《Learning Spark, 2nd Edition》这本书是由 O'Reilly Media 出版社于2020年7月出版的,作者包括 Jules S. Damji, Brooke Wenig, Tathagata Das, Denny Lee。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书介绍第二版已更新包含了 Spark 3.0 的一些东西,本书向数据工程师和数据科学家展示了 Spark 中结构化和统一 w397090770 5年前 (2020-09-03) 2946℃ 0评论10喜欢
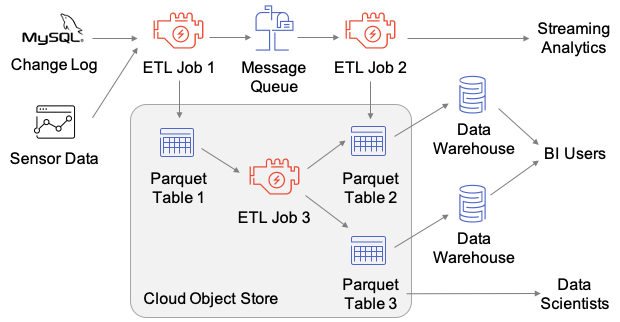
最近,数砖大佬们给 VLDB 投了一篇名为《Delta Lake: High-Performance ACID Table Storage overCloud Object Stores》的论文,并且被 VLDB 收录了,这是第一篇比较系统介绍数砖开发 Delta Lake 的论文。随着云对象存储(Cloud object stores)的普及,因为其廉价的成本,越来越多的企业都选择对象存储作为其海量数据的存储引擎。但是由于对象存储的特点 w397090770 5年前 (2020-08-25) 1081℃ 0评论2喜欢
前言Facebook 的数据仓库构建在 HDFS 集群之上。在很早之前,为了能够方便分析存储在 Hadoop 上的数据,Facebook 开发了 Hive 系统,使得科学家和分析师可以使用 SQL 来方便的进行数据分析,但是 Hive 使用的是 MapReduce 作为底层的计算框架,随着数据分析的场景和数据量越来越大,Hive 的分析速度越来越慢,可能得花费数小时才能完成 w397090770 5年前 (2020-08-09) 1731℃ 0评论4喜欢
在 《Apache Spark 自定义优化规则:Custom Strategy》 文章中我们介绍了如何自定义策略,策略是用在逻辑计划转换到物理计划阶段。而本文将介绍如何自定义逻辑计划优化规则,主要用于优化逻辑计划,和前文不一样的地方是,逻辑优化规则只是等价变换逻辑计划,也就是 Logic Plan -> Login Plan,这个是在应用策略前进行的。如果想及时 w397090770 5年前 (2020-08-07) 1356℃ 0评论2喜欢
这篇文章本来19年5月份就想写的,最终拖到今天才整理出来😂。Spark 内置给我们带来了非常丰富的各种优化,这些优化基本可以满足我们日常的需求。但是我们知道,现实场景中会有各种各样的需求,总有一些场景在 Spark 得到的执行计划不是最优的,社区的大佬肯定也知道这个问题,所以从 Spark 1.3.0 开始,Spark 为我们提供 w397090770 5年前 (2020-08-05) 1159℃ 2评论3喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop假设我们有以下表:[code lang="scala"]scala> spark.sql("""CREATE TABLE iteblog_test (name STRING, id int) using orc PARTITIONED BY (id)""").show(100)[/code]我们往里面插入一些数据:[code lang="sql"]scala> spark.sql("insert into table iteblog_test select w397090770 5年前 (2020-08-03) 3505℃ 0评论4喜欢
本文为阿里巴巴技术专家余根茂在社区发的一篇文章。Structured Streaming 最初是在 Apache Spark 2.0 中引入的,它已被证明是构建分布式流处理应用程序的最佳平台。SQL/Dataset/DataFrame API 和 Spark 的内置函数的统一使得开发人员可以轻松实现复杂的需求,比如支持流聚合、流-流 Join 和窗口。自从 Structured Streaming 发布以来,社区的开发人 w397090770 5年前 (2020-07-30) 789℃ 0评论1喜欢
R 是数据科学中最流行的计算机语言之一,专门用于统计分析和一些扩展,如用于数据处理和机器学习任务的 RStudio addins 和其他 R 包。此外,它使数据科学家能够轻松地可视化他们的数据集。通过在 Apache Spark 中使用 SparkR,可以很容易地扩展 R 代码。要交互式地运行作业,可以通过运行 R shell 轻松地在分布式集群中运行 R 的作业 w397090770 5年前 (2020-07-09) 782℃ 0评论2喜欢
本文来自 IBM 东京研究院的高级技术人员 Kazuaki Ishizaki 博士在 Spark Summit North America 2020 的 《SQL Performance Improvements at a Glance in Apache Spark 3.0》议题的分享,本文视频参见今天的推文第三条。PPT 请关注过往记忆大数据并后台回复 sparksql3 获取。Spark 3.0 正式版在上个月已经发布了,其中更新了很多功能,参见过往记忆大数据的 Ap w397090770 5年前 (2020-07-08) 2579℃ 0评论3喜欢
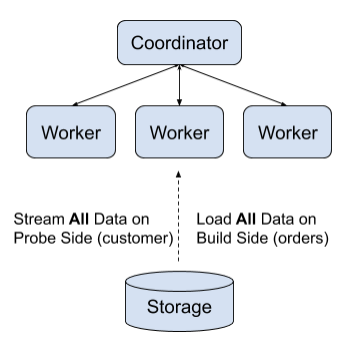
本资料来自 Workday 的软件开发工程师 Jianneng Li 在 Spark Summit North America 2020 的 《On Improving Broadcast Joins in Spark SQL》议题的分享。背景相信使用 Apache Spark 进行数据分析的同学对 Spark 中的 Broadcast Join 比较熟悉,其在 Join 之前会把一端比较小的表广播到参与 Join 的 worker 端,具体如下:如果想及时了解Spark、Hadoop或者HBase相关的文 w397090770 5年前 (2020-07-05) 2269℃ 0评论4喜欢