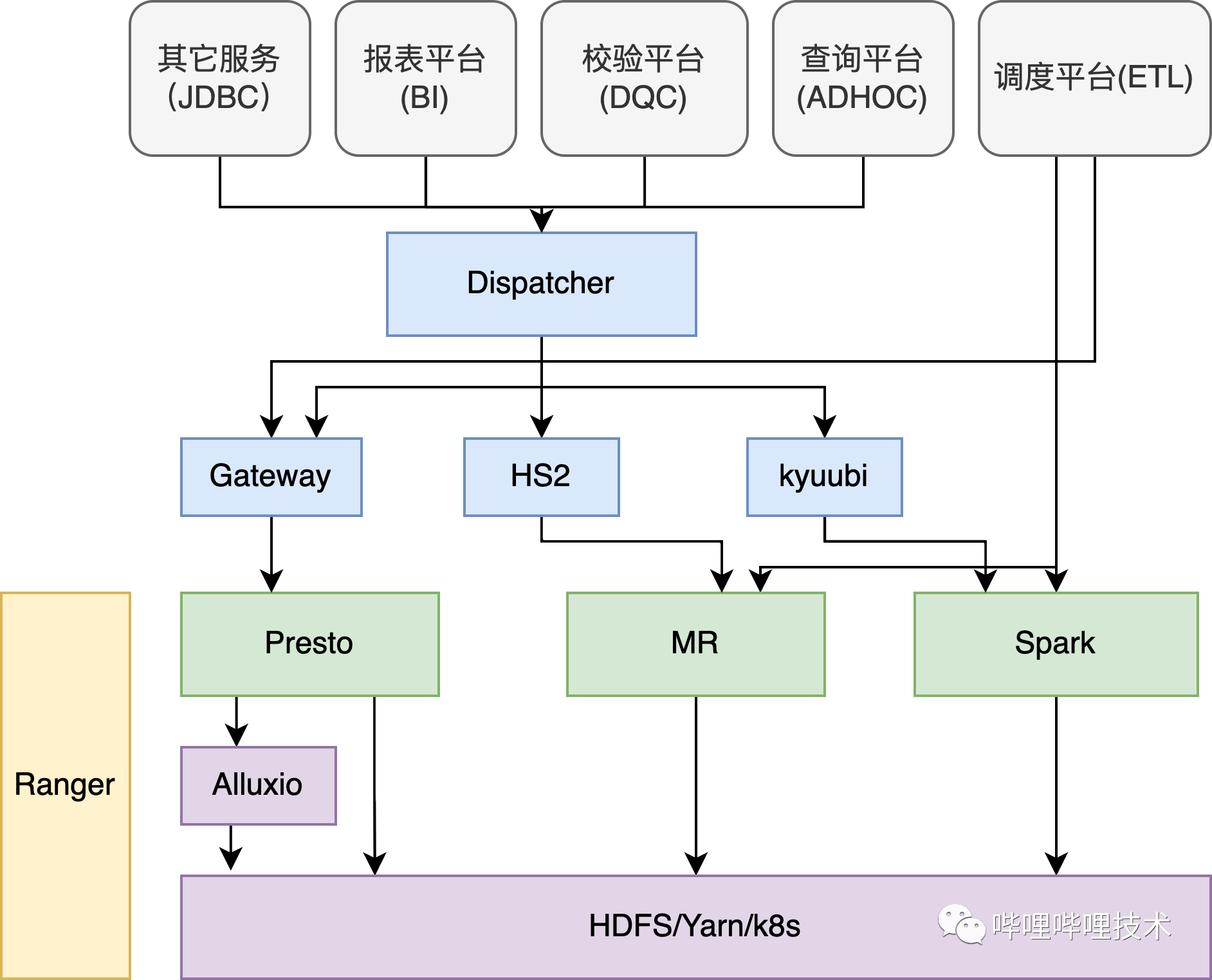
文章目录

导读:向量化技术带来极致的CPU效率的同时,也已经成为了软件开发的趋势,而数据库的向量化不仅仅是 CPU 指令的向量化,还是一个巨大的性能优化工程。本文从CPU向量化原理出发,通过Cache、虚函数、SIMD等方面讨论CPU的性能优化,介绍了Apache Doris现有列存行式计算结构向列存列式计算结构的转变,同时展示了目前Apache Doris对JOIN等多个SQL向量化算子的初步支持及未来规划。
具体包括以下几个方面:
Doris向量化的设计与实现
Doris向量化的当前情况
Doris向量化的未来规划
Doris向量化的设计与实现
1. 什么是向量化?
