(例如数据库、REST API、FTP/SFTP 服务器、文件管理器等)中提取、转换和加载大量数据到 Hadoop。Gobblin 处理所有数据摄取 ETL 所需的常见例行任务,包括作业/任务调度、任务分区、错误处理、状态管理、数据质量检查、数据发布等。Gobblin 在同一执行框架中摄取来自不同数据源的数据,并在同一个地方管理不同来源的元数据。 结合其他特性,例如自动扩展、容错性、数据质量保证、可扩展性和处理数据模型演化的能力,使 Gobblin 成为一个易于使用、自我服务且高效的数据摄取框架。
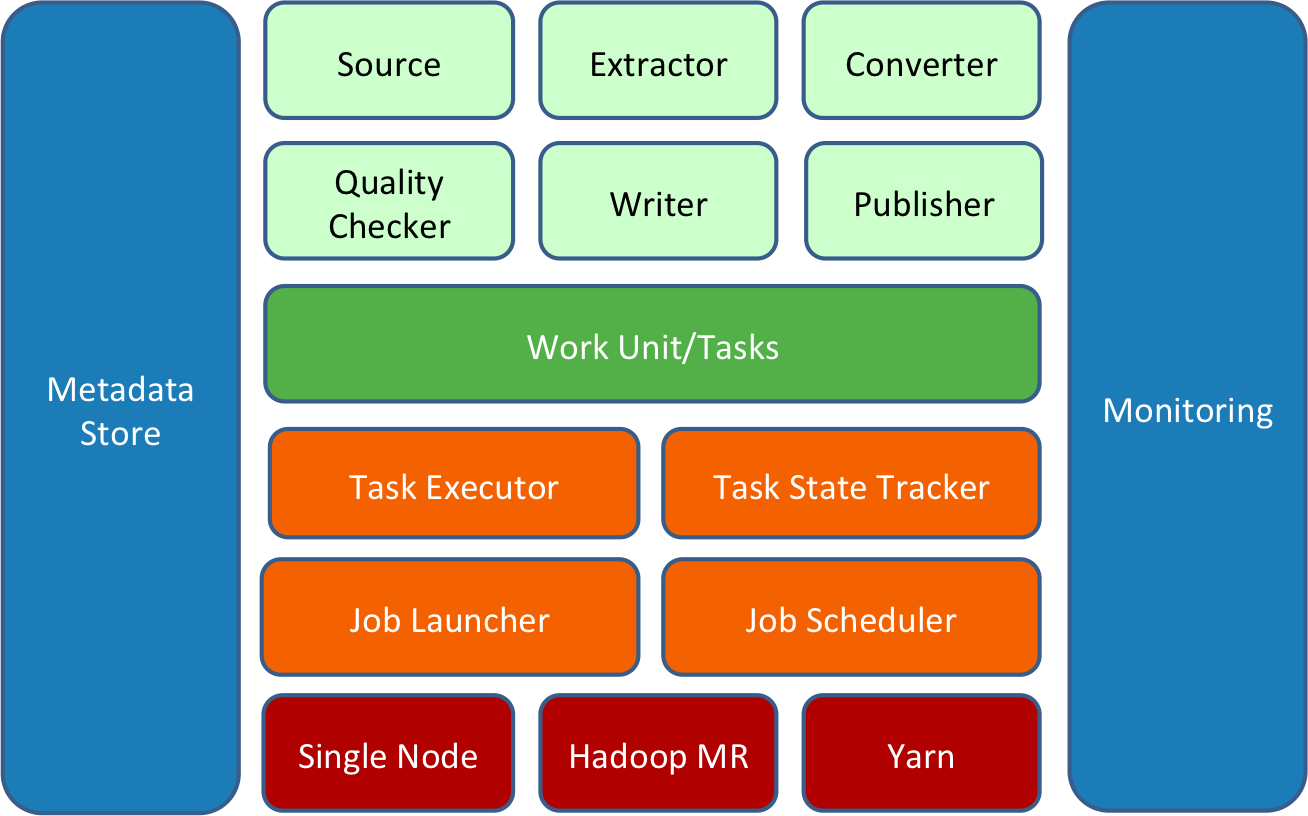
Gobblin 是围绕可扩展性的思想构建的,即用户可以轻松添加新适配器或扩展现有适配器以使用新数据。 Gobblin 的架构体现了这一思想:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Gobblin 作业建立在一组 constructs 上(由上图中的浅绿色框表示),它们以某种方式协同工作并完成数据提取工作。所有的 constructs 都可以通过作业配置插入,并且可以通过添加新的或扩展现有的实现来扩展。
一个 Gobblin 作业由一组任务组成,每个任务对应一个要完成的工作单元,负责提取一部分数据。Gobblin 作业的任务由 Gobblin 运行时(Gobblin runtime)(由上图中的橙色框表示)根据选择的部署设置(由上图中的红色框表示)执行。
Gobblin 运行时(Gobblin runtime)负责在选择的部署设置上运行用户定义的 Gobblin 作业。它处理常见的任务,包括作业和任务调度、错误处理和任务重试、资源协商和管理、状态管理、数据质量检查、数据发布等。
Gobblin 目前支持两种部署模式:单节点的 Standalone 模式和 Hadoop 集群的 Hadoop MapReduce 模式。 当然,这部分还在扩展。
Gobblin 的运行和操作由一些组件和实用程序(由上图中的蓝色框表示)支持,它们处理重要的事情,例如元数据管理、状态管理、指标收集和报告以及监控。
关于 Apache® Gobblin™ 的更多介绍可以到 https://gobblin.apache.org/ 查看。
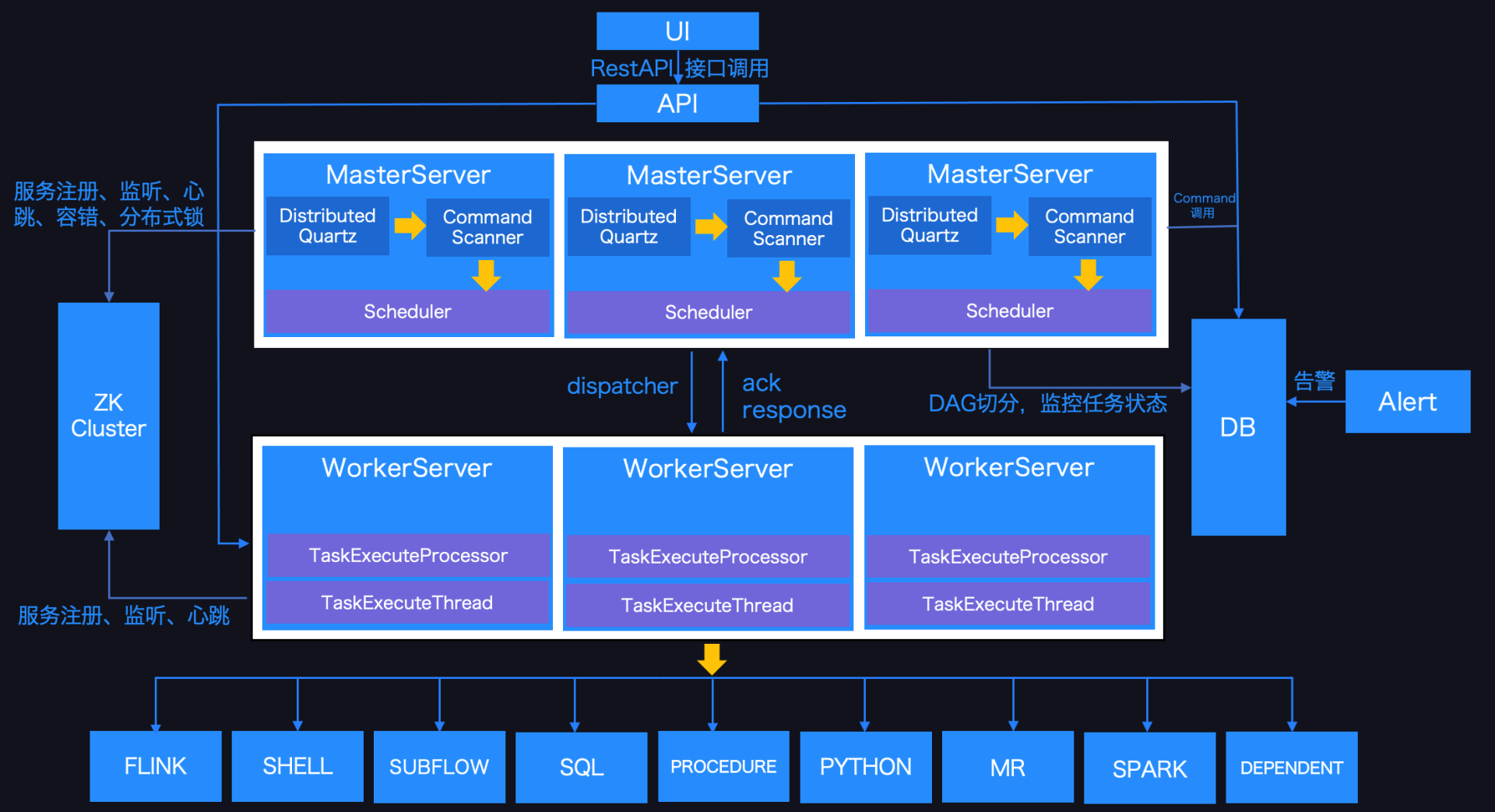
