

和其他计算引擎一样,一条 SQL 从客户的提交到 Coordinator 端经过 SqlParser 进行词法和语法解析形成 AST 树,然后经过 Analyzer 进行语义分析,生成了逻辑计划(LogicalPlan);接着经过优化器处理(优化规则都是在 PlanOptimizers 里面定义好的,然后在 LogicalPlanner 里面循环遍历每个规则)生成物理计划(PhysicalPlan);最后使用 PlanFragmenter 并根据物理计划树里面的信息生成 SubPlan,SubPlan 其实也是嵌套关系的,里面记录了 SQL 的执行需要经过的阶段。本文将介绍 Presto 中逻辑计划树到物理计划树之间的转换。
为了方便下面的介绍,本文将使用下面的 SQL 查询为例进行说明:
select l_suppkey, count(l_orderkey) from lineitem where l_receiptdate > '1995-10-07' group by l_suppkey order by l_suppkey
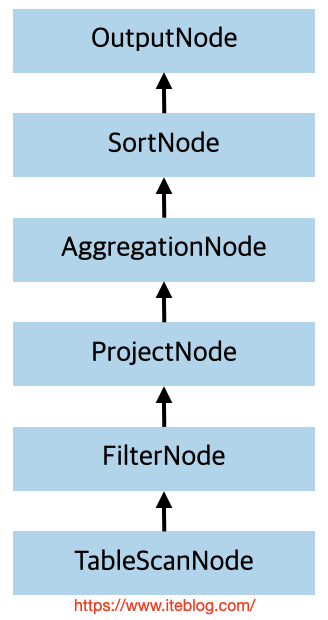
其逻辑计划树如下所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
上面逻辑计划树是从上往下看的,程序最先拿到的是 OutputNode,然后再是 SortNode 等。这个逻辑计划树虽然可以看到各个节点之间的关系,但是我们不知道如何去分布式执行。比如各个节点之间的数据传输需不需要进行 Shuffle,如果需要 Shuffle 是用 ROUND_ROBIN 还是 HASH 等分区策略?到目前为止,我们是完全不知道的。所以我们需要进一步处理这个执行计划树,使得它变成物理计划树。
在 Presto 里面逻辑计划树和物理计划树都是使用 PlanNode 表示,从逻辑计划树到物理计划树的转换是通过 Presto 里面名为 AddExchanges 类去处理的。从实现上来看,AddExchanges 和其他优化规则一样,也是实现了 PlanOptimizer 接口,所有修改计划树的逻辑都在 Rewriter 里面。
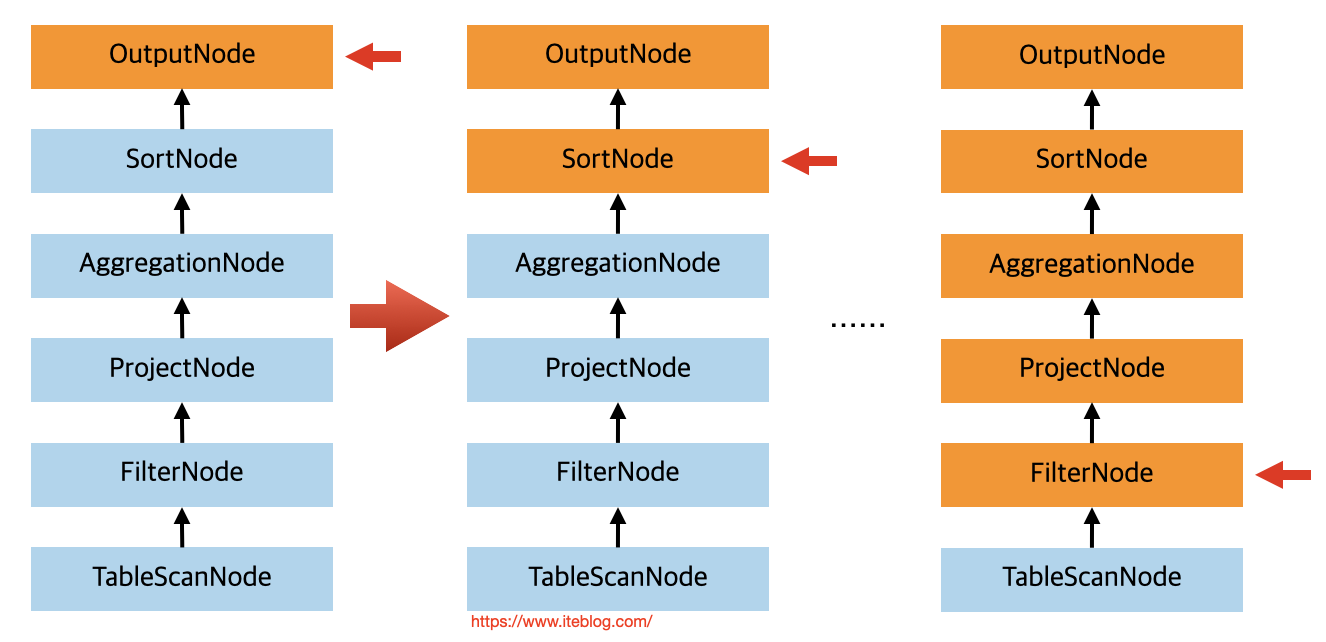