从字面意义上理解,向量化其实就是由一次对一个值进行的运算,转化成一次对一组值进行运算的一个过程,我们可以从不同角度来分析。
① CPU的角度分析
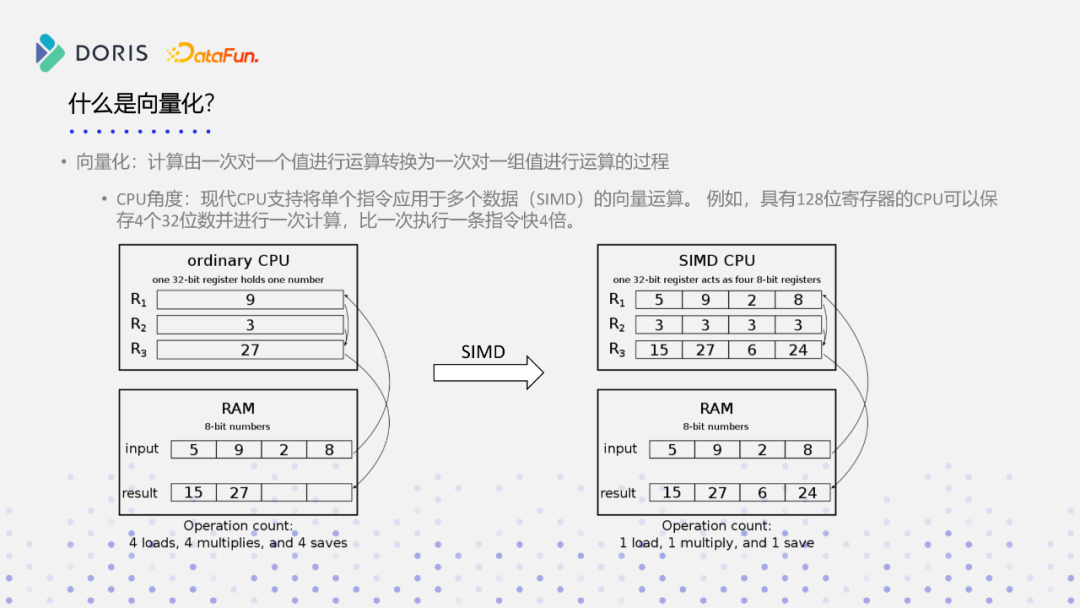
从CPU的角度分析,现代CPU都能够支持将单个指令应用于多个数据的SIMD向量化计算,所谓向量化计算就是利用SIMD指令进行运算,比如一个具有128位寄存器的CPU,可以一次性从内存当中拉取四个32位的数据,并且进行计算,再把这个128位的数据写回到内存当中,这就比一次执行一条指令快四倍。
上图是一个CPU做乘法运算的寄存器流程图,在内存当中有四个INT,而INT是32位的,进行计算的时候,没有SIMD支持或者没有向量化支持的CPU,从内存当中load的数据需要重复四次,然后再做四次乘法计算,然后把这个结果再写回到内存当中,同样要做四次。如果支持SIMD,一次就能载入多个连续的内存数据,这样就只有一次的内存的load和一次的计算,比如四个数据连续做一次乘法运算,然后得到四个结果,写到四个寄存器里面,然后四个寄存器写回到内存当中,就完成了一次向量化的指令计算操作,这样的操作,就比原先传统的没有SIMD支持或者没有向量化支持的CPU能够快四倍。现在随着CPU本身的发展,大家常用的是128位的SSE指令,后面又多了256位的AVX指令,包括英特尔现在最新的AVX2指令,寄存器的位数不断变长,所以向量化一组运算,可以变得越来越多,它的效率可能会越来越高,但这不是一个线性的关系,不一定随着寄存器的位数越多,它的性能就是线性增长,但是它能够保证一次对一组值的操作是更多更快的,这是在CPU的角度去看向量化这个问题。
② 数据库的角度分析
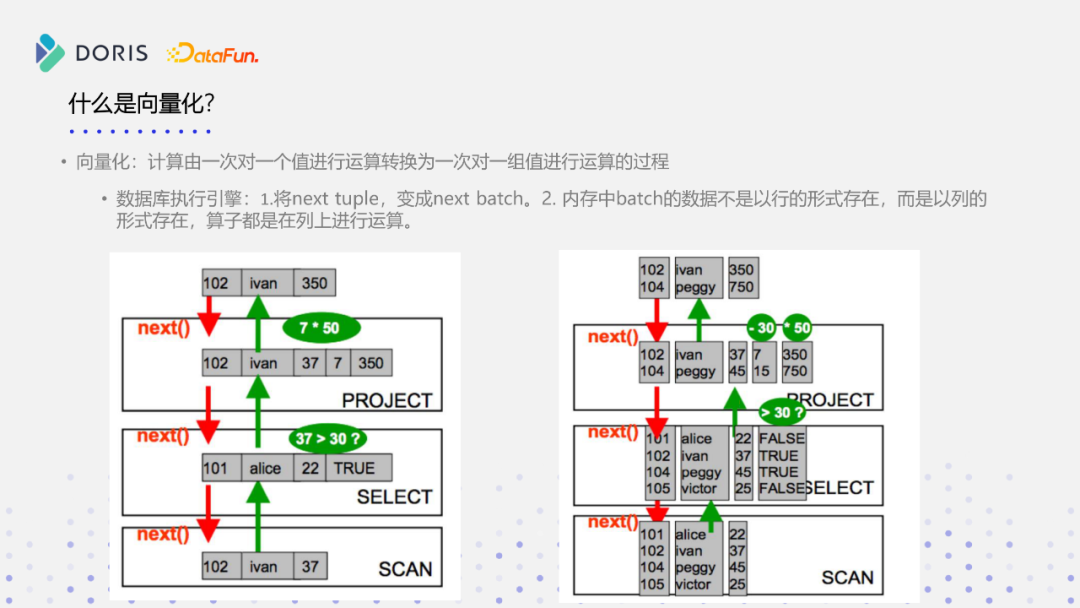
从数据库角度分析,与CPU的角度类似,也是从一次对一个值的运算,转化成一次对一组值的运算。传统数据库执行引擎是一行一行去处理数据的,如上图所示,做一次SCAN操作和一些过滤条件,再做一次乘法,数据库一次能扫描出一行,然后在这行上做对应的数据判断、计算,一次只做一个值的操作。而实现了向量化的数据库,会把对一个tuple的操作,转化成一次对一组值的操作,内存中一个batch的数据不再以行的形式存在,而是以列的形式存在,所有的计算都通过列的方式进行连续计算。如上图所示,做数据扫描,对扫描的数据做一个判别,按照左图,对一组值要判断四次,而在支持SIMD的数据库引擎上,只需对一列的数据进行一次判断,而不是对原来的一行做判断。
2. Doris如何实现向量化
实现向量化的核心工作,主要分为三块。
第一块就是列式存储,需要在Doris本身的执行引擎当中,引入基于列存的内存格式,Doris存储层的本身就是以列方式存储的,但是在执行引擎当中,还是基于行的方式来做运算,是基于Tuple的运算,一次只能计算一个值,所以需要把对一个Tuple的计算切换为一个列式格式来计算,这样才能实现向量化。
同时会基于新的列式存储格式,重新设计一套向量化和列式存储的计算引擎。
