最近,Delta Lake 发布了一项新功能,也就是支持直接使用 Scala、Java 或者 Python 来查询 Delta Lake 里面的数据,这个是不需要通过 Spark 引擎来实现的。Scala 和 Java 读取 Delta Lake 里面的数据是通过 Delta Standalone Reader 实现的;而 Python 则是通过 Delta Rust API 实现的。Delta Lake 是一个开源存储层,为数据湖带来了可靠性。Delta Lake 提供 ACID 事务 w397090770 5年前 (2021-01-05) 1198℃ 0评论0喜欢
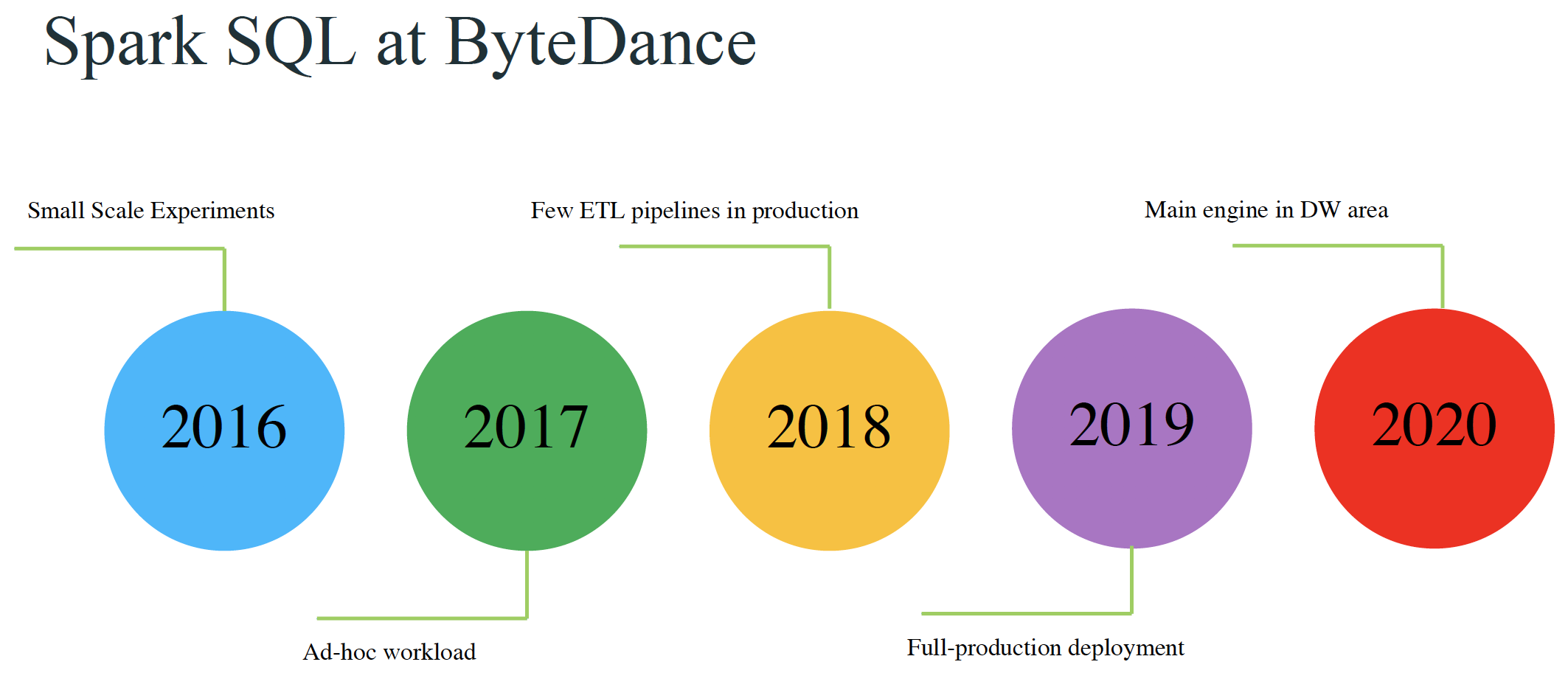
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Improving Spark SQL Performance by 30%: How We Optimize Parquet Filter Pushdown and Parquet Reader》的分享,作者为字节跳动的孙科和郭俊。相关 PPT 可以关注 Java与大数据架构 公众号并回复 9912 获取。Parquet 是一种非常流行的列式存储格式。Spark 的算子下推(pushdown filters)可以利用 P w397090770 5年前 (2020-12-14) 2803℃ 2评论4喜欢
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 5年前 (2020-12-13) 934℃ 0评论3喜欢
Data + AI Summit Europe 2020 原 Spark + AI Summit Europe 于2020年11月17日至19日举行。由于新冠疫情影响,本次会议和六月份举办的会议一样在线举办,一共为期三天,第一天是培训,第二天和第三天是正式会议。会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta Lake、MLflow、Structured Streaming、BI和SQL分析、深度学习和机器学习框架来 w397090770 5年前 (2020-12-06) 1253℃ 0评论2喜欢
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。Apache Iceberg 的底层数据组织我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I w397090770 5年前 (2020-11-29) 3822℃ 0评论4喜欢
