相关文章:《Apache Flink 1.1.0和1.1.1发布,支持SQL》
Apache Flink 1.1.2于2016年09月05日正式发布,此版本主要是修复一些小bug,推荐所有使用Apache Flink 1.1.0以及Apache Flink 1.1.1的用户升级到此版本,我们可以在pom.xml文件引入以下依赖:
[code lang="xml"]
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</a
zz~~
9年前 (2016-09-06) 1434℃ 0评论
1喜欢
Apache Flink 1.1.0于2016年08月08日正式发布,虽然发布了好多天了,我觉得还是有必要说说该版本的一些重大更新。Apache Flink 1.1.0是1.x.x系列版本的第一个主要版本,其API与1.0.0版本保持兼容。这就意味着你之前使用Flink 1.0.0稳定API编写的应用程序可以直接运行在Flink 1.1.0上面。本次发布共有95位贡献者参与,包括对Bug进行修复、新特
w397090770
10年前 (2016-08-18) 2150℃ 0评论
0喜欢
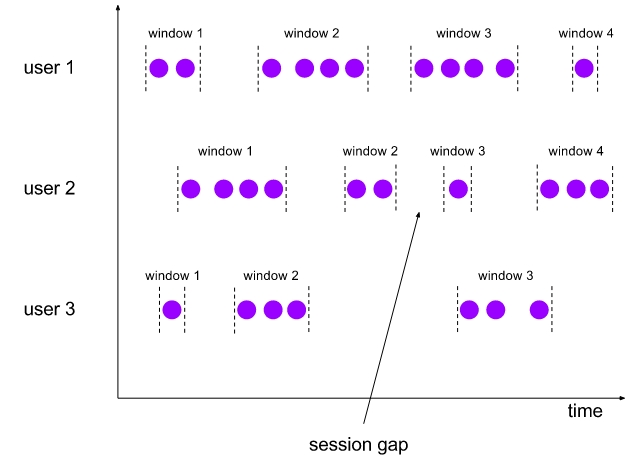
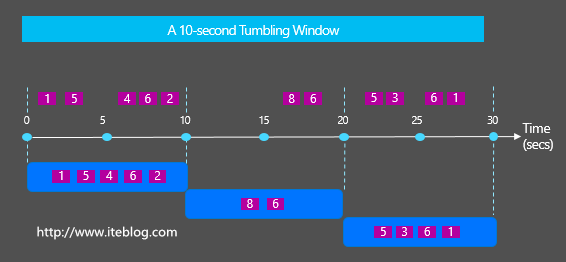
在流系统中通常会经常使用到Windows来统计一定范围的数据,比如按照固定时间、按个数等统计。一般会存在两种类型的Windows:Tumbling Windows vs Sliding Windows,它们很容易被初学者混淆,那么Tumbling Windows vs Sliding Windows之间到底有啥区别与联系呢?这就是本文将要展开的。
Tumbling的中文意思是摔跤,翻跟头,翻筋斗;Sliding中
w397090770
10年前 (2016-07-26) 3741℃ 0评论
4喜欢
Flink Table API
Apache Flink对SQL的支持可以追溯到一年前发布的0.9.0-milestone1版本。此版本通过引入Table API来提供类似于SQL查询的功能,此功能可以操作分布式的数据集,并且可以自由地和Flink其他API进行组合。Tables在发布之初就支持静态的以及流式数据(也就是提供了DataSet和DataStream相关APIs)。我们可以将DataSet或DataStream转成Table;同
w397090770
10年前 (2016-06-16) 4345℃ 0评论
5喜欢
昨天我提到了如何在《Flink Streaming中实现多路文件输出(MultipleTextOutputFormat)》,里面我们实现了一个MultipleTextOutputFormatSinkFunction类,其中封装了mutable.Map[String, TextOutputFormat[String]],然后根据key的不一样选择不同的TextOutputFormat从而实现了文件的多路输出。本文将介绍如何在Flink batch模式下实现文件的多路输出,这种模式下比较简单
w397090770
10年前 (2016-05-11) 4243℃ 3评论
6喜欢
有时候我们需要根据记录的类别分别写到不同的文件中去,正如本博客的 《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(二)》以及《Spark多文件输出(MultipleOutputFormat)》等文章提到的类似。那么如何在Flink Streaming实现类似于《Spark多文件输出(MultipleOutputFormat)》文
w397090770
10年前 (2016-05-10) 8466℃ 4评论
7喜欢
本文将介绍如何通过Flink读取Kafka中Topic的数据。
和Spark一样,Flink内置提供了读/写Kafka Topic的Kafka连接器(Kafka Connectors)。Flink Kafka Consumer和Flink的Checkpint机制进行了整合,以此提供了exactly-once处理语义。为了实现这个语义,Flink不仅仅依赖于追踪Kafka的消费者group偏移量,而且将这些偏移量存储在其内部用于追踪。
和Sp
w397090770
10年前 (2016-05-03) 24125℃ 1评论
23喜欢
Flink可以在单台机器上运行,甚至是单个Java虚拟机(Java Virtual Machine)。这种机制使得用户可以在本地测试或者调试Flink程序。本节主要概述Flink本地模式的运行机制。
本地环境和执行器(executors)运行你在本地的Java虚拟机上运行Flink程序,或者是在属于正在运行程序的如何Java虚拟机上。对于大部分示例程序而言,你只需简单
w397090770
10年前 (2016-04-27) 16673℃ 0评论
19喜欢
Flink内置支持交互式的Scala Shell,我们既可以在本地安装模式下或者集群模式下运行它。我们可以通过下面的命令在单机模式下启动Shell:
[code lang="scala"]
bin/start-scala-shell.sh local
[/code]
同样,我们可以通过启动Shell时指定remote参数,并提供JobManager的hostname和port等信息,如下:
[code lang="scala"]
bin/start-scala-shell.sh remote <hostnam
w397090770
10年前 (2016-04-26) 6439℃ 0评论
4喜欢
为了保存Scala和Java API之间的一致性,一些允许Scala使用高层次表达式的特性从批处理和流处理的标准API中删除。
如果你想体验Scala表达式的全部特性,你可以通过隐式转换(implicit conversions)来加强Scala API。
为了使用这些扩展,在DataSet API中,你仅仅需要引入下面类:
[code lang="scala"]
import org.apache.flink.api.scala.extensio
w397090770
10年前 (2016-04-25) 3943℃ 0评论
3喜欢