Apache® DolphinScheduler™:开源分布式大数据可视化工作流调度系统
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。该项目最初于 2017 年 12 月在易观创建,并于 2019 年 8 月进入 Apache 孵化器,2021年04月08日正式毕业成为 Apache 顶级项目。
Apache DolphinScheduler 以 DAG 流式的方式将 Task 组装起来,可实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及 Kill 任务等操作。其主要有以下几个特点:
- 高可靠性:去中心化的多 Master 和多 Worker 服务对等架构, 避免单 Master 压力过大,另外采用任务缓冲队列来避免过载
- 简单易用:DAG 监控界面,所有流程定义都是可视化,通过拖拽任务完成定制 DAG,通过 API 方式与第三方系统集成, 一键部署
- 丰富的使用场景:支持多租户,支持暂停恢复操作. 紧密贴合大数据生态,提供 Spark, Hive, M/R, Python, Sub_process, Shell 等近20种任务类型
- 高扩展性:支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master 和 Worker 支持动态上下线
下图是 Apache DolphinScheduler 调度系统架构:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
主要模块介绍如下:
- MasterServer:MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。 MasterServer基于netty提供监听服务。
- WorkerServer: WorkerServer也采用分布式无中心设计理念,支持自定义任务插件,主要负责任务的执行和提供日志服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。
- Registry:注册中心,使用插件化实现,默认支持Zookeeper, 系统中的MasterServer和WorkerServer节点通过注册中心来进行集群管理和容错。另外系统还基于注册中心进行事件监听和分布式锁。
