
据估计,到2017年底,90%的CPU cycles 将会致力于移动硬件,移动计算正在迅速上升到主导地位。Spark为此重新设计了Spark体系结构,允许Spark在移动设备上运行Spark。
Spark为现代化数据中心和大数据应用进行设计和优化,但是它目前不适合移动计算。在过去的几个月中,Spark社区正在调研第一个可以在移动设备上运行架构的可行性,这篇文章将会和大家分享Spark社区的研究结果。


如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
这个结构设计需要满足以下条件:
该系统必须支持
(1)、支持在Android和iOS上运行Spark;
(2)、便利SoLoMo (social, local, mobile) 应用程序的发展;
(3)、保持源代码的向后兼容性
(4)、在一个Spark集群上兼容不同的手机设备。
最好支持
(1)、支持在Windows phones上运行Spark;
(2)、通过J2ME支持其他功能手机。
编译和运行
目前Android Runtime (ART) 目前支持用Scala编写的应用程序,可以看这篇文章Scala IDE article on Android development。
然而,iOS内置并不支持JVM,但是幸运的是,经过多个社区的共同努力,支持运行Java程序:
(1)、使用RoboVM,一个预先编译器(ahead-of-time (AOT) compiler)和库,使得我们可以使用Java编写iOS应用程序l;
(2)、使用Scala和LLVM来编译Spark 的Scala代码,最终会变成LLVM字节码。鉴于Apple公司对LLVM项目的强烈支持,我们相信这个可以达到很高的性能;
(3)、而且Swift语言和Scala语言很类似,所以我们绝对可以将Scala语言编写的项目转换成Swift语言,然后使用XCode来编译项目;
(4)、使用 Scala.js将Spark代码编译成JavaScript(可以参照这里http://www.scala-js.org/),然后使得我们可以在支持JavaScript引擎的软件(比如Safari)上运行Spark。
以上四个选项,应该首选第四个,因为他不仅支持iOS系统,而且还会支持其他的系统。所以我们可以在iOS和Android系统上使用JavaScript引擎来运行Spark程序,在服务器上,Spark可以在Node.js上运行。
性能优化
JavaScript引擎是最具有创造性的领域之一,所以我们完全有理由相信,JavaScript引擎可以迅速地提高自己的表现性能。然而,移动设备上的JavaScript引擎看起来比台式机上的要落后,比如,移动设备上的JavaScript引擎不支持SIMD。我们可以将Spark对SIMD依赖的部分,我们可以进行选择性的重写,然后产生LLVM字节码。
网络和线协议
Spark的网络传输是基于Netty的,而这个又依赖于 java.nio或者Linux epoll。虽然Android ART 内置就支持java.nio,但是我们需要重写Netty,使得我们可以在iOS上使用kqueue。除此之外,目前社区还不清楚是否低级别的网络原语(比如zero-copy)是否可以在JavaScript中使用,我们需要更密切地与苹果和谷歌合作,以改善JavaScript对移动网络的更好支持。
一个可行的选择是使用grpc(它是Google开发的开源高性能RPC库),grpc内置就支持在所有通用平台上(Java, Objective C等等)使用HTTP/2。
在调试方面,JSON应该是超过任何现有的二进制格式的首选线串行协议。
真正的本地调度和DAGScheduler
为了更好地支持Spark的 local,social和mobile特性,社区将RDD本地性域用GPS坐标代替。本地调度可重构来真正的支持本地性,这是在服务器上永远与不可能实现的。
为了保证源码的兼容性,社区保留了旧的接口,并引入了新的本地性接口:
class RDD {
@deprecate(“2.0”, “use getPreferredTrueLocations”)
def getPreferredLocations(p: Partition): Seq[String]
/**
* Returns the preferred locations for executing task on partition
* `p`. Concrete implementations of RDD can use this to enable
* locality scheduling.
*/
def getPreferredTrueLocations(p: Partition): Seq[LatLong]
}
为移动平台扩展TaskContext
TaskContext为Spark tasks提供了上下文信息(比如 job IDs, attempt IDs),这些在服务器上运行的Job就已经足够了。但是在移动设备上,还有其他的信息,比如GPS位置,ongoing calls等,这些上下文信息对优化taks的处理很有用,而且不会影响到 smartphone/tablet用户的用户体验。比如来了一个电话,一个新的task可能会被暂停,直到这个电话结束,这样用户的通话质量就不会受到影响。
iPhone和Android的基本引擎
社区已经使用iPhone创建了几个proof-of-concepts,来更好地了解手机平台的复杂性。下面就是原型的截图。
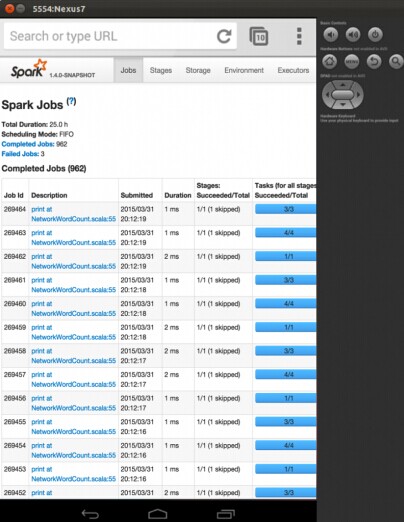
本文开头的截图显示了在iPhone上运行 Spark Streaming NetworkWordCount 实例。它使用sockets来从运行在Amazon EC2上的服务器上接收数据。同样地,我们也在Android上运行这个实例,下面就是在Android模拟器上运行的截图:
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Spark 2.0:将支持在手机设备上运行Spark】(https://www.iteblog.com/archives/1316.html)







