


本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto 的用法,增强了 presto 的稳定性。
关注 过往记忆大数据公众号回复 10099 获取本文资料。
Presto 在字节跳动 OLAP 平台的状况
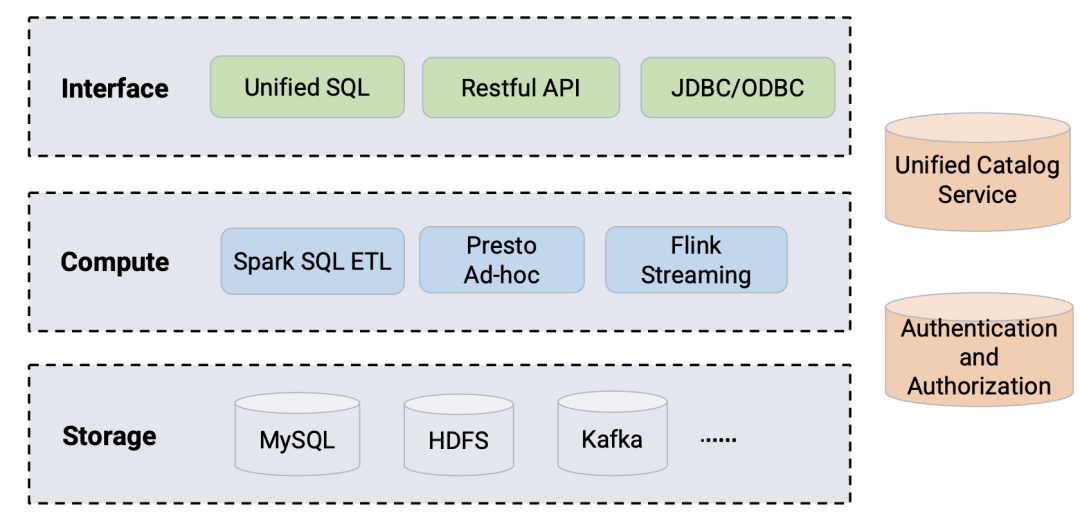
上面是字节跳动计算平台的状况。可以看到,Spark SQL 主要用于 ETL,Presto 处理 Ad-hoc 查询,而 Flink Streaming 处理流数据。
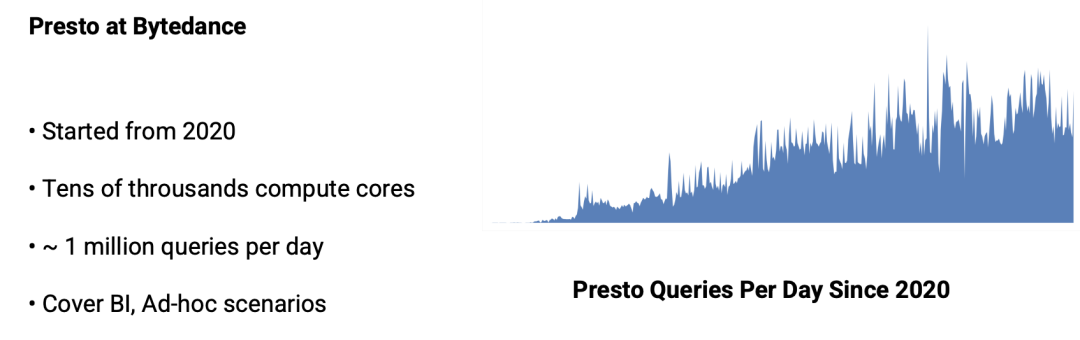
•Presto 在字节是从 2020 年开始使用的;
