

文章目录
前言
Facebook 的数据仓库构建在 HDFS 集群之上。在很早之前,为了能够方便分析存储在 Hadoop 上的数据,Facebook 开发了 Hive 系统,使得科学家和分析师可以使用 SQL 来方便的进行数据分析,但是 Hive 使用的是 MapReduce 作为底层的计算框架,随着数据分析的场景和数据量越来越大,Hive 的分析速度越来越慢,可能得花费数小时才能完成。而且 Facebook 也尝试使用外部的一些项目,但是都无法满足自己的需求,基于这些情况,Facebook 从 2012 年秋季开始开发一个新的计算引擎,这也就是我们熟悉的 Presto。
Presto 的核心目标就是提供交互式查询,也就是我们常说的 Ad-Hoc Query,很多公司都使用它作为 OLAP 计算引擎。但是随着近年来业务场景越来越复杂,除了交互式查询场景,很多公司也需要批处理;但是 Presto 作为一个 MPP 计算引擎,将一个 MPP 体系结构的数据库来处理海量数据集的批处理是一个非常困难的问题,所以一种比较常见的做法是前端写一个适配器,对 SQL 进行预先处理,如果是一个即时查询就走 Presto,否则走 Spark。这么处理可以在一定程度解决我们的文档,但是两个计算引擎以及加上前面的一些 SQL 预处理大大加大我们系统的复杂度。
Presto Unlimited
在 Facebook,超过80%的新增批处理工作负载是在 Presto 上运行的。然而,内存密集型(memory-intensive )和长时间运行(long-running queries)的查询是 Presto 用户的主要痛点。我们很难判断查询将使用多少内存以及何时会达到内存限制,长时间运行的查询失败会导致重试,这会造成更严重的问题。为了解决 Presto 同时能够处理即时查询和复杂 ETL ,Facebook 开发了代号为 Presto Unlimited 的项目。Presto Unlimited 的设计目标是为了解决可伸缩性的挑战,使得一套 Presto 系统既可以处理即时查询,也可以处理复杂的 ETL 查询。
Grouped Execution
为了解决内存密集型查询,Facebook 引入了 Grouped Execution, Grouped Execution 利用 table partitioning 来进一步提升查询性能。假设我们有以下查询,customer 和 orders 两张表都已经在 custkey 字段进行分桶(bucketed)。
SELECT ... FROM customer JOIN orders USING custkey
如果没有 Grouped Execution,Presto 会对 orders (build side)表的所有数据构建 hash 表,如下:
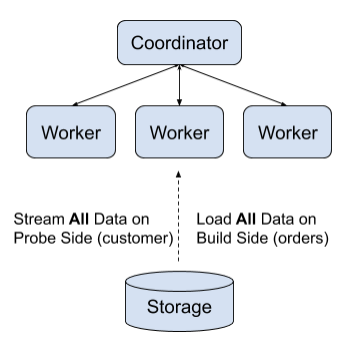
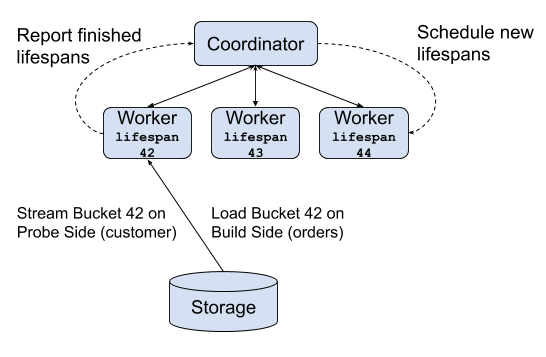
