本文作者:王祥虎,原文链接:https://mp.weixin.qq.com/s/LvKaj5ytk6imEU5Dc1Sr5Q,欢迎关注 Apache Hudi 技术社区公众号:ApacheHudi。Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢 w397090770 5年前 (2020-10-09) 1889℃ 0评论2喜欢
大数据处理技术现今已广泛应用于各个行业,为业务解决海量存储和海量分析的需求。但数据量的爆发式增长,对数据处理能力提出了更大的挑战,同时对时效性也提出了更高的要求。业务通常已不再满足滞后的分析结果,希望看到更实时的数据,从而在第一时间做出判断和决策。典型的场景如电商大促和金融风控等,基于延迟数 w397090770 5年前 (2020-06-08) 3987℃ 0评论3喜欢
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3508℃ 0评论3喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 6年前 (2019-09-23) 12633℃ 0评论34喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 6年前 (2019-08-13) 5711℃ 2评论33喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,Ververica(Apache Flink 商业母公司)、腾讯、Google、Airbnb以及 Uber 等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大厂围绕Flink生 w397090770 6年前 (2019-04-20) 3514℃ 0评论11喜欢
“数据智能” (Data Intelligence) 有一个必须且基础的环节,就是数据仓库的建设,同时,数据仓库也是公司数据发展到一定规模后必然会提供的一种基础服务。从智能商业的角度来讲,数据的结果代表了用户的反馈,获取结果的及时性就显得尤为重要,快速的获取数据反馈能够帮助公司更快的做出决策,更好的进行产品迭代,实时数 w397090770 6年前 (2019-02-16) 24324℃ 1评论46喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,dataArtisans(Apache Flink 商业母公司),华为、腾讯、滴滴、美团以及字节跳动等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大 w397090770 7年前 (2018-12-22) 4129℃ 0评论17喜欢
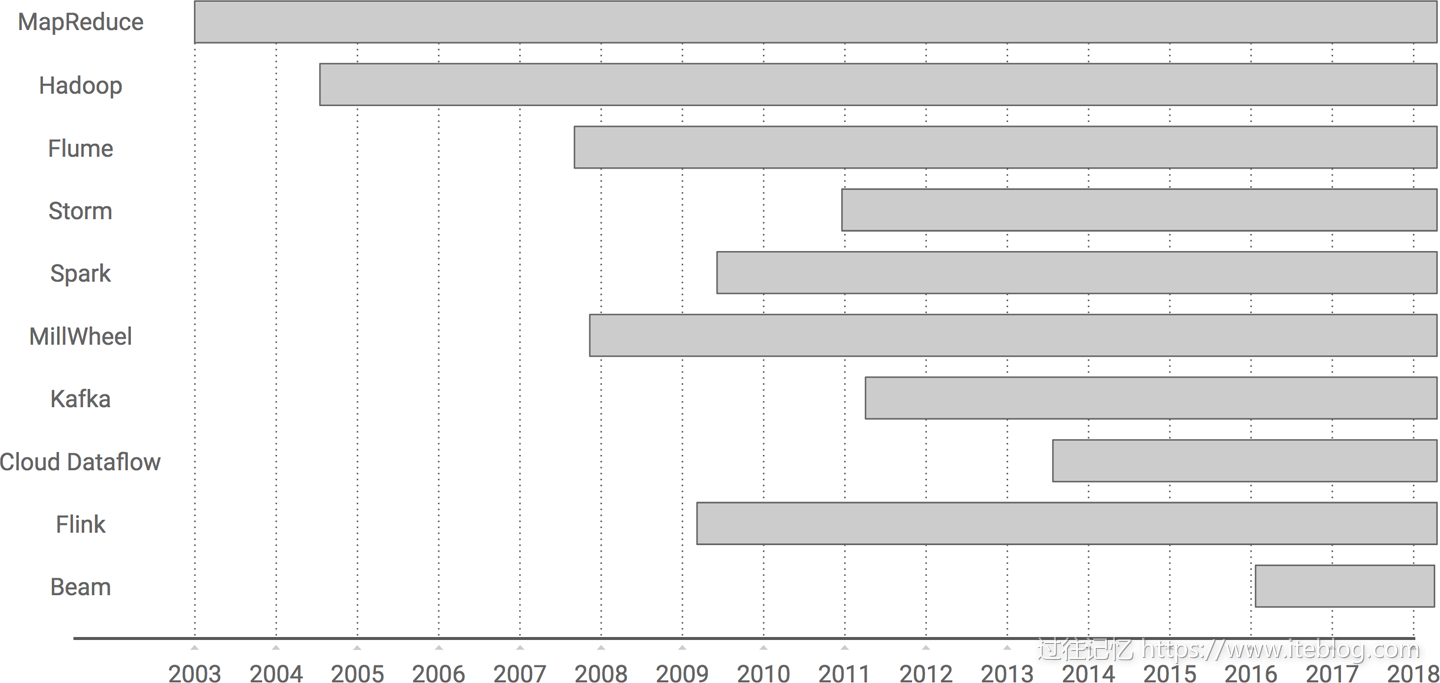
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 7年前 (2018-10-08) 10429℃ 2评论27喜欢
这次整理的 PPT 来自于2018年09月03日至05日在 Berlin 进行的 flink forward 会议,这种性质的会议和大家熟知的Spark summit类似。本次会议的官方日程参见:https://berlin-2018.flink-forward.org/。本次会议共有超过350个 Flink 社区会员的人参与,因为原始的 PPT 是在 http://www.slideshare.net/ 网站,这个网站需要翻墙;为了学习交流的方便,本博客将这些 P w397090770 7年前 (2018-09-19) 2638℃ 2评论5喜欢