•当前数以万计的计算核心;•每天大约 100 万次查询;•覆盖 BI、Ad-hoc 等场景。
从右边的图可以看出,Presto 每天的查询量是往上增的趋势。
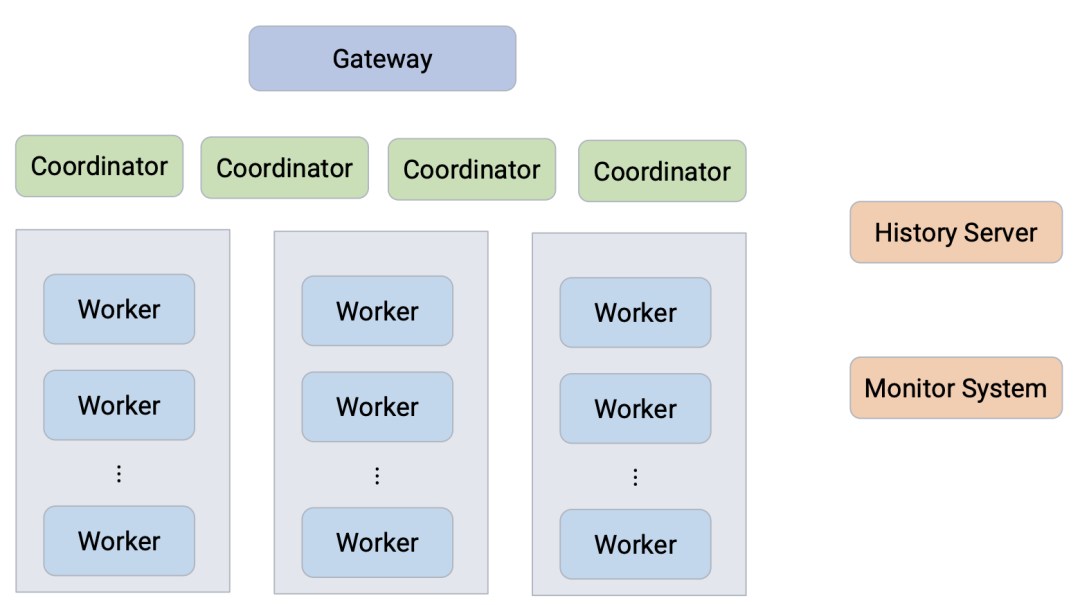
上图是字节跳动的 Presto 集群架构,所有查询都是先经过网关,然后发送到背后的不同 Presto 集群。
Presto 集群稳定性和性能提升
下面我们来看下字节跳动对 Presto 做的改进。
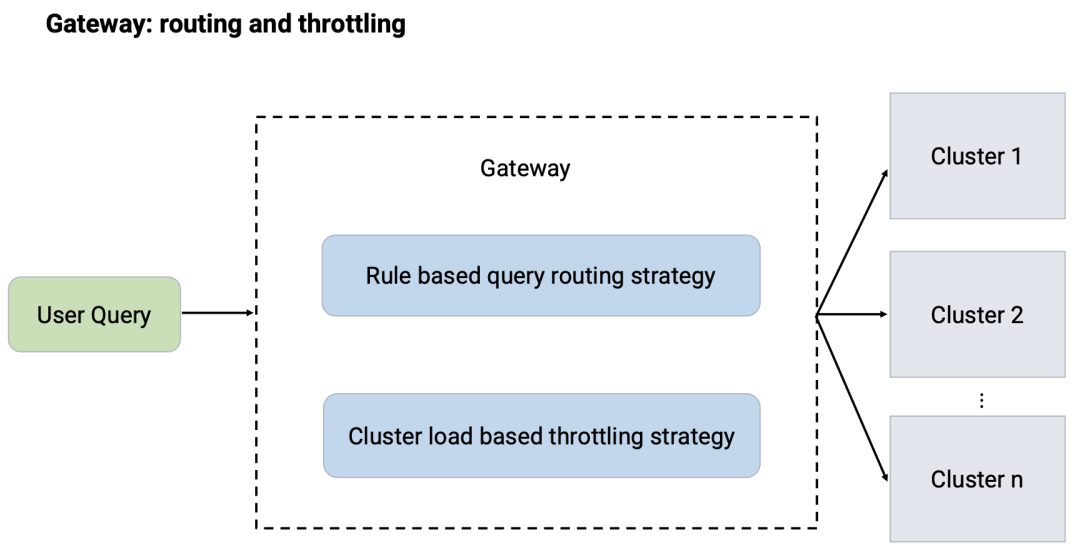
Presto 网关负责查询的路由和流量控制。其中:
•路由策略是基于规则的;•流量控制策略是基于集群负载。
网关负载利用这两个规则将用户的查询转发到不同的 Presto 集群。