但是,我们知道,customer 和 orders 表已经对 custkey 字段进行分桶,Presto 可以以一种更智能的方式来执行查询,以减少峰值内存消耗:customer 和 orders 表的每个分桶 i 都是可以独立完成的。在 Presto 引擎中,这个计算单元称为 “lifespan”:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Grouped execution 特性已经在 Facebook 的生产环境使用了超过一年,支持需要几十TB分布式内存的查询。
Exchange Materialization
Grouped Execution 对已经分桶的表有很好的表现,但是如果我们的表不是分桶的,性能一样很糟糕。为了使 Grouped Execution 能够处理非分桶表,我们可以通过将数据写入中间带 bucket 的临时表来解决这个问题,这个就是 Exchange Materialization。比如下面是没有使用 Grouped Execution 的进行 join 的计划:
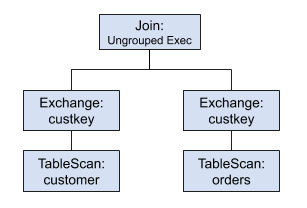
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
如果数据量很大,上面效率是很低的。有了 Exchange Materialization 功能,我们对原表先进行分桶,并写入到临时表,最后就可以基于这些临时表并使用 Grouped Execution 来解决内存密集型的查询。我们把 ExchangeNode 替换成 TableWriterNode/TableFinishNode 和 TableScanNode,最新的查询计划如下:
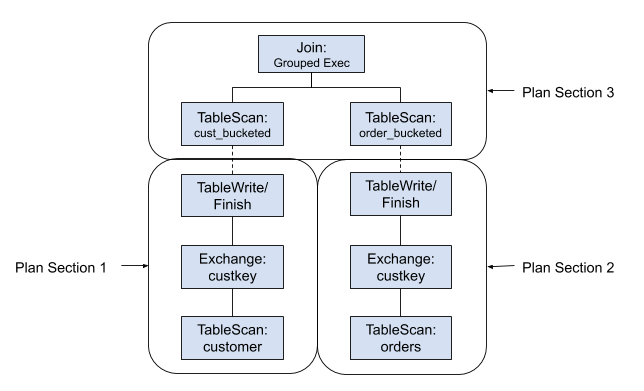
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Recoverable Grouped Execution
为了解决长时间运行的查询,需要支持 Recoverable Grouped Execution,这个就可以支持部分查询失败的恢复。因为每个 lifespan 都是独立的,所以重试的时候只需要计算这部分即可。
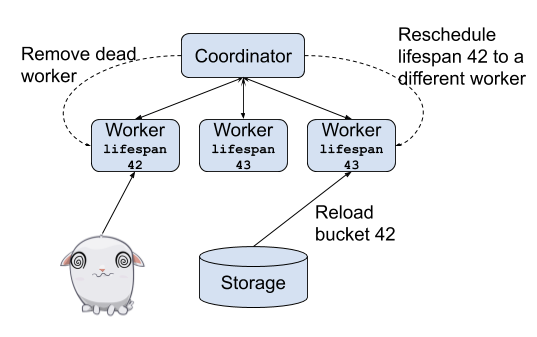
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Presto on Spark
为了让 Presto 真正的适应任何大规模批处理工作负载,必须满足以下几个要求:
- 可扩展的 shuffle:这要求我们实现类似于 MapReduce 的 shuffle,当然也可以集成 Cosco。
- 可扩展的 Presto worker 执行引擎:这个包括资源隔离(resource isolation),straggler detection、推测执行( speculative execution)等。
- 可扩展的资源管理系统:需要支持细粒度的资源管理(fine grained resource management)。MapReduce 中这个就是我们熟悉的 Mapper/Reducer,Spark 就是 Executor。
