时间过得真快,2021年就过去了,又到了一年总结的时候了。本文将延续之前的惯例来总结一下过去一年大数据相关的项目顺利毕业成 Apache 顶级项目。在2021年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® DataSketches™、Apache® Gobblin™、Apache® DolphinScheduler™ 以及 Apache® Pinot™;同时有两个项目进入到 Apache 孵化器, 4年前 (2022-01-03) 1572℃ 0评论6喜欢
Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。如果想及时了解Spark、Hadoop或者HBase相关的文章, 4年前 (2022-01-01) 1398℃ 0评论4喜欢
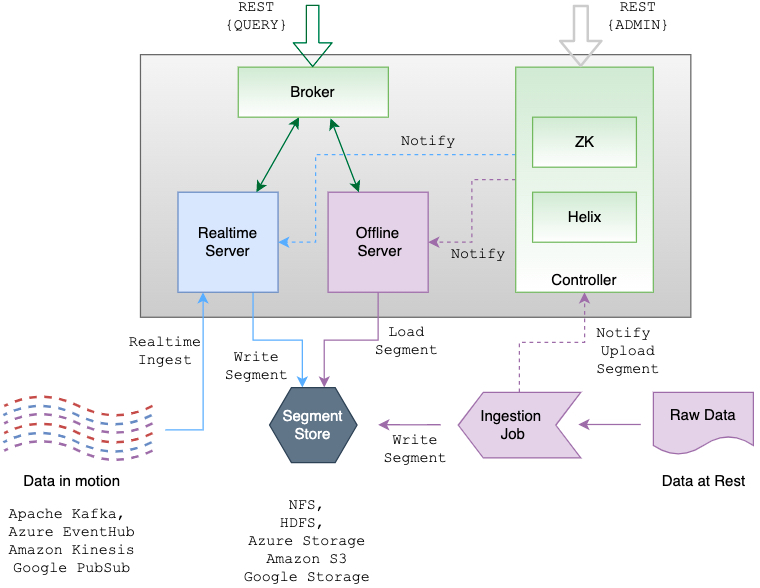
Apache Pinot 是一个分布式实时分布式 OLAP 数据存储,旨在以高吞吐量和低延迟提供可扩展的实时分析。该项目最初于 2013 年由 LinkedIn 创建,2015 年开源,于 2018 年 10 月进入 Apache 孵化器,2021年08月02日正式毕业成为 Apache 顶级项目。Apache Pinot 可以直接从流数据源(例如 Apache Kafka 和 Amazon Kinesis)中提取,并使事件可用于即时查询。 4年前 (2022-01-01) 1142℃ 0评论1喜欢
引言 在字节跳动内部,Presto 主要支撑了 Ad-hoc 查询、BI 可视化分析、近实时查询分析等场景,日查询量接近 100 万条。 功能性方面 完全兼容 SparkSQL 语法,可以实现用户从 SparkSQL 到 Presto 的无感迁移; 性能方面 实现 Join Reorder,Runtime Filter 等优化,在 TPCDS1T 数据集上性能相对社区版本提升 80.5%; 稳定性方面 首先,实 4年前 (2021-12-30) 758℃ 0评论1喜欢
作者:李闯 郭理想 背景 随着有赞实时计算业务场景全部以Flink SQL的方式接入,对有赞现有的引擎版本—Flink 1.10的SQL能力提出了越来越多无法满足的需求以及可以优化的功能点。目前有赞的Flink SQL是在Yarn上运行,但是在公司应用容器化的背景下,可以统一使用公司K8S资源池,同时考虑到任务之间的隔离性以及任务的弹性 4年前 (2021-12-30) 1138℃ 0评论7喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Updates from the New PrestoDB C++ Execution Engine》,分享者为来自 Ahana 的 Deepak Majeti 以及来自 Intel 的 Dave Cohen, Intel。 本次分享的 PPT 请关注 过往记忆大数据 公众号,并回复 10108 获取。 这篇分享将给大家概述代号为 Prestissimo 项目的相关最新进展。Presti 4年前 (2021-12-27) 1709℃ 0评论1喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Tencent at Scale Usability Extension Stability Improvement》,分享者Junyi Huang 和 Pan Liu,均为腾讯软件工程师。Presto 已被腾讯采用为不同业务部门提供临时查询和交互式查询场景。在这次演讲中,作者将分享腾讯在生产中关于 Presto 的实践。关注 过往记忆大数据公众 4年前 (2021-12-19) 828℃ 0评论0喜欢
PrestoCon 2021 于2021年12月09日通过在线的形式举办完了。在 PrestoCon,来自行业领先公司的用户分享了一些用例和最佳实践,Presto 开发人员讨论项目的特性;用户和开发人员将合作推进 Presto 的使用,将其作为一种高质量、高性能和可靠的软件,用于支持全球组织的分析平台,无论是在本地还是在云端。本次会议大概有20多个议题,干货 4年前 (2021-12-19) 398℃ 0评论3喜欢
本文来自 Data + AI Summit 2021 会议中 Facebook 的Rongrong Zhong(Facebook Presto 团队的 TL) 和 Tejas Patil(Facebook Spark 团队的 TL) 工程师带来的名为 《Portable UDFs : Write Once, Run Anywhere》的分享。 虽然大多数查询引擎都提供了丰富的内置函数,但它并不能满足用户的所有需求。在这种情况下,用户定义函数(UDF)允许用户表达他们的业 4年前 (2021-12-17) 566℃ 0评论2喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto 4年前 (2021-12-14) 827℃ 0评论1喜欢