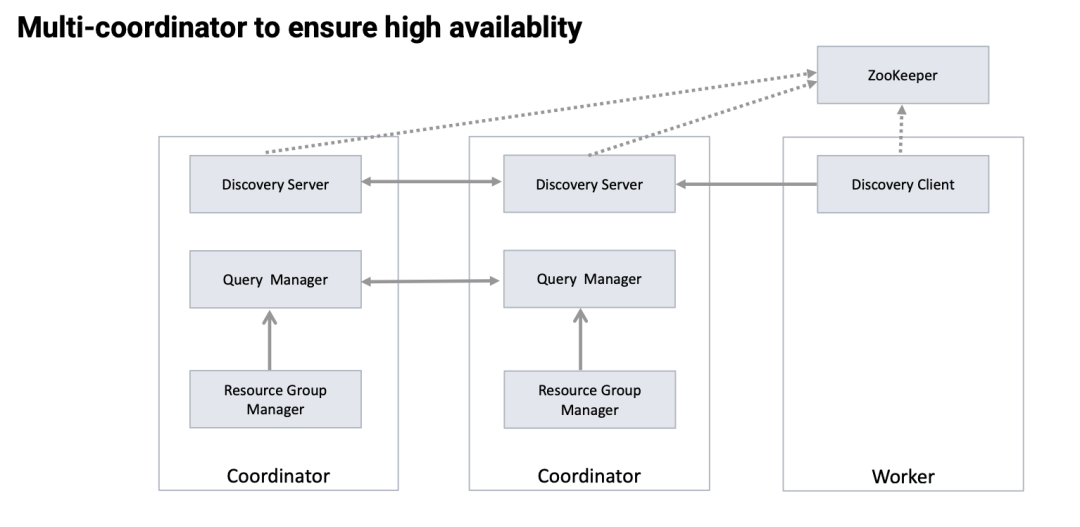
为了高可用性,字节改造 Presto 集群,通过 ZK 实现了 Multi Coordinator。
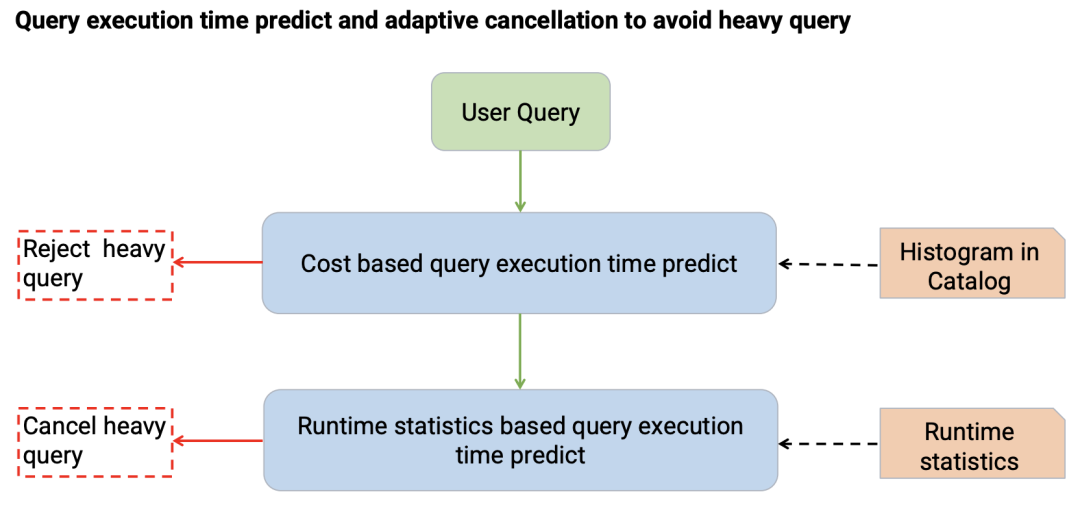
同时,根据 Catalog 里面的统计信息,可以预估用户查询的运行时间,有些大查询可以直接拒绝。同时根据运行时统计信息,可以自动取消大查询。
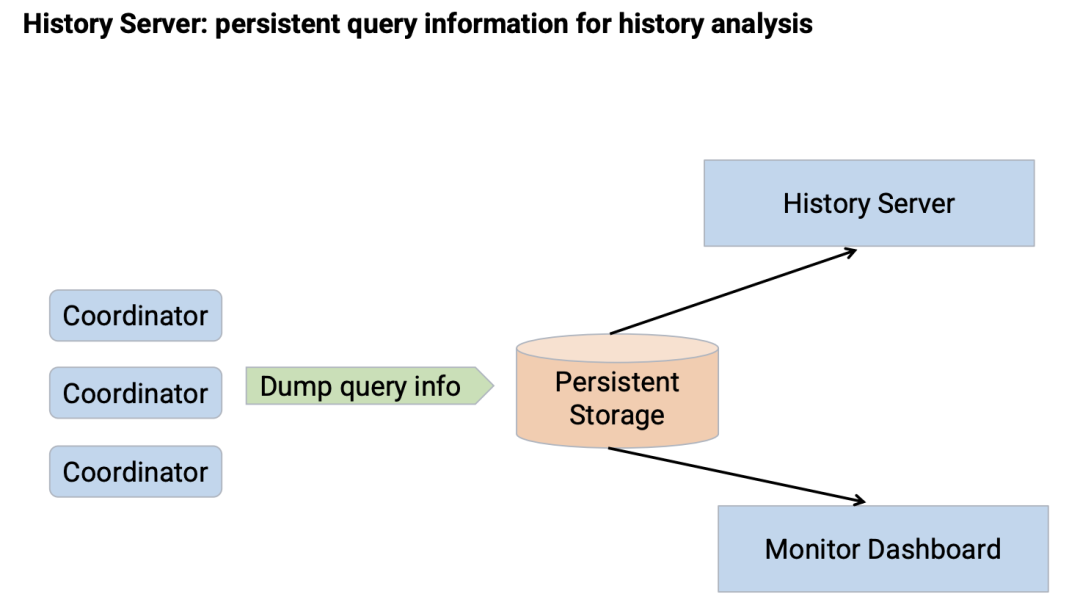
为了分析历史查询,字节内部实现了历史服务器,其核心思想是通过 Coordinator 将查询的信息 dump 到持久化存储,然后 History Server 就可以分析相关历史查询。同时监控 Dashboard 也可以做一些监控相关的工作。
