赶在 Data + AI Summit 2021 之前,Delta Lake 1.0.0 重磅发布,这个版本是基于 Spark 3.1 的,带来了许多新特性。本文将结合 Michael Armbrust 大牛在 Data + AI Summit 2021 的演讲《Announcing Delta Lake 1.0》来介绍 Delta Lake 1.0.0 版本的一些重要的新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Delta Lake 0.1 w397090770 4年前 (2021-05-27) 937℃ 0评论2喜欢
本书作者 Denny Lee, Tathagata Das, Vini Jaiswal,预计2022年4月出版,出版社 O'Reilly Media, Inc.,ISBN:9781098104528分析和机器学习模型的好坏取决于它们所依赖的数据。查询处理过的数据并从中获得见解需要一个健壮的数据管道——以及一个有效的存储解决方案,以确保数据质量、数据完整性和性能。本指南向您介绍 Delta Lake,这是一种开 w397090770 4年前 (2021-05-27) 607℃ 0评论2喜欢
本文是 Forest Rim Technology 数据团队撰写的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被称为是数据仓库之父,最早的数据仓库概念提出者,被《计算机世界》评为计算机行业历史上最具影响力的十大人物之一。原始数据的挑战随着大量应用程序的出现,产生了相同的数据在不同地方出现不同值的情况。为了做出决定,用户必须找 w397090770 4年前 (2021-05-25) 666℃ 0评论0喜欢
在几乎所有处理复杂数据的领域,Spark 已经迅速成为数据和分析生命周期团队的事实上的分布式计算框架。Spark 3.0 最受期待的特性之一是新的自适应查询执行框架(Adaptive Query Execution,AQE),该框架解决了许多 Spark SQL 工作负载遇到的问题。AQE 在2018年初由英特尔和百度组成的团队最早实现。AQE 最初是在 Spark 2.4 中引入的, Spark 3.0 做 w397090770 4年前 (2021-05-23) 1279℃ 0评论2喜欢
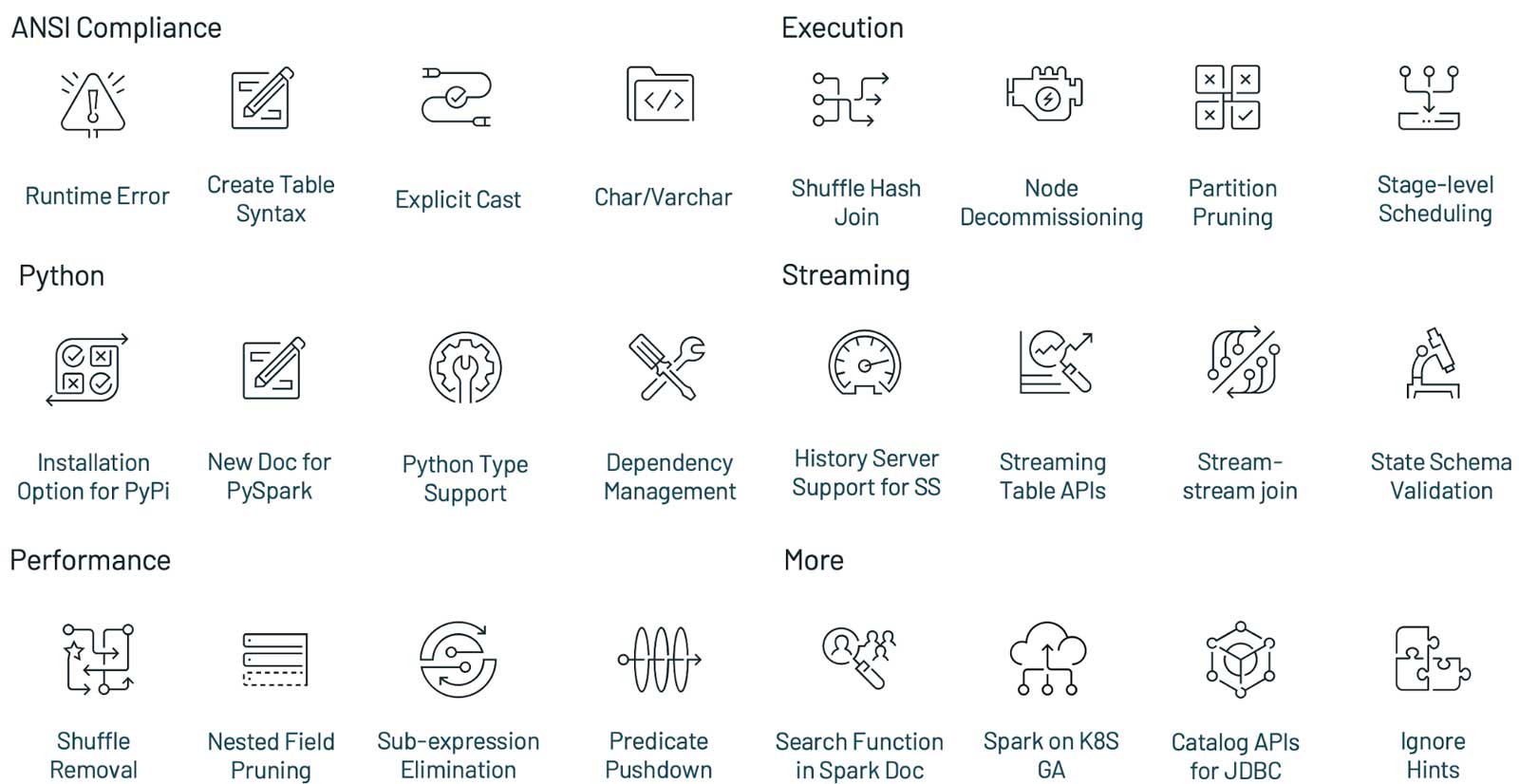