最后,基于列式存储跟向量化的函数计算框架,实现所有的向量化算子,包括当中常用的聚合、排序、JOIN,所有的SQL算子。
① 列式存储
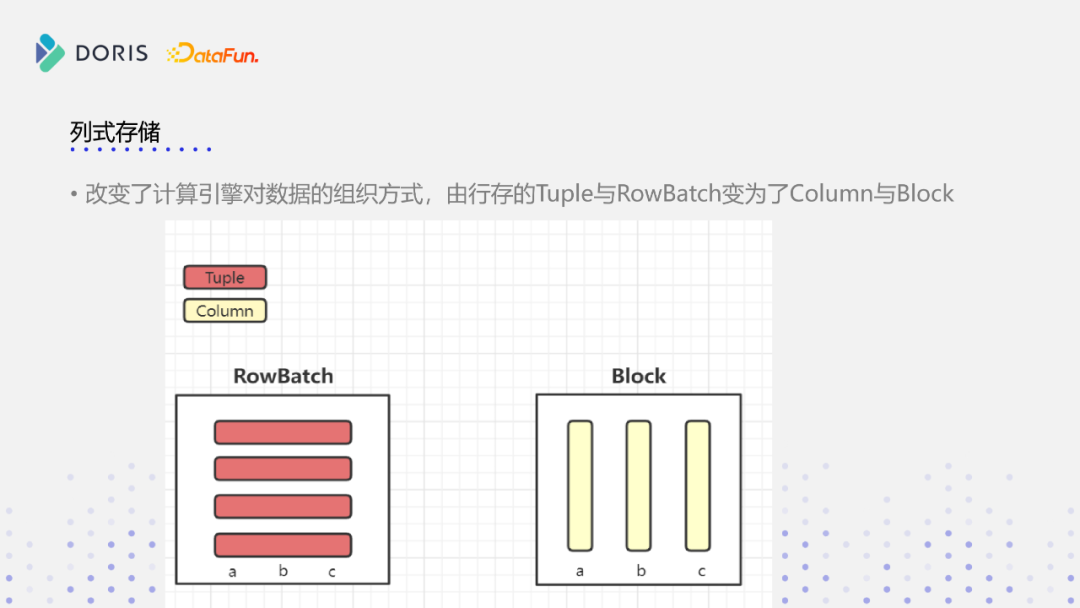
现有Doris执行引擎当中,内存结构如上图左边部分所示,是由一个RowBatch结构表示,它的数据是通过一个一个Tuple进行组织的,每一个Tuple是个连续的内存,可以看到左边RowBatch的结构,它分为三个列,但它每一行是连续的内存结构,每次也是处理一组值,但其实在这组值的内部处理当中,还是按行处理的。新的内存结构叫Block,它的数据是以列的方式来存储的,每一个列是一个连续的内存结构,现有Doris的执行引擎是RowBatch加Tuple实现的,新的向量化引擎变成Block和Column实现。
② 计算框架
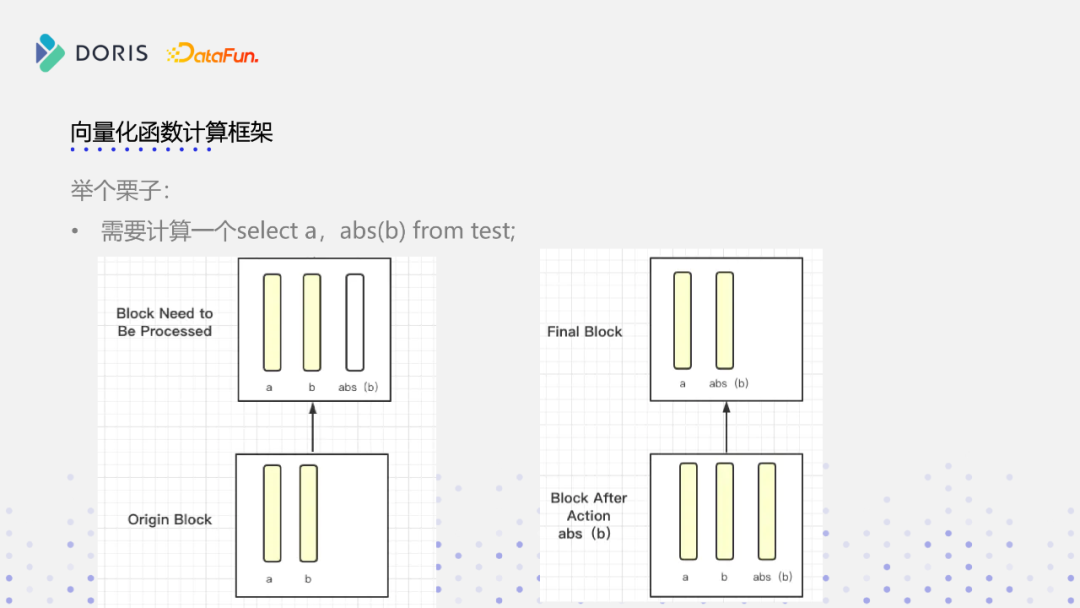
如上图所示,现有Block里面原来只有两列,a、b两列是连续的内存,是按列组织的内存,abs是一个计算函数,它是这样的一个流程,首先存在原始的Block,数据读入后,分为a、b 2列,对b列做abs计算,在原来的行式存储的逻辑上,如果要进行abs计算,a列这部分内存虽然计算跟它没有关系,但它也会参与进来,因为是基于行的连续内存。但是我们可以看到,在向量化函数执行框架当中,a列这部分内存是不再参与进来了,在内存结构上已经与b列独立开了,如图所示,在b列经过abs计算之后,会生成一个abs(b)列,而a列在整个计算过程中都没有这个内存上的交互,看右边这张图,做完abs计算之后,在原有的Block上新生成一个连续的内存结构,新生成一个列,是abs(b)列,那最后再把b列给过滤掉,最终的这个Block就留下a列和abs(b)列这两个列,就完成了一次列式存储的向量化计算。

从上图,我们能看到出为什么向量化函数计算和原先的函数执行逻辑相比,能够提高性能。上图左边这段代码是原来函数执行的逻辑,一个batch输入进来之后,我们需要遍历它的所有行,然后获取这行数据之后,要通过它的slot去确定在这行数据上的偏移,这样才能拿到对应列的数据,基于该列,每次要做一次类型的判断,然再确定调用对应函数进行处理。比如说类型是int,会调用int的hash函数,如果是string,就调用string的hash函数。如上图右边部分代码逻辑,可以看到列存的执行逻辑,相对行存来说就更简洁。首先在整个Block的执行过程中,只有一次类型判断,假如说row batch或者Block有1024行,行存执行逻辑对于类型的判断就要重复1024次,对于列存来说,它只要执行一次。同时存在隐含的逻辑:列存是连续的,对连续的一段内存做处理,相对于Cache亲和度更高。

向量化函数计算框架具有以下三个优点:
Cache亲和度。首先列式计算由于数据是按列组织的,所以更容易命中Cache,比如说上文函数计算的例子,计算abs(b),在列式计算过程中,没有相关的其他列是不会参与到计算过程当中来的,同时列式计算的数据在列上是连续的,更容易命中Cache。
减少虚函数调用。减少虚函数调用会减少分支跳转,例如类型的判断,在向量化框架当中大量的用模板方式做零成本的抽象,去减少虚函数的调用。