不同场景下的实践和优化
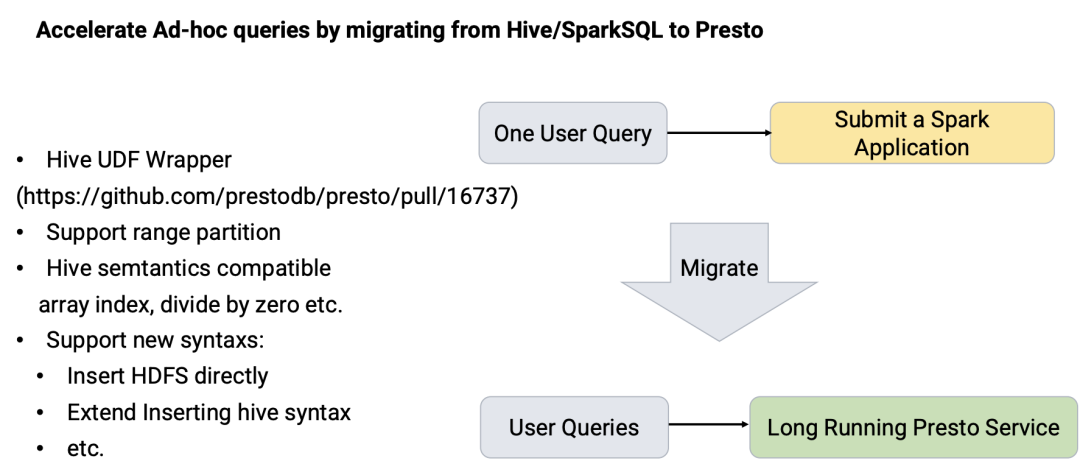
通过将 Hive/Spark SQL 迁移到 Presto 来加速 Ad-hoc 查询。主要做了以下方面的工作:
•Hive UDF Wrapper,其目的是使得 Presto 可以运行 Hive 的 UDF。代码已经开源了,参见:https://github.com/prestodb/presto/pull/16737 • 支持范围分区; • Hive 语义兼容,比如 array index, divide by zero etc. • 支持新语法:直接往 HDFS 插入数据;扩展 Hive insert 语法;