如果直接通过修改 Presto 来支持任何大规模批处理工作负载,挑战可想而知。所以,社区考虑基于 Spark 来实现这个需求。架构设计如下:
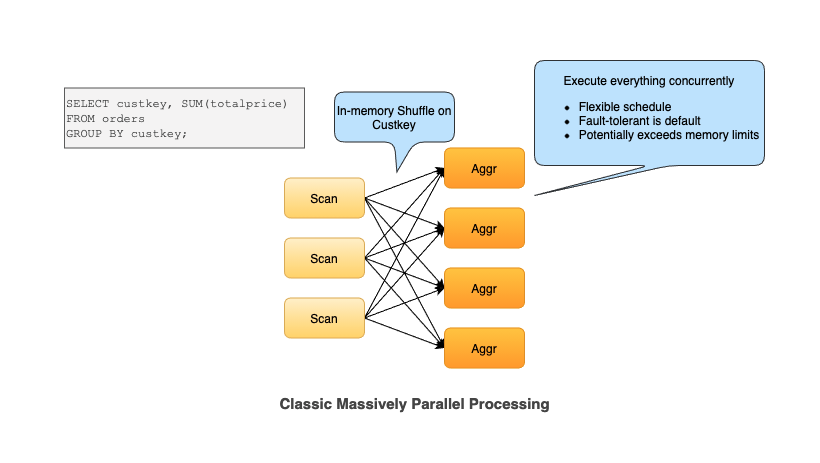
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Presto on Spark 被设计成一个独立的二进制包,通过 spark-submit 来提交作业,presto-main、presto-spi 以及其他 Presto modules 将作为类库(libraries)的形式来使用。下面是一个 Presto on Spark 作业的例子:
spark-submit -- \
--class com.facebook.presto.spark.launcher.PrestoFacebookSparkLauncher \
/presto/presto-spark-launcher/target/presto-spark-launcher-0.230-SNAPSHOT-shaded.jar \
--package /presto/presto-spark-package/target/presto-spark-package-0.230-SNAPSHOT.tar.gz \
--config /etc/config.properties \
--catalogs /etc/catalogs \
--file query.sql
以 MR 的方式执行 ETL
通过 Presto Unlimited,Presto 会以类似于 MapReduce 的形式来运行大型 ETL 查询,比如我们有以下的查询:
SELECT custkey, SUM(totalprice) FROM orders GROUP BY custkey
在 Presto Unlimited 之前,执行计划如下:
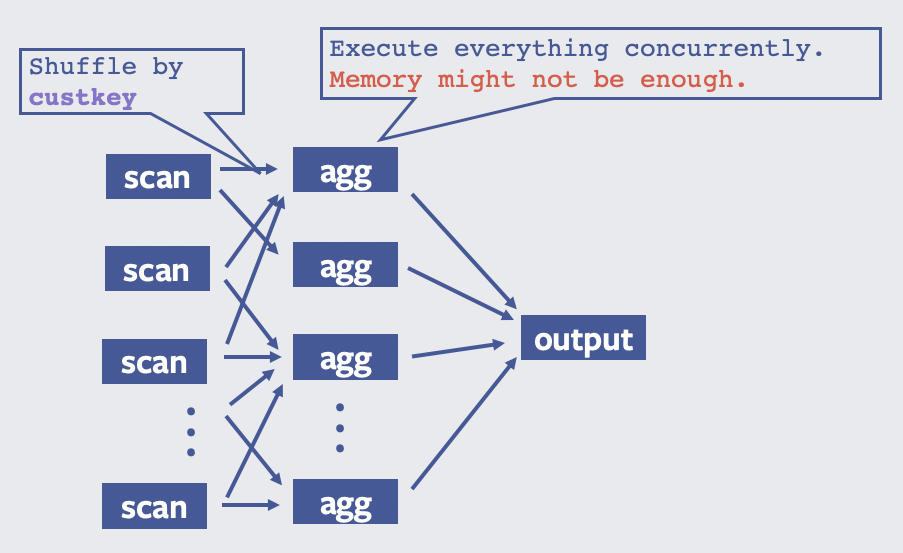
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
在 Presto Unlimited 之后,执行计划如下:
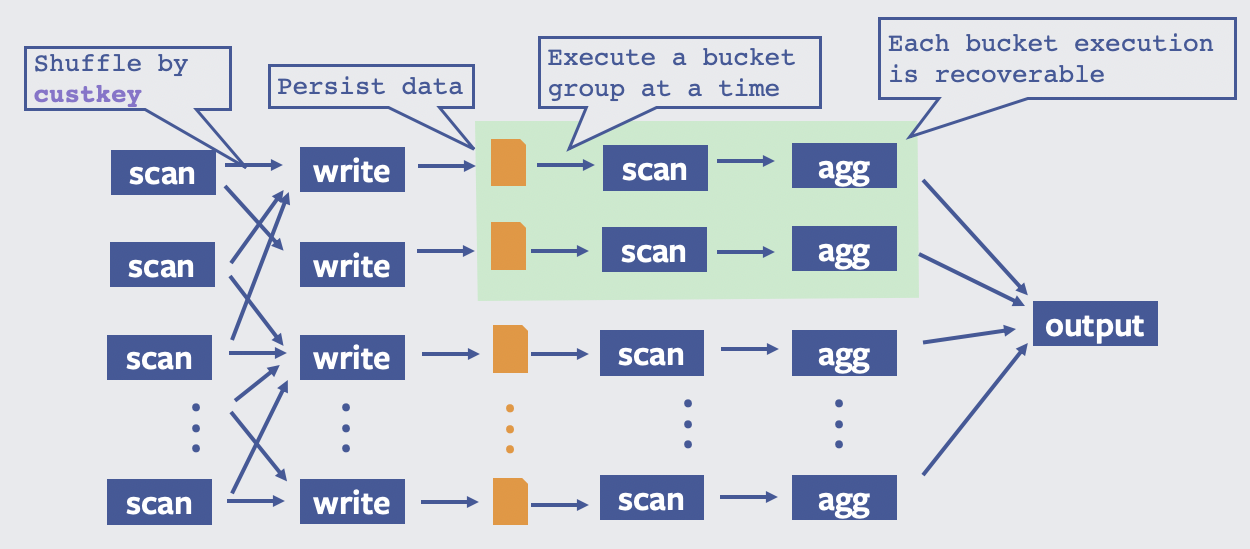
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
本文参考:
Presto Unlimited: MPP SQL Engine at Scale
Presto-on-Spark Design
[Design] Presto-on-Spark: A Tale of Two Computation Engines
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Presto on Spark:支持即时查询和批处理】(https://www.iteblog.com/archives/9845.html)