函数计算SIMD。基于SIMD,CPU能从一次计算一个值到一次计算一组值,这样计算效率、速度就会有数倍的提升。推荐如下论文:《DBMSs On A Modern Processor Where Does Time Go?》,时间都去哪了,该论文分享了在现代处理器上,可能真正在查询当中做计算时间可能只有20%~30%都不到,数据库花费了大量时间在什么样的地方,该论文总结以下三点:Memory stalls、Branch mispredictions和Resource stalls,这也是我们需要去解决、优化的方向。
Cache:
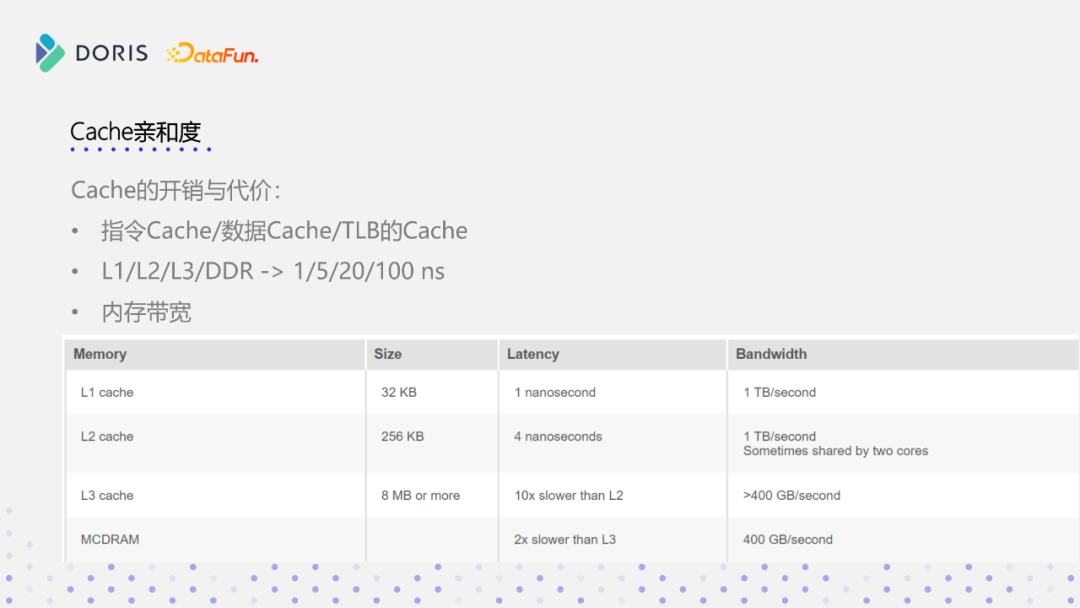
在CPU角度分析,Cache分为三块,第一块是CPU指令的Cache,第二块是数据的Cache,第三部分是TLB,即虚拟地址转换成物理地址,在CPU的内部,会有一个TLB的表,这其实也是一层Cache,以上三部分就是我们真正理解上的Cache和真正可能感知到Cache,如果上述三部分处理不好,会对整个SQL查询有很大的性能影响。
下表是英特尔官方列出来一个表格,如表所示为L1,L2,L3、DDR当中,访问的时间开销,可以看到L1只有1ns,L2在4~5ns,那L3跟L2有十倍的差距,二实际要访问内存可能就要100纳秒以上,那可以想象,如果我们一个数据能够在L1处缓存的话,它能够节省CPU的时钟周期是很可观的,节省的时钟周期内CPU能够执行很多的指令,同时我们一旦要去访问这个DDR当中的数据,还涉及到内存带宽,内存带宽控制硬件逻辑上所有程序都可能都要访问内存,还涉及到内存带宽调度的问题,所以要尽可能提高程序它的Cache亲和度,以此来提升SQL执行的性能。
虚函数调用:

虚函数开销主要有以下两点,第一点是虚函数是动态调用的,无法进行函数内联,所以在实际调用时需要去查表,而查表,编译器是无法进行内联的,而函数无法进行内联,对性能会有极大的影响。我们知道其实函数内联真正带来的意义是给编译器更多的优化空间,但因为虚函数调用没有办法进行函数内联了,所以编译器获取信息就会减少,而编译器可以进行代码的优化的空间就会减少。第二点即虚函数它的执行过程中是需要查表的,那查表就必然带来分支跳转,分支跳转在CPU当中,是有一定开销的。如上图所示,是一个CPU的pipeline的执行流程,分为取值,然后对值进行decode,然后指令执行和内存回写这四个stage。而现代CPU比图中复杂很多,CPU流水线可能有十几二十级,一旦CPU进入一个跳转流程当中,原则上来讲,pipeline是要暂停下来的,而跳转指令是依赖前一个指令的执行结果,才能确定要执行什么指令,但是现代CPU都会进行分支预测,让流水线空转,分支预测一旦成功的话呢,指令会顺着流水线执行下去,当然是得到很好的收益,但一旦分支预测失败,就会导致流水线全部重新刷写,这会带来极大的性能开销。分支预测失败会导致CPU流水线重新执行,所以这就是虚函数调用会产生的开销。
SIMD:
SIMD其实分为两块,第一块自动向量化,编译器会根据编译时的优化指令,去开启自动向量化,编译器会分析代码中每个for循环能否进行向量化,GCC当中开启o3的优化就会启动自动向量化,但默认它是对SSE2的这个指令集进行优化的。当然你也可以根据CPU本身的架构,配置更多的指令集进行优化。
对于自动向量化有一些建议:1.足够简单的for循环;2.避免在for循环中进行一些函数调用、分支跳转,例如if的判断,break等,这样对这个编译器的自动向量化是很不友好的;3.避免数据依赖,例如下一个计算结果是依赖上一个循环的结果,这样的话那个编译器是d没有办法给你做自动向量化的;4.连续的内存跟对齐的内存,SIMD指令本身对于内存要求是比较多的, SIMD能够连续载入多个数据,但如果数据在不连续的内存上,SIMD没有办法做连续的载入,而内存对齐,会影响这个向量化指令的一些执行效率。GCC的文档上面给了一个比较完整的case,大家有兴趣的话可以参考一下。
https://gcc.gnu.org/projects/tree-ssa/vectorization.html

我们实现了一个代码之后,怎么确认编译器开启了自动向量化了呢?编译器存在几个hint提示,大家可以把该提示打开之后,就能在编译的过程中可以看到这个编译器的提示,首先第一个就是打印所有的编译器的向量化信息,如果循环代码被向量化了,这个编译器会打印对应的这个信息,LOOP VECTORIZED就是告诉你这个循环被向量化,如果没有被向量化的话,你可以看到打印这个hint:vec-missed的,但改原因是比较难以排查的,如果你要是更深入分析的话,可以用下面我给大家的这个hint,就可以进一步分析,就为什么没有被向量化,他会把这个向量化的分析树打出来告诉你,可能是因为可能向量化之后开销可能比没有向量化可能更高或者怎么样的。其实我们在一个大型程序上,我们可以直接把编译出来的这个产出通过perf/objdump,直接看生成的汇编代码就可以看到它有没有向量化,如上图所示,向量化指令是以v开头的,所以大家看到这个v开头的,大概率就是向量化了,然后同时也可以看到用了XMM这个寄存器。在x86的体系当中呢,128位的寄存器是XMM,256位的寄存器是YMM那个512位的寄存器就是ZMM的,这就是查看自动向量化的一个流程。

SIMD本身也通过库的方式做了支持,可以直接通过向量化的API库进行向量化编程,这种实现方式是最为高效的,但是这种方式给程序员带来的薪资成本是很高的,你要熟悉SIMD的编码方式,同时会带来一个问题,即我们前面讲到CPU自动向量化,它是由编译器来实现,编译器来实现的话,它就不在于去关注底层的这个CPU架构这些问题,但是你一旦去手写的话,你就要去关注这些问题了。比如说实现abs的这个向量化的算法,你就不能在不支持abs指令集上的机器上运行了。所以说这种方式,它高效但不通用,就比如说我们要实现一个手写SIMD的话,如果你要在多个不同框架的CPU当中运行的话,需要在x86写一套,同时还要针对ARM写一套,假如说你要支持RISC-V,还需要再写一套,这种方式不通用,且兼容性比较差,程序员的薪资成本也比较高。所以说我们在实现这个Doris向量化的这个过程当中,为了避免这个abs这个问题,综合了这两种方式我们所有的实现都是基于SSE去来做的,SSE是这个x86当中最通用的一个向量化指令集,这个指令集基本上现在在跑的机器,97%以上的服务器都支持这个指令集。