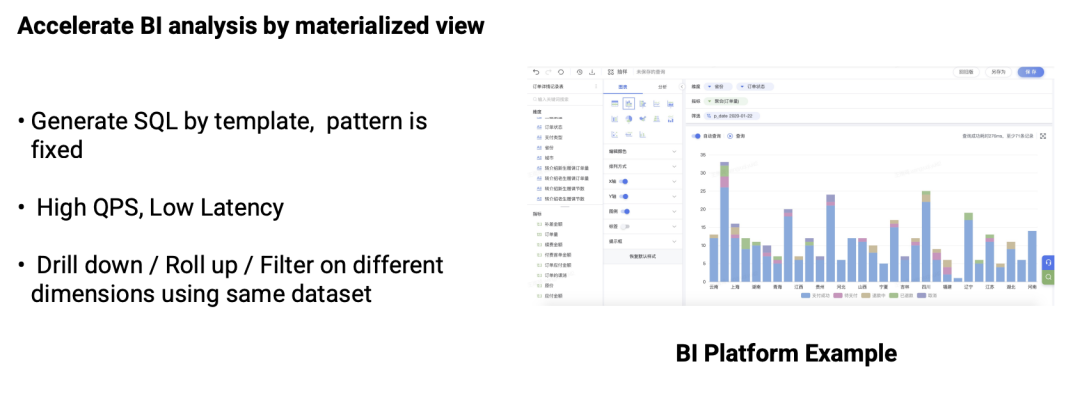
通过物化视图加速 BI 分析。
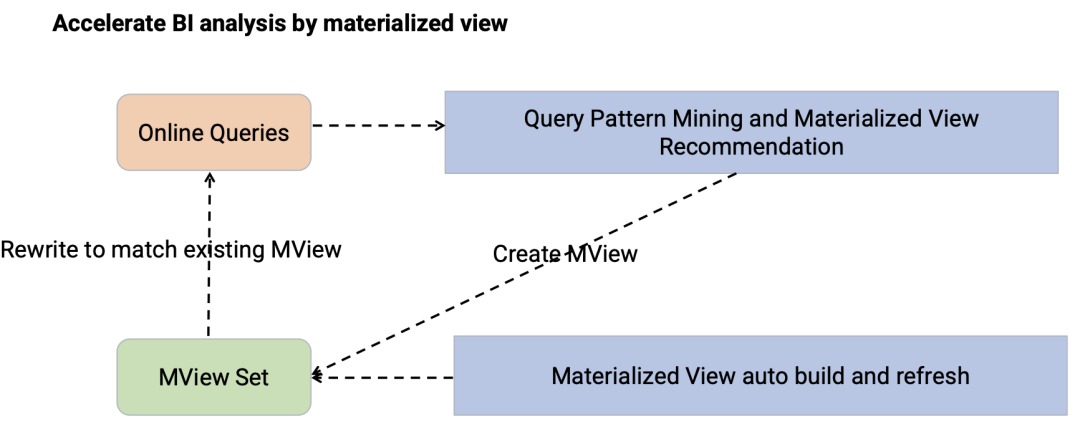
当来了新查询时,利用物化视图集重写查询。下面是两个使用物化视图集改写查询的例子:

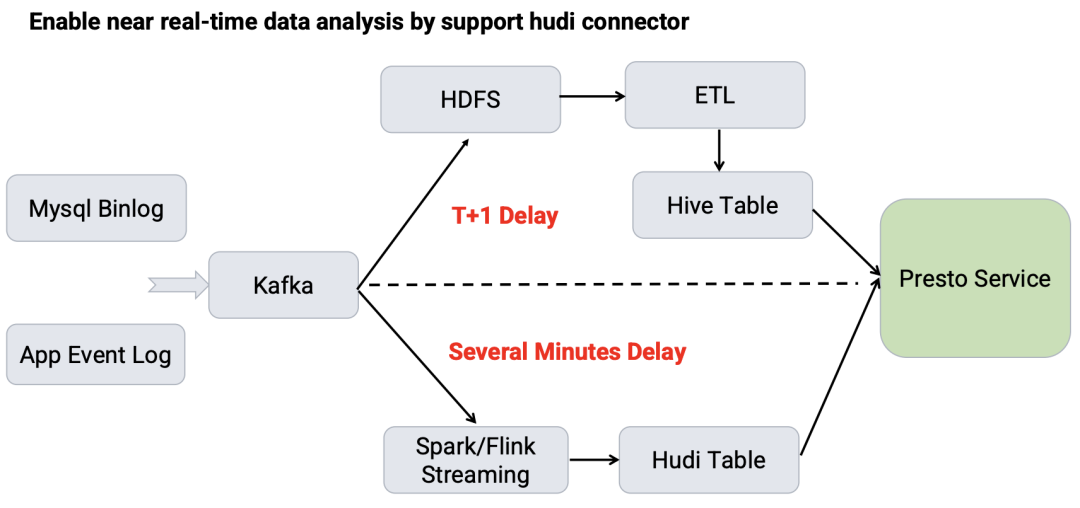
通过 Hudi 数据源支持近实时数据分析。比如可以将 MySQL Binlog 和应用程序的日志发送到 Kafka,并通过两条流把数据持久化:通过 T+1 把数据写到 HDFS,然后经过 ETL 写入到 Hive 表供 Presto 服务查询。另外,通过 Spark/Flink Streaming 近实时的把数据写到 Hudi 表。