在 Rewriter 里面,会先访问到逻辑计划树的顶层节点,在我们这个例子中其实就是 OutPutNode,所以程序其实会进入到 Rewriter 类里面的 visitOutput 方法里面。因为 OutPutNode 可能还有子节点,所以在处理 OutPutNode 之前需要先处理好子节点,也就是本例子中的 SortNode 节点,这时候程序会进入到 visitSort 处理访问里面。在处理 SortNode 的时候也是需要先处理好子节点,其他节点处理也是大概按照这个逻辑处理的,也就是处理本节点之前先处理子节点,这样程序会一直处理到 FilterNode 节点,执行流程如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
图中橙色的节点代表程序访问过的,当处理到 FilterNode 节点的时候,因为其子节点是 TableScanNode ,而 TableScanNode 已经没有子节点,所以直接处理一下 TableScanNode 就行。在处理 TableScanNode 节点的时候,会调用 com.facebook.presto.sql.planner.iterative.rule.PickTableLayout#pushPredicateIntoTableScan 方法把 Predicate 下推到 TableScanNode 里面去。接着根据 TableScanNode 里面的 currentConstraint 信息构造出一个 ActualProperties 对象,ActualProperties 里面存储着数据在节点之间的分区信息(nodePartitioning)以及数据在 splits 之间传递的分区信息(streamPartitioning)等。由于我们这里的 currentConstraint 是 TupleDomain{ALL},相当于没有,所以构造出来的 ActualProperties 其实里面都是默认值,也就是 nodePartitioning 和 streamPartitioning 都是 Optional.empty。
接着利用 TableScanNode 的 ActualProperties 和 FilterNode 的 predicate 构造 FilterNode 的 ActualProperties 信息,这个例子中构造出来的也是默认值。最后程序一路往返回,FilterNode 的父节点是 ProjectNode,其构造出来的 ActualProperties 也是默认值;紧接着依次返回处理 ProjectNode 的父节点,也就是 AggregationNode 节点。
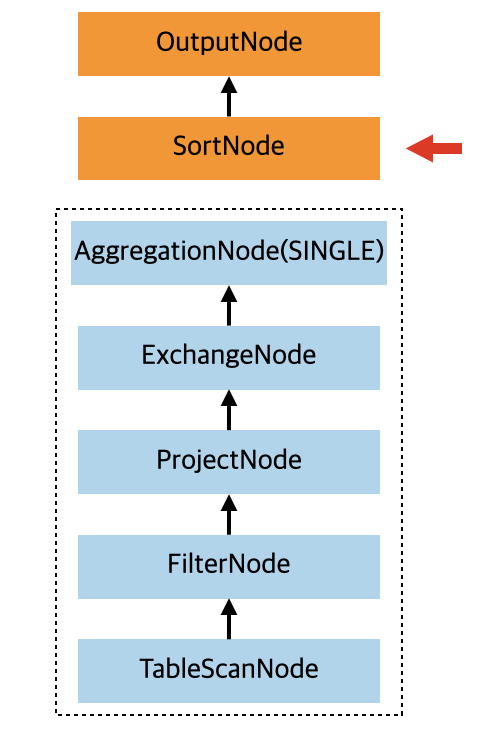