Doris向量化的当前情况
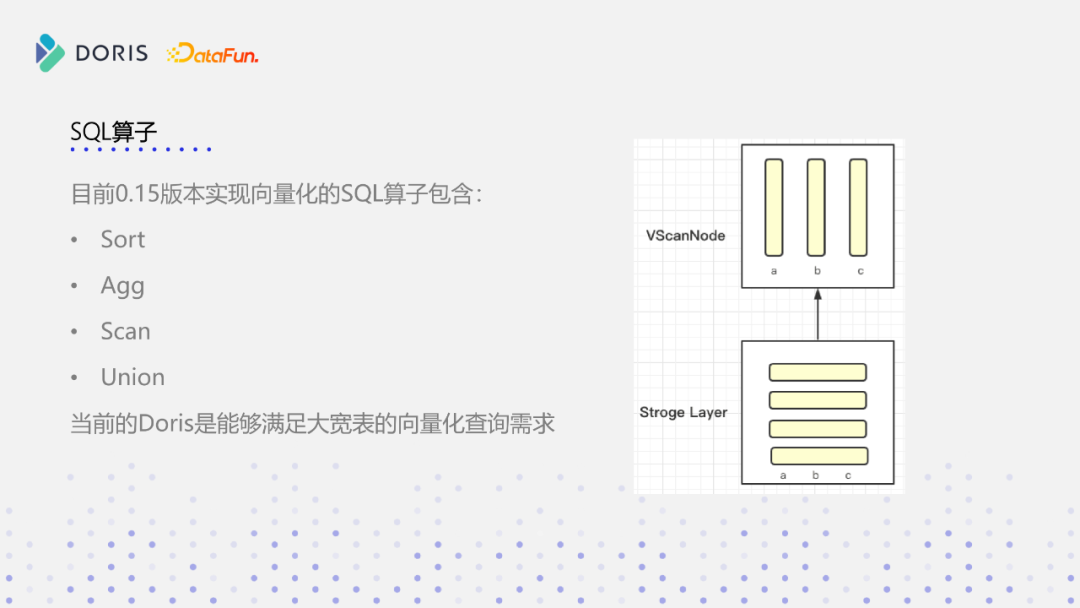
Doris在0.15版本我们发布了一个基于单表大宽表向量化执行引擎,它能够支持sort、agg、scan、union,我们给它的定位是能够满足大宽表的向量化查询需求。Doris的数据存储是基于列式存储,但目前在数据读取到内存后,有一些去重和聚合的计算,该过程还是基于行式存储来做的。在向量化执行引擎上,在scan node上就会把数据转成列式的结构,基于这个列式结构再实现向量化算子。
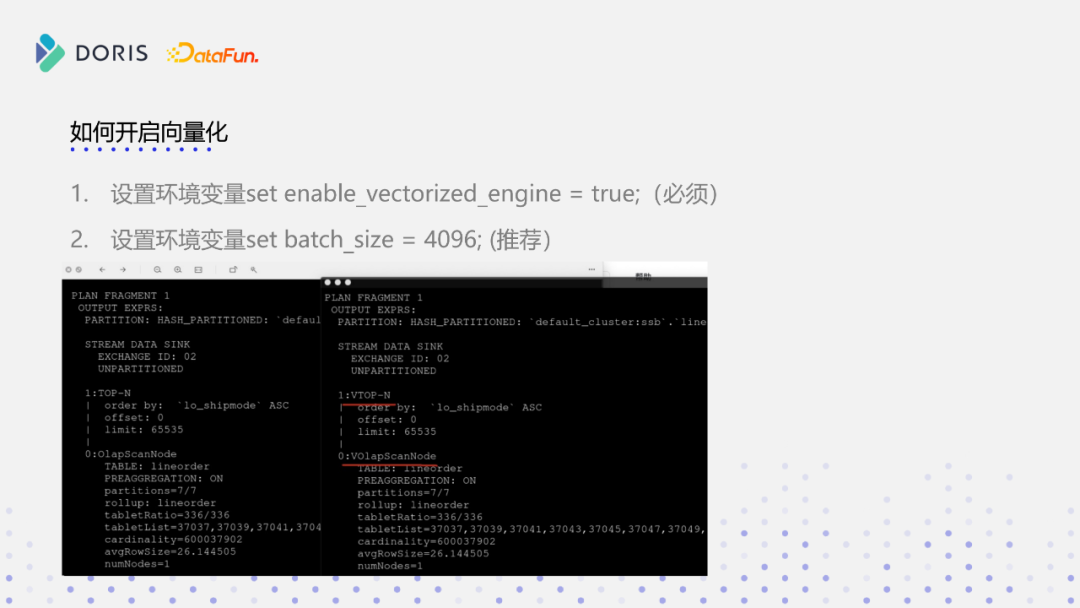
开启向量化首先就是设置环境变量,设置一个set enable_vectorized_engine = true,如下图所示,我们可以看到node上会带一个v的结构,这个其实跟汇编指令生成的SIMD指令集是一样的,这个v就代表开启向量化。另外一个参数是我们在实际的测试当中测下来的最佳实践,set batch_size = 4096。
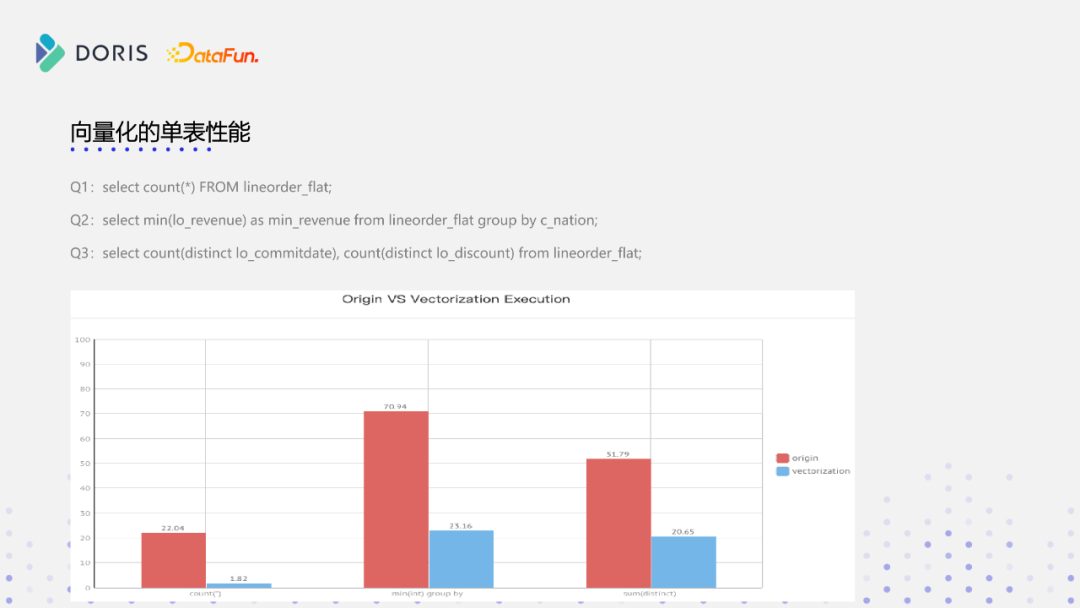
下图是我们在单表上做的一些测试,跟原来行存做了一个对比,选了几个比较有典型代表性的query,第一个是单表上不做group by的操作,我们可以看到的性能提升十倍左右,如果带group by列,再做一个聚合运算的话,性能可能达到两到三倍的提升,然后最后就是count distinct,基本上都有两到三倍的性能提升,所以性能提升的效果还是比较可观的,当然这是目前我们实际测的一个向量化的性能,后续的版本性能会更激动人心,希望大家期待一下。
03
Doris向量化的未来规划
下面讲一下我们目前还在做的一些工作,以及未来的一些规划。
1. JOIN算子
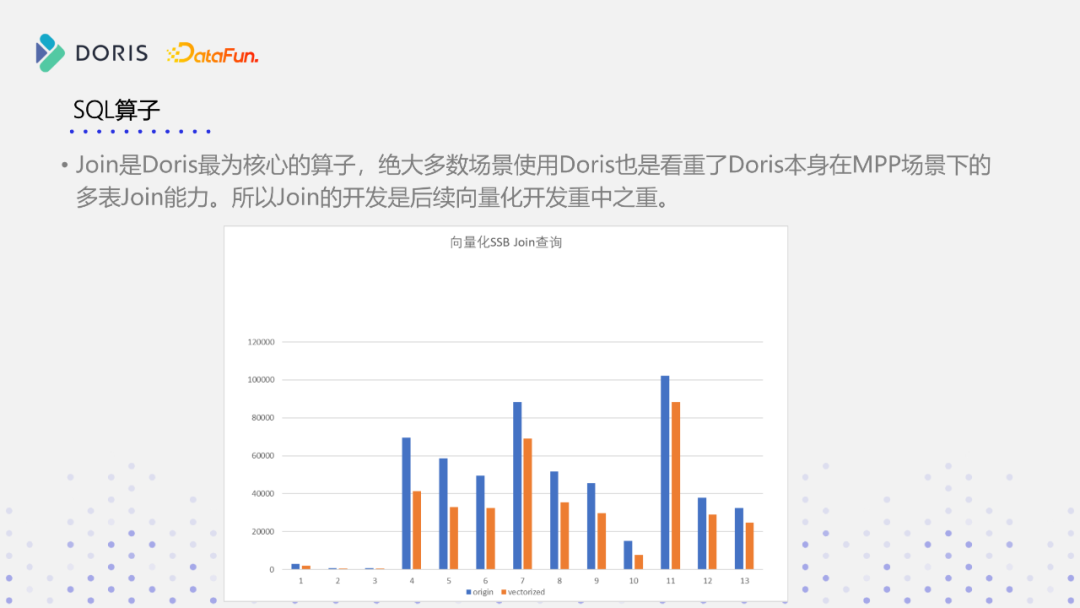
JOIN算子是SQL最为核心的算子,Doris绝大多数的使用场景,其实也是看重本身在mpp场景下多表JOIN的能力,所以说JOIN算子开发也是我们向量化开发当中的重中之重。目前我们已经实现了JOIN的向量化,但还没有做过比较系统的调优,这一版我们在基于SSB指令集测试集做了一个JOIN向量化的性能测试。JOIN性能有一倍或者30~40%提升,如果JOIN数据量大的话,性能提升也是很明显的。

另外是除了JOIN之外的可能用到的一些SQL算子,比如交集、差集、Cross JOIN、ODBC/MySQL Scan Node、窗口函数、ES Scan Node等,这些算子都是当前Doris行存支持的SQL算子,除了这部分算子还在开发过程中,其他都已经ready了,我们现在还在做一些稳定性和性能调优工作。
2. 存储层向量化