Apache Spark 3.1.x 版本发布到现在已经过了两个多月了,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming更多详情请参见这里。在这篇博文中,我们总结了3.1版本中 w397090770 4年前 (2021-05-16) 799℃ 0评论3喜欢
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, w397090770 4年前 (2021-04-05) 1387℃ 0评论4喜欢
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming注意,由于技术上的原因,Apache Spark 没有发布 3.1.0 版 w397090770 4年前 (2021-03-03) 2396℃ 0评论10喜欢
2021年2月1日, Databricks 在其博客宣布将投资10亿美元,以应对其统一数据平台(unified data platform)在全球的快速普及。 本次融资由富兰克林·邓普顿(Franklin Templeton)领投,加拿大养老金计划投资委员会(Canada Pension Plan Investment Board)、富达管理与研究有限责任公司(Fidelity Management & Research LLC)和 Whale Rock(美国的媒体和技术公 w397090770 4年前 (2021-02-02) 680℃ 0评论3喜欢
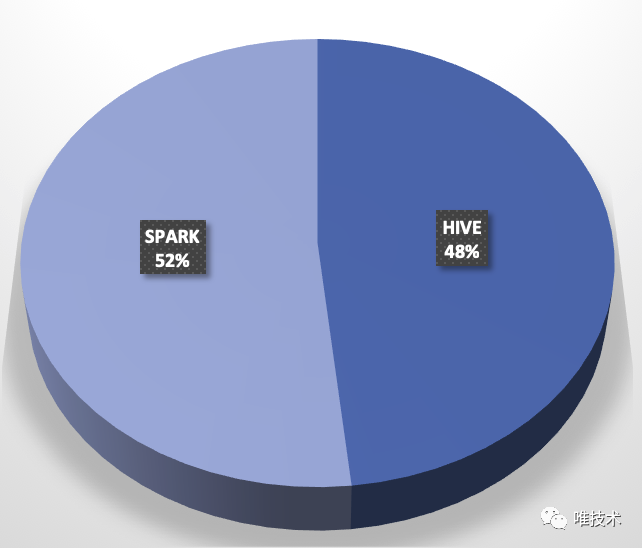
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展 w397090770 5年前 (2021-01-28) 2668℃ 0评论10喜欢
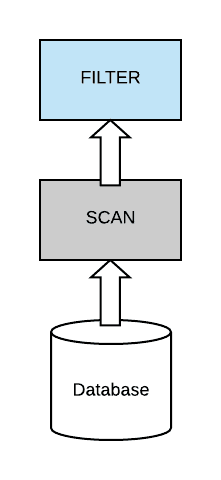
Spark 3.0 为我们带来了许多令人期待的特性。动态分区裁剪(dynamic partition pruning)就是其中之一。本文将通过图文的形式来带大家理解什么是动态分区裁剪。Spark 中的静态分区裁剪在介绍动态分区裁剪之前,有必要对 Spark 中的静态分区裁剪进行介绍。在标准数据库术语中,裁剪意味着优化器将避免读取不包含我们正在查找的数 w397090770 5年前 (2021-01-06) 1370℃ 0评论5喜欢