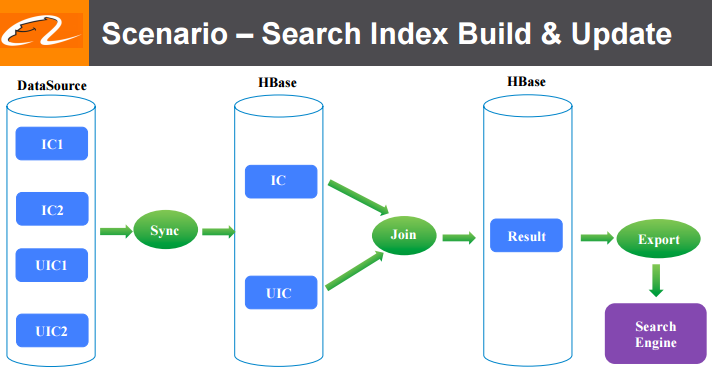
阿里巴巴是世界上最大的电子商务零售商。 我们在2015年的年销售额总计3940亿美元,超过eBay和亚马逊之和。阿里巴巴搜索(个性化搜索和推荐平台)是客户的关键入口,并承载了大部分在线收入,因此搜索基础架构团队需要不断探索新技术来改进产品。 在电子商务网站应用场景中,什么能造就一个强大的搜索引擎?答案 w397090770 7年前 (2017-02-16) 6868℃ 0评论6喜欢
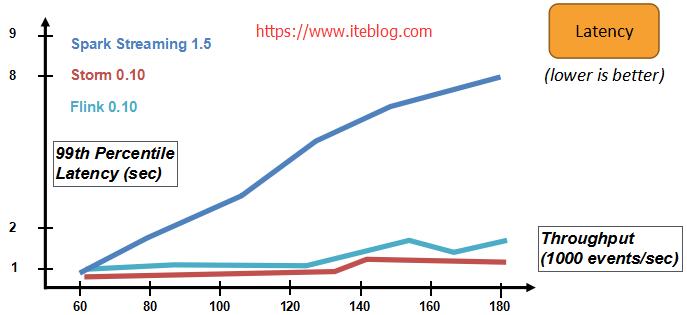
Introduce Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。 容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影 zz~~ 7年前 (2017-02-08) 4542℃ 0评论7喜欢
大家期待已久的Apache Flink 1.2.0今天终于正式发布了。本版本一共解决了650个issues,详细的列表参见这里。Apache Flink 1.2.0是1.x.y系列的第三个主要版本;其API和其他1.x.y版本使用@Public标注的API是兼容的,推荐所有用户升级到此版本。更多关于Apache Flink 1.2.0新功能可以参见Apache Flink 1.2.0新功能概述如果想及时了解Spark、Hadoop或者H w397090770 7年前 (2017-02-07) 1767℃ 6喜欢
好吧,有点标题党了!哈哈,这里介绍的Flink可查询状态提供的功能是有限的,不可能完全替换掉你的数据库(也可以说是持久化存储)。 我在《Apache Flink 1.2.0新功能概述》文章中简单介绍了即将发布的Apache Flink 1.2.0一些比较重要的新功能,其中就提到了Flink 1.2版本的两大重要特性:动态扩展(Dynamic Scaling)和可查询状 w397090770 7年前 (2017-01-15) 4802℃ 0评论4喜欢
Apache Flink 1.1.4于2016年12月21日正式发布,本版本是Flink的最新稳定版本,主要以修复Bug为主;强烈推荐所有的用户升级到Flink 1.1.4版本,替换pom中的以为如下:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.4</version></dependency><dependency> & w397090770 7年前 (2016-12-27) 2268℃ 0评论3喜欢
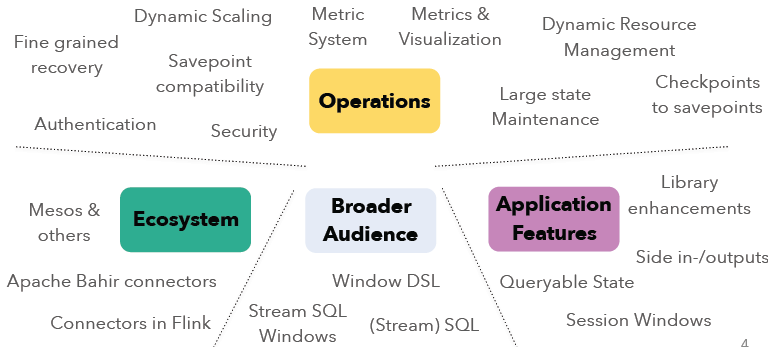
本文将概述即将发布的Apache Flink 1.2.0新功能。在Apache Flink 1.1+版本上,社区主要的集中点在操作性(Operations)、生态系统(Ecosystem)、更广泛的用户(Broader Audience)以及应用特性(Application Features)等方面的开发。各个模块的开发主要包括了如下的方向:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号 w397090770 7年前 (2016-12-18) 2728℃ 0评论4喜欢
Apache Flink开源大数据处理系统最近比较火,特别是其流处理框架的设计。本文并不打算介绍Apache Flink的相关概念,如果你感兴趣可以到本博客的Flink分类目录查看Flink的相关文章。 转入正题了,下面将一步一步教你如何提交你的代码到Flink社区。1、提交Issue 既然能够提交代码肯定是发现了什么Bug,或者有什么好 w397090770 8年前 (2016-11-21) 3339℃ 0评论4喜欢
这本书是市面上第一本系统介绍Apache Flink的图书,书中介绍了为什么选择Apache Flink、流系统架构设计、Flink能做些什么、Flink中是怎么处理时间的、Flink的状态计算等。全书共6章,一共110页。由O'Reilly出版社于2016年10月出版。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[c w397090770 8年前 (2016-11-03) 7819℃ 0评论4喜欢
Apache Flink 1.1.3仍然在Flink 1.1系列基础上修复了一些Bug,推荐所有用户升级到Flink 1.1.3,只需要在你相关工程的pom.xml文件里面加入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.3</version></dependency><dependency> <groupId>org.apache w397090770 8年前 (2016-10-16) 1560℃ 0评论5喜欢
Flink内置提供了将DataStream中的数据写入到ElasticSearch中的Connector(flink-connector-elasticsearch2_2.10),但是并没有提供将DateSet的数据写入到ElasticSearch。本文介绍如何通过自定义OutputFormat将Flink DateSet里面的数据写入到ElasticSearch。 如果需要将DateSet中的数据写入到外部存储系统(比如HDFS),我们可以通过writeAsText、writeAsCsv、write等内 w397090770 8年前 (2016-10-11) 5682℃ 0评论8喜欢




![[电子书]Introduction to Apache Flink PDF下载](https://www.iteblog.com/pic/books/Introduction_to_Apache_Flink_iteblog.jpg)