- Alert:提供告警相关功能,仅支持单机服务。支持自定义告警插件。
- API:API接口层,主要负责处理前端UI层的请求。该服务统一提供RESTful api向外部提供请求服务。 接口包括工作流的创建、定义、查询、修改、发布、下线、手工启动、停止、暂停、恢复、从该节点开始执行等等。
- UI:系统的前端页面,提供系统的各种可视化操作界面。
关于 Apache® DolphinScheduler™ 的更多介绍可以到 https://dolphinscheduler.apache.org/ 查看。
Apache® Pinot™:开源分布式实时大数据分析基础设施
Apache Pinot 是一个分布式实时分布式 OLAP 数据存储,旨在以高吞吐量和低延迟提供可扩展的实时分析。该项目最初于 2013 年由 LinkedIn 创建,2015 年开源,于 2018 年 10 月进入 Apache 孵化器,2021年08月02日正式毕业成为 Apache 顶级项目。
Apache Pinot 可以直接从流数据源(例如 Apache Kafka 和 Amazon Kinesis)中提取,并使事件可用于即时查询。它还可以从批处理数据源(例如 Hadoop HDFS、Amazon S3、Azure ADLS 和 Google Cloud Storage)中提取。该系统的核心是列式存储,具有多种智能索引和预聚合技术以实现低延迟。这使得 Pinot 最适合面向用户的实时分析。同时,Pinot 也是其他分析用例的绝佳选择,例如内部仪表板、异常检测和临时数据探索。
Apache Pinot 主要有以下特点:
- 面向列的数据库:具有各种压缩方案,如 Run Length,Fixed Bit Length;
- 可插拔索引技术:支持排序索引(Sorted Index),位图索引(Bitmap Index),倒排索引(Inverted Index,),StarTree 索引,Bloom 过滤器,范围索引(Range Index),文本搜索索引(Lucence/FST), Json 索引,地理空间索引(Geospatial Index );
- 具有基于查询和 segment 元数据优化查询/执行计划的能力;
- 支持从 Kafka、Kinesis 等流系统近实时的摄取数据,也支持从 Hadoop、S3、Azure、GCS 等批处理系统摄取数据;