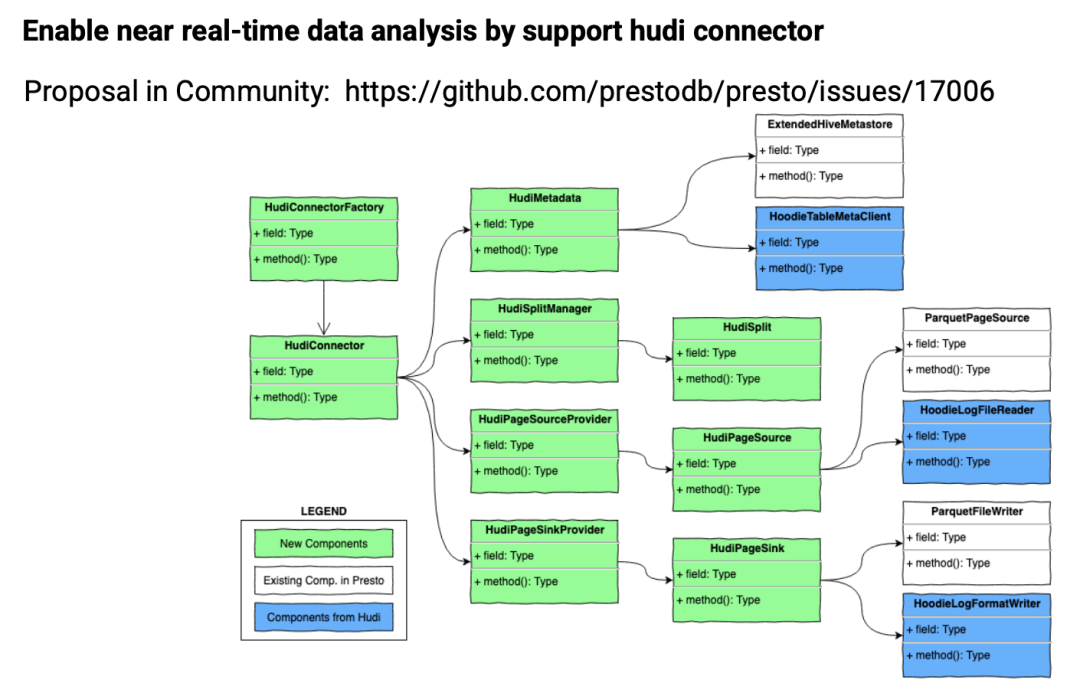
目前 Presto 中的 Hudi 数据源是和 Hive 数据源写到一起的,为了更好的扩展性、可维护性以及性能。字节给 Presto 社区提了一个 Proposal,来将 Hudi 数据源拆分到单独的数据源。感兴趣的同学可以到 https://github.com/prestodb/presto/issues/17006 里面查看详情。
未来规划

原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Presto 在字节跳动的实践】(https://www.iteblog.com/archives/10106.html)