目前Doris数据是基于列式存储在磁盘上的,但数据读取到内存后,要对数据做一次聚合或者去重,该过程中是通过行存来表示的,但由于历史原因,这块存在很多冗余且低效的代码,目前我们在实际的向量化开发中,发现它已经严重影响到整个向量化代码的执行逻辑和性能,它有如下几个问题:
计算表达式受限制,目前存在很多计算表达式,由于内存结构不同、计算接口的不同,实现的向量化算子,没有办法作用于存储层,导致表达式没有办法做下推;
额外的转换,导致性能损耗是比较严重的,会严重影响到导入跟查询性能;
代码可维护性低。

我们做了一个POC的测试,在DupKey表上通过完整的向量化改造之后,性能还能有十倍级别的提升。然后就是在代码可维护性上,因为结构不同,目前Doris执行引擎实现的聚合算子,没有办法作用于存储引擎,同样一个聚合代码,例如计算min、max、sum需要在存储引擎和查询引擎分别作一个实现,所以目前在做的一个很重要的工作,就是把Doris目前存储层这块通过行存做去重、聚合的逻辑,转换成向量化,这部分工作我们还在进行当中,完成存储层向量化之后,我们可以看到相对于原先向量化的版本,它能再有一倍的提升。如上图所示,列举了几个比较典型的查询,在完成存储层向量化后性能会有1倍以上的提升。
3. 导入向量化
目前Doris在进行数据导入的时候,还是存在内存结构不统一的问题,后续我们希望通过导入向量化,减少格式转换以此来提高CPU利用率,同时能够复用计算层算子,减少冗余低效代码的同时简化Doris现有的代码结构,最后利用SIMD技术,加快导入过程当中的一些聚合计算,进一步提升Doris的导入性能。目前向量化版本实现了一个简单的一个导入框架,在Block计算完成之后,它是以列组织的。
4. SQL函数
首先是函数丰富度的支持。目前Doris已有的函数还是比较丰富,但向量化因为它是基于列存实现的,所以其函数接口包括调用方式都不同了,所以需要实现SQL算子的同时还要实现浩如烟海的SQL函数,就目前我们已经实现的向量化函数大概有200多个,其他函数目前还在不断的开发过程当中,我们需要尽快去补齐原先行存支持的SQL函数,这部分工作,也欢迎大家参与进来。
第二个就是函数的SIMD化,因为函数数量较大,在实现向量化函数时,没有考虑SIMD化,我们只保证它在列存上能够运行,同时几个优势就是它的分支预测变少了,分支跳转变少了,Cache亲和度高了,但函数没有SIMD化,所以我们要考虑这个函数SIMD化,尤其对于热点的核心函数,后面还需要尽可能的进行SIMD化,包括我们前面提到手写SIMD,我自己在开发过程当中手写了一些SIMD的函数,目前在这个Apache Doris master库,也能看到我之前所写的一些字符串的SIMD函数。
最后是向量化的UDF的框架设计和实现,UDF可能也是大家经常用到一个功能,但原来行存UDF在列式存储上无法运行,向量化上可能得重新设计一个UDF的框架,这也是我们后续要做的一些工作。
5. 代码重构
① 基础类型的重构
目前Doris向量化上所有的基础数据类型都能够支持,但是存在一些问题:
在Date/DateTime类型当中,是复用了行存的Date/DateTime类型,而行存的Date/DateTime类型,会有毫秒的数据,而我们在Doris当中是没有在用的,但是它占了比较大的存储空间,现在Date/DateTime类型占用了16字节空间,但可能毫秒就占了八字节,而这八字节我们完全没有用到。在我们原来行存当中可能还不明显,在向量化当中八个字节的占用就会带来额外的内存开销,对SIMD非常不友好。另外一个问题就是Date/DateTime类型,目前没有一个更好的内存布局,导致他在做SIMD的时候会有各种各样的问题。所以我们准备去重构Date/DateTime类型,实现一个对于向量化版本更好、更小的内存占用,并且对SIMD更友好的结构。
Decimal,Decimal在Doris中存在两个问题,第一个是在精度上,它没有根据我们实际用户设的精度,可以去切换内存占用,它统一都占了16字节的内存,这是比较浪费的,例如用户只要一个比较低精度的一个值,用四字节就能够表示了,但目前Decimal统一占用16个节点,这个是很大的一个开销,造成了较大的精度浪费,这个也是目前Decimal存在一个问题,我们也准备对这个结构做一个重构。
HLL,HLL在计算时,会有很多无效的序列化开销,也会造成很大的性能影响。目前我们已经把bitmap做完重构了,我们用了一个新的结构去表示bitmap,它能减少大量的序列化开销,整个性能表现也不错,但HLL我们还没做,是下个阶段我们要做的这个事情。
② String/Array类型的支持
第二个就是Doris当中更丰富的类型支持,目前行存的版本能够支持String类型,但向量化这块对String类型需要重新设计,不能直接套用过去,因为String是比较大内存占用,还有就是Array类型的支持。
③ 聚合表类型再梳理
目前Doris聚合表上其实有一个表意不明的问题,例如创建了一个聚合表,指定一个min、max,指定了它的数据类型和nullable属性,但其实这块是有一些歧义的,就比如说count,这个列能不能设成nullable,或者说有没有必要设成nullable?首先count的结果是不可能产生nullable。但在SQL计算引擎当中再把它设成nullable列的话,就会导致我们需要做代码兼容,还会引进来一系列的问题,所以说要重新审视一下Doris目前聚合表的结果,设计更合理的聚合列的状态和类型。
④ 进一步提升向量化执行引擎的性能
结合目前我们团队还在打造的一款CBO优化器,基于该优化器,能够解决上文提到的函数内联的问题,该优化器在运行期间能够收集到更多的消息,这样我们在向量化执行引擎上,就能做更多更深层次的优化,来进一步提高我们目前这个向量化执行引擎的性能。
最后,感谢Clickhouse社区,Doris在进行向量化代码开发的时候,在列存模型跟函数框架上引用了部分Clickhouse 19.16的代码,同时在引用代码上我们也做了license对应注明,也很感谢Clickhouse社区在我们向量化代码开发上给予的帮助。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Doris 向量化设计与实现】(https://www.iteblog.com/archives/10142.html)