- 类似 sql 的查询语言,支持对数据进行选择、聚合、过滤、分组、排序和 distinct 查询;(过往记忆大数据备注:Apache Pinot 使用 Presto 实现了 ANSI SQL 查询语言,支持 JOIN 等操作。)
- 支持多值字段
- 支持水平扩展和容错
Pinot 是 LinkedIn 和 Uber 的工程师共同设计的,可以根据集群中的节点数量来扩展查询性能。随着添加更多节点,查询性能总是会根据期望的每秒查询量配额提高。为了在不降低性能的情况下实现无限数量节点和数据存储的水平可伸缩性,Pinot 遵守以下设计原则:
- 高可用性:构建 Pinot 是为了为客户应用程序提供低延迟的分析查询。根据设计,Pinot 没有单点故障。当节点故障时,系统继续提供查询服务。
- 水平可伸缩:在工作负载发生变化时通过添加新节点进行伸缩的能力;
- 延迟 vs 存储:构建 Pinot 是为了在高吞吐量的情况下提供低延迟。为此,开发了段分配策略(segment assignment strategy)、路由策略、星树索引(star-tree indexing)等特性来实现这个功能。
- 不可变数据:Pinot 假设所有存储的数据都是不可变的。对于 GDPR 遵从性,我们提供了一个附加解决方案来清除数据,同时提供性能保证;
- 动态配置更改:必须在不影响查询可用性或性能的情况下执行添加新表、扩展集群、摄取数据、修改索引配置和重新平衡等操作。
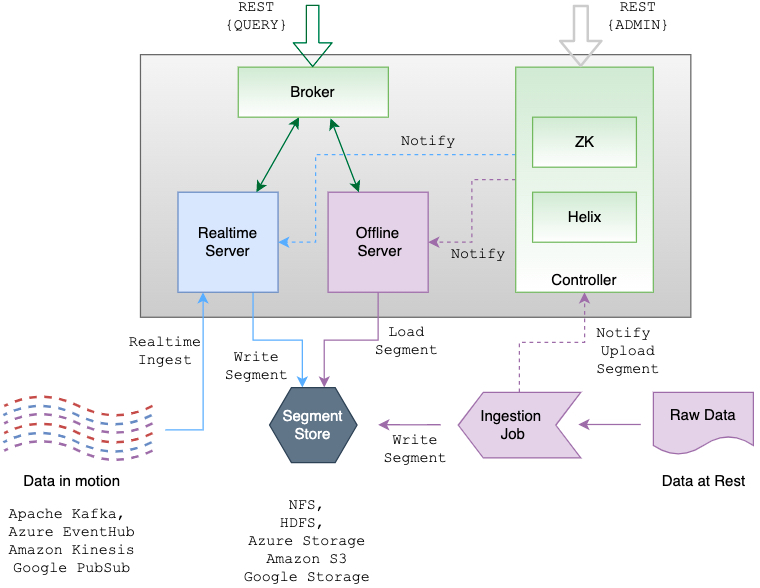
下面是 Apache Pinot 的架构:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
从上图可以看出主要有 Controller, Broker, Server, 以及 Minion 等组件。
Apache Helix && Apache Zookeeper
Pinot 使用 Apache Helix 进行集群管理。Helix 作为代理(agent)嵌入到不同的组件中,并使用 Apache Zookeeper 来协调和维护整个集群状态和运行状况。所有的 Pinot servers 和 brokers 都由 Helix 管理。Helix 是一个通用的集群管理框架,用于管理分布式系统中的分区和副本。可以将 Helix 看作是一个事件驱动的发现服务,它具有推和拉通知功能,可以将集群的状态驱动到理想的配置。
Controller