在 AggregationNode 节点里面会根据是否有 group by 字段添加对应分区信息的 ExchangeNode。在我们这个例子中,由于存在 group by 信息,这就意味着我们需要按照 group by 里面的列把数据从上游 stage hash 到下游的 stage。所以处理完 AggregationNode 的时候,返回到 SortNode 的 child Node 如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
上图中虚线框里面的节点信息是在处理 SortNode 过程中返回的 child Node 信息,可见,相比之前的原始执行计划树,在 AggregationNode 和 ProjectNode 节点之间增加了 ExchangeNode。由于数据需要经过 shuffle,所以 ExchangeNode 的 type 是 REPARTITION,意味着执行分区操作,分区的处理函数是 HASH。
注意,如果我们的 SQL 是 select count(l_orderkey) from lineitem where l_receiptdate > '1995-10-07',那么也会在 在 AggregationNode 和 ProjectNode 节点之间添加 ExchangeNode 节点,但是这个 SQL 其实是不需要把数据 shuffle 到下游,而是直接收集各个 worker 处理的部分 count 结果,所以 ExchangeNode 的 type 是 GATHER,分区处理函数是 SINGLE。
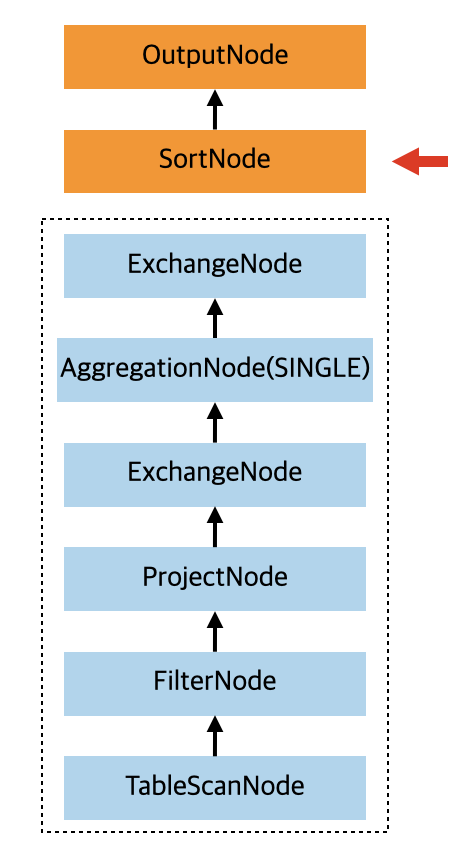
在处理 SortNode 的时候,还会在 AggregationNode 之前再插入一个 ExchangeNode,主要是用来解决数据倾斜的问题,如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
因为是用来解决数据倾斜的,这个 ExchangeNode 的 type 也是 REPARTITION,这不过这次的分区函数为 ROUND_ROBIN。最后处理完 SortNode 的时候,会把上面返回的执行计划树当做 SortNode 的 source 节点,也就是子节点。并且还会在 SortNode 前面再加上一个 ExchangeNode,type 为 GATHER,也就是把数据收集到下游,分区处理函数是 SINGLE,也就是下游只有一个 worker 来处理数据。也就是处理完 SortNode(visitSort) 节点之后,返回到 visitOutput 的 child 执行计划树如下所示:
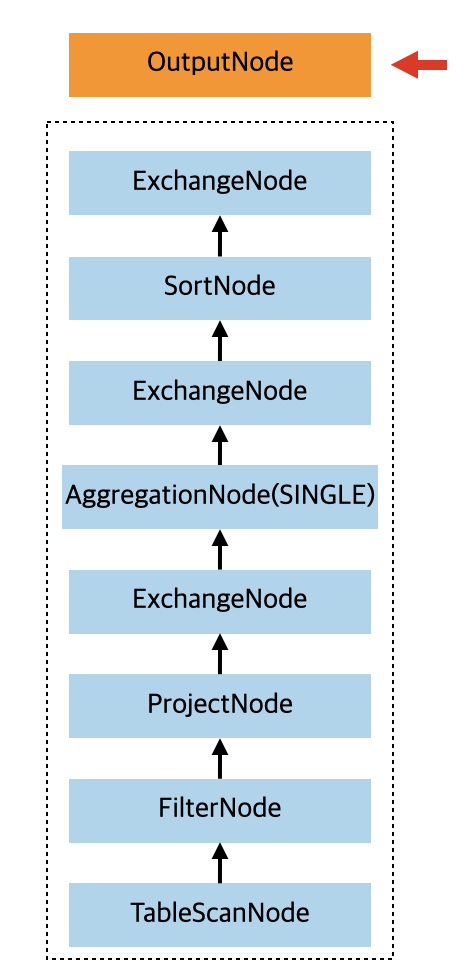
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
当处理完 visitOutput 之后,经过 AddExchanges 处理之后,整个执行计划树变成如下的形式了:
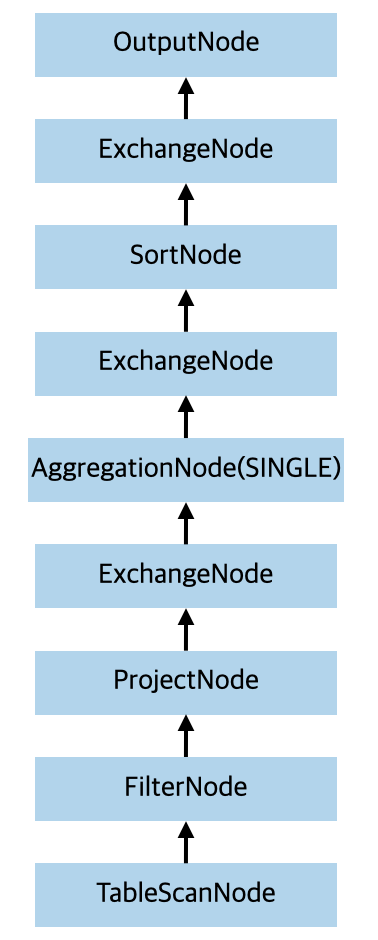
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
到这里,逻辑计划树变成了物理计划树了,其实就是在需要经过网络传递数据的 stage 之间加了不同类型的 ExchangeNode。
从图中可以看出,经过 AddExchanges 处理之后,AggregationNode 节点只有一个,并且 step 是 SINGLE,但最后划分 Fragment 的时候其实 AggregationNode 有两个,step 分别是 PARTIAL 和 FINAL,也就是对应部分聚合结果和最终的结合结果。这个其实是在 AddExchanges 处理之后再经过 PushPartialAggregationThroughExchange 优化规则处理的。最后变成的物理计划树如下(里面其实还删了部分 scope 为 LOCAL 的 ExchangeNode ):
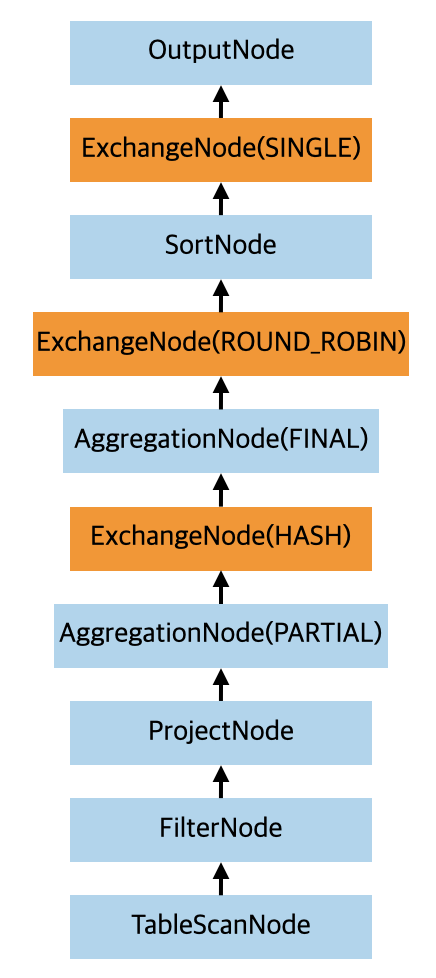
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
有了物理计划树之后,到了 PlanFragmenter 里面只会,会根据 scope 为 REMOTE_STREAMING 的 ExchangeNode 节点创建 SubPlan,我们上面的例子最后生成了四个 Stage,如下:
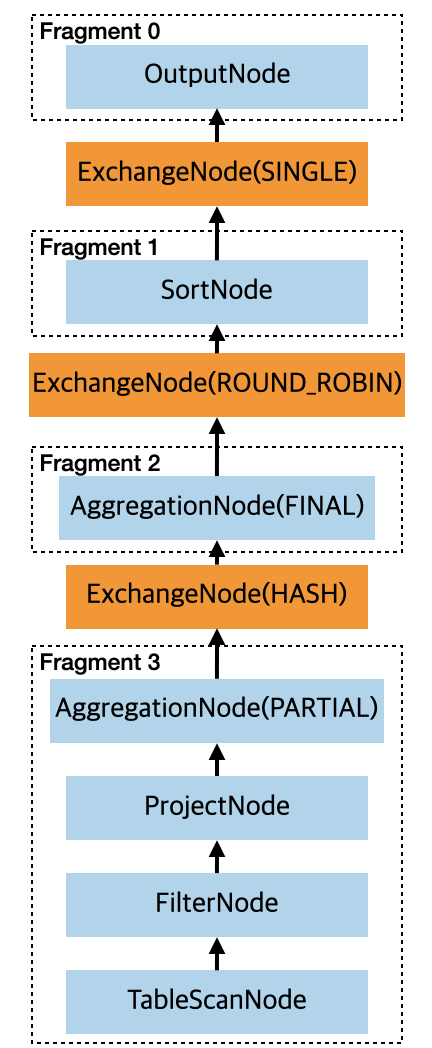
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
我们可以通过 explain (type distributed) 来查看详细的执行计划,其实就是上图的结果:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【图文介绍 Presto 如何从逻辑计划树到物理计划树】(https://www.iteblog.com/archives/9982.html)







