在前面(《Flink on YARN部署快速入门指南》的文章中我们简单地介绍了如何在YARN上提交和运行Flink作业,本文将简要地介绍Flink是如何与YARN进行交互的。
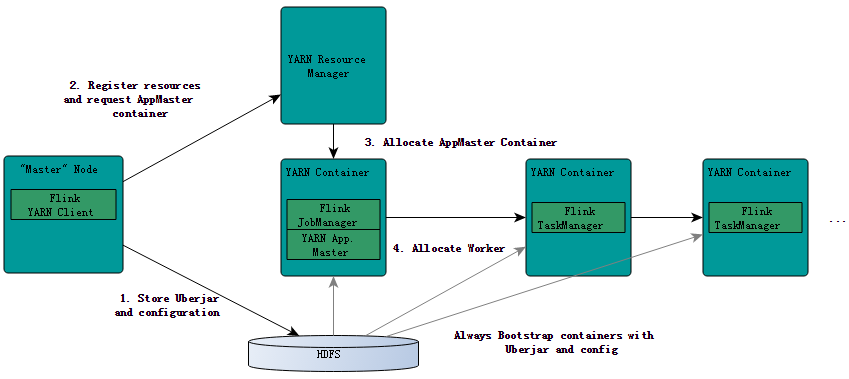
YRAN客户端需要访问Hadoop的相关配置文件,从而可以连接YARN资源管理器和HDFS。它使用下面的规则来决定Hadoop配置:
1、判断YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH等环境变量是否设置了(按照这些变量的顺序判断)。如果它们中有一个被设置了,那么就会读取其中的配置。
2、如果上面的规则失败了(如果正确安装了 YARN 的话,这不应该会发生),那么客户端将会使用HADOOP_HOME环境变量。如果这个环境变量设置了,客户端将会尝试访问$HADOOP_HOME/etc/hadoop(Hadoop 2)或者$HADOOP_HOME/conf (Hadoop 1)路径下文件。
当启动一个新的Flink YARN session,客户端首先判断所请求的资源(容器和内存)是否可用。在那之后,它会把包含了Flink以及相关配置的jar包上传到HDFS(步骤1)。
客户端的下一步是请求(步骤 2)一个 YARN 容器来启动ApplicationMaster(步骤 3)。因为客户端已经将配置和jar文件作为资源向容器注册了,所以运行在特定机器上的NodeManager 会负责准备容器(例如,下载一些文件),一旦上面的步骤完成了,ApplicationMaster (AM)将会被启动。
JobManager和AM是运行在同一个容器中的,一旦它们成功地启动了,AM就会知道JobManager 的地址(就是它自己的地址),它会为TaskManager 生成一个新的Flink配置文件(这样TaskManager才能连上 JobManager)。这些新的配置文件同样会被上传到HDFS上。此外,AM将负责为Flink提供WEB界面服务,Flink 用来提供服务的端口是由用户 + 应用程序 id 作为偏移配置决定的。这样的措施使得用户能够并行地执行多个 Flink YARN session。
在那之后,AM开始为Flink的TaskManager 分配容器,这会从HDFS下载jar文件和修改过的配置文件。一旦这些步骤完成了,Flink服务就在YARN上启动完成并准备接受任务了。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Flink是如何与YARN进行交互的】(https://www.iteblog.com/archives/1622.html)