Pinot 的 Controller 充当集群整体状态和运行状况的驱动程序。由于它的角色是 Helix 的参与者(participant)和旁观者(spectator),它驱动其他组件的状态,所以它通常是在 Zookeeper 之后启动的第一个组件。启动 Controller 需要两个参数:Zookeeper地址和集群名称。如果集群还不存在,Controller 将自动通过 Helix 创建一个集群。
Broker
Broker 的职责是将给定的查询路由到适当的 server 实例。Broker 将收集并合并来自所有 server 的响应,并将其发送回请求客户机。broker 提供接收 SQL 查询并以 JSON 格式返回响应的 HTTP 端点。
Server
Server 管理 segments,并在查询处理期间完成大部分繁重的工作。Pinot 有两种 servers:实时 server 和离线 server,但 server 并不真正知道它将是实时 server 还是离线 server 。server 的职责取决于表分配策略(table assignment strategy)。
Minion
Minion 是一个可选的组件。Minion 用于从 Pinot 集群中清除数据(比如出于英国的 GDPR 遵从性等原因)。
关于 Apache® Pinot™ 的更多介绍可以到 https://pinot.apache.org/ 查看。
Apache kyuubi:分布式多租户的 Thrift JDBC/ODBC 服务器(孵化中)
Apache Kyuubi 是一个分布式多租户的 Thrift JDBC/ODBC 服务器,用于大规模数据管理、处理和分析,其构建在 Apache Spark 之上,并且设计支持更多的引擎(比如 Apache Flink)。由网易在2018年开源,并于2021年06月21日进入 Apache 孵化器。
Kyuubi 主要应用在大数据领域场景,包括大数据离线计算、数据仓库、Ad Hoc等方向。Kyuubi 提供了以下几个功能:
- 多租户:Kyuubi 支持端到端的多租户,这就是为什么尽管已经存 在Spark Thrift JDBC/ODBC 服务器,网易还是要创建这个项目。
- 简单易用:您只需熟悉 SQL 和JDBC 即可处理海量数据,Kyuubi 帮助您专注于业务系统的设计和实现。