本文根据贝壳找房资深工程师仰宗强老师在2020年"面向AI技术的工程架构实践"大会上的演讲速记整理而成。1 开场大家下午好,很荣幸来到这跟大家一起分享贝壳一站式大数据开发平台的落地实践。今天的分享主要分为以下四个部分:贝壳的数据业务背景。数据开发平台探索历程。数据开发平台的整体情况介绍未来规划与 w397090770 5年前 (2020-11-25) 1769℃ 0评论5喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 5年前 (2020-11-24) 1206℃ 0评论4喜欢
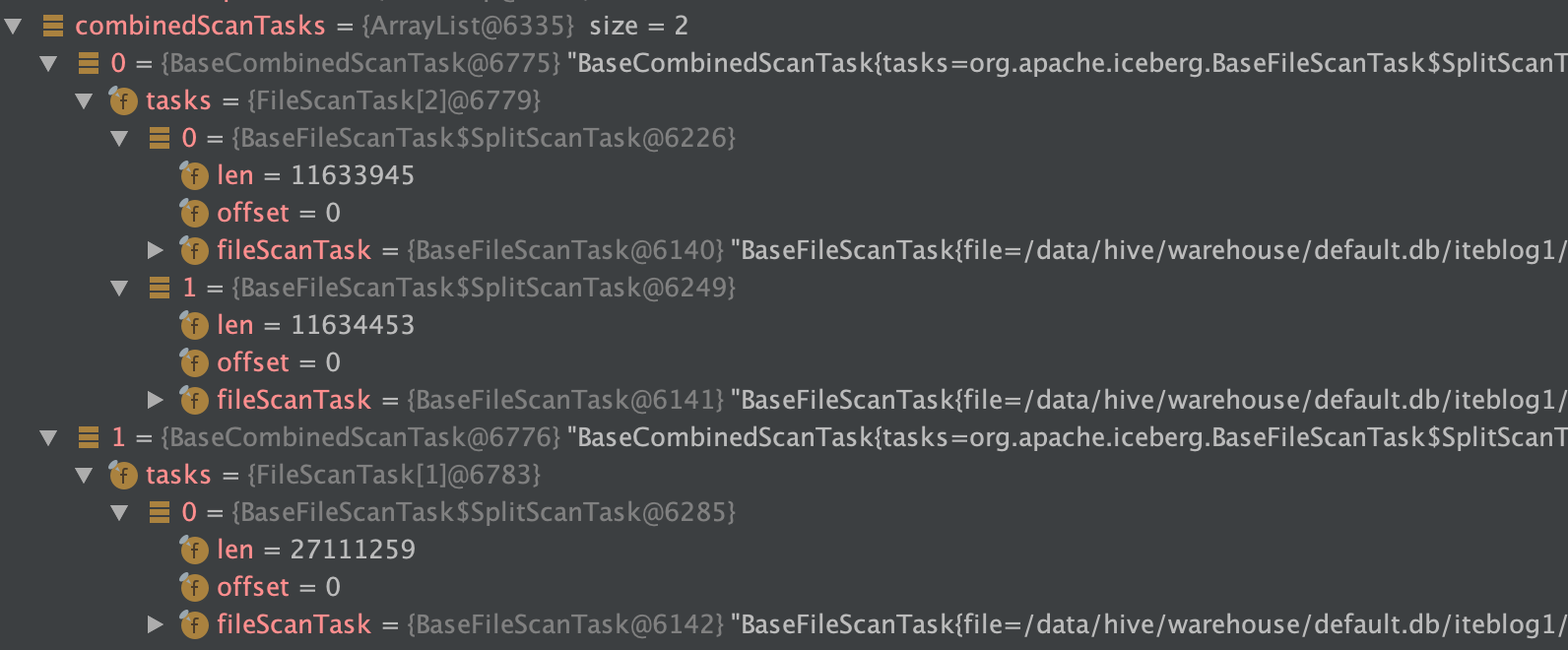
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):[code lang="bash"]/data/hive/warehouse/default.db/iteblog├── data│ └── ts_year=2020│ ├── id_bucket=0│ │ ├── 00000-0-19603f5a-d38a w397090770 5年前 (2020-11-20) 7089℃ 6评论8喜欢
本文基于 Apache Iceberg 0.9.0 最新分支,主要分析 Apache Iceberg 中使用 Spark 2.4.6 来写数据到 Iceberg 表中,也就是对应 iceberg-spark2 模块。当然,Apache Iceberg 也支持 Flink 来读写 Iceberg 表,其底层逻辑也 Spark 类似,感兴趣的同学可以去看看。使用 Spark2 将数据写到 Apache Iceberg在介绍下面文章之前,我们先来看下在 Apache Spark 2.4.6 中写数 w397090770 5年前 (2020-11-12) 6219℃ 0评论9喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在 这篇 文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:INNER JOINCROSS JOINLEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOINLEFT SEMI JOINLEFT ANTI JOIN在实现上 w397090770 5年前 (2020-10-25) 1758℃ 0评论6喜欢