- 到处运行:Kyuubi 可以向所有支持的集群管理器提交 Spark 应用程序,包括 YARN、Mesos、Kubernetes、Standalone 和 local。
- 安全和认证:通过强大的身份验证和细粒度的列/行级授权,Kyuubi 可以确保系统和数据的安全。
- 高可用:是企业级SQL引擎的基本特性。Spark Thrift Server不具备这种能力;而Kyuubi提供了基于ZooKeeper的高可用解决方案,以支持高可用特性;
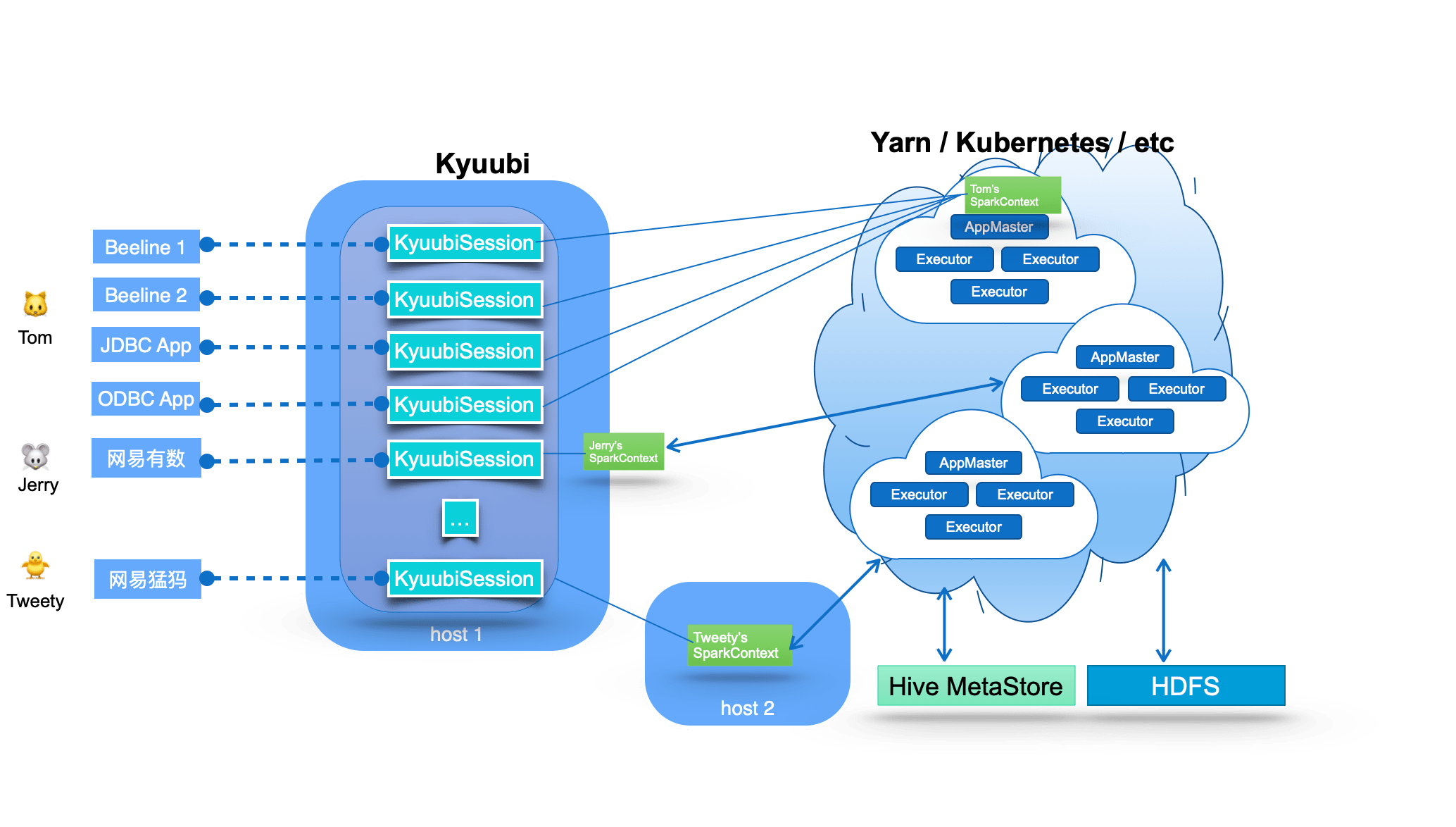
Apache Kyuubi 的系统架构如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
图的中间部分显示了 Kyuubi 服务器的主组件,该组件处理图中左侧所示的客户端连接和执行请求。在 Kyuubi 中,这些连接请求被维护为 Kyuubi 会话,执行请求被支持为 Kyuubi 操作,这些操作被绑定到相应的会话。
Kyuubi Session 的创建可以分为两种情况:轻量级和重量级。大多数会话创建都是轻量级的,用户不感知。唯一的重量级情况是,在用户的共享域中没有实例化或缓存 SparkContext,这通常发生在用户第一次连接或很长时间没有连接时。这种一次性成本会话维护模型可以满足大多数特别的快速响应需求。
Kyuubi 以松散耦合的方式维护 SparkConext 的连接。这些 SparkContexts 可以是通过这个服务实例在客户端部署模式下本地创建的 Spark 程序,也可以是在 Yarn 或 Kubernetes 集群中以集群部署模式创建的 Spark 程序。在高可用模式下,这些 SparkConext 也可以由不同机器上的其他 Kyuubi 实例创建,并由该实例共享。
这些 SparkConexts 实例本质上是由 Kyuubi 服务托管的远程查询执行引擎程序。这些程序在 Spark SQL 上实现,端到端编译、优化和执行SQL语句,并与元数据服务(如Hive Metastore)和存储服务(如 HDFS)进行必要的交互,最大限度地发挥 Spark SQL 的功能。它们可以管理自己的生命周期,并且不受 Kyuubi 服务器上的故障转移的影响。
关于 Apache® Kyuubi™ 的更多介绍可以到 https://kyuubi.apache.org/ 查看。
Apache SeaTunnel:高性能、分布式、海量数据集成框架(孵化中)
Apache SeaTunnel (原名 Waterdrop)是一个非常易于使用的超高性能分布式数据集成平台,支持实时流式和离线批处理的海量数据处理,架构于 Apache Spark 和 Apache Flink 之上。由 Interesting Lab 于 2018年开源,并于2021年12月09日进入 Apache 孵化器。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
通过 Apache SeaTunnel 可以让 Spark 的使用更简单、更高效,并巩固了行业的高质量经验,并将业界和 Interesting Lab 使用 Spark 的优质经验固化到SeaTunnel 这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地。Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。Interesting Lab 在使用 Spark 时发现了很多可圈可点之处。除了大大简化分布式数据处理难度外,seatunnel 尽所能为您解决可能遇到的问题:
- 数据丢失与重复
- 任务堆积与延迟
- 吞吐量低
- 应用到生产环境周期长
- 缺少应用运行状态监控
Apache SeaTunnel 的特性:
- 简单易用,灵活配置,无需开发
- 实时流式处理
- 高性能
- 海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用SQL做数据处理和聚合
- Spark Structured Streaming
- 支持Spark 2.x
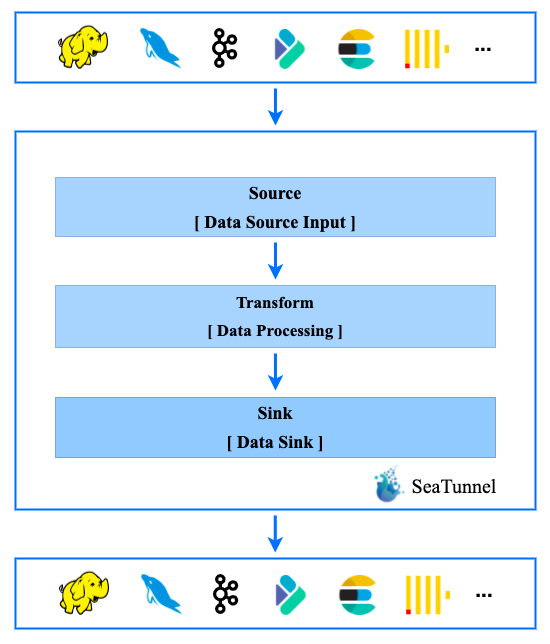
Apache SeaTunnel 的工作流程如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
关于 Apache® SeaTunnel™ 的更多介绍可以到 https://seatunnel.apache.org/ 查看。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【盘点2021年晋升为Apache TLP的大数据相关项目】(https://www.iteblog.com/archives/10122.html)