Apache HAWQ(incubating)的第一个版本受益于ASF(Apache software foundation)组织,通过将MPP(Massively Parallel Processing)和批处理系统(batch system)有效的结合,在性能上有了很大的提升,并且克服了一些关键的限制问题。一个新的重新设计的执行引擎在以下的几个问题在总体系统性能上有了很大的提高:
- 硬件错误引起的短板问题(straggler)
- 并发限制
- 存储中间数据的必要
- 扩展性
- 执行速度
Pivotal HAWQ的开发工作基于GreenPlum数据库的一个分支,至今(2016年8月)已经有超过3年了。最主要的目的就是在Hadoop集群上运行SQL语句查询存储于HDFS上的数据。在三年前的第一个公开的发行版中已经介绍了HAWQ的很多改进手段。但是对于查询执行引擎来说,Pivotal HAWQ仍然使用的是和GreenPlum一样的架构——MPP执行引擎。
HAWQ的基本代码已经贡献到了ASF项目中,并且保持了Pivotal HDB(我们提供的Hadoop原生SQL的商业支持)的核心部分。这周,Hortonworks刚刚宣布了跟Pivotal合作的使用了HAWQ支持的产品。
在这篇文章中,我将介绍Apache HAWQ新设计架构的核心思想。
译者注:可惜Pivotal HDB早已放弃,不再提供支持.
MPP架构
MPP解决方案的最原始想法就是消除共享资源。每个执行器有单独的CPU,内存和硬盘资源。一个执行器无法直接访问另一个执行器上的资源,除非通过网络上的受控的数据交换。这种资源独立的概念,对于MPP架构来说很完美的解决了可扩展性的问题。
MPP的第二个主要概念就是并行。每个执行器运行着完全一致的数据处理逻辑,使用着本地存储上的私有数据块。在不同的执行阶段中间有一些同步点(我的理解:了解Java Gc机制的,可以对比GC中stop-the-world,在这个同步点,所有执行器处于等待状态),这些同步点通常被用于进行数据交换(像Spark和MapReduce中的shuffle阶段)。这里有一个经典的MPP查询时间线的例子: 每个垂直的虚线是一个同步点。例如:同步阶段要求在集群中”shuffle”数据以用于join和聚合(aggregations)操作,因此同步阶段可能执行一些数据聚合,表join,数据排序的操作,而每个执行器执行剩下的计算任务。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
MPP的设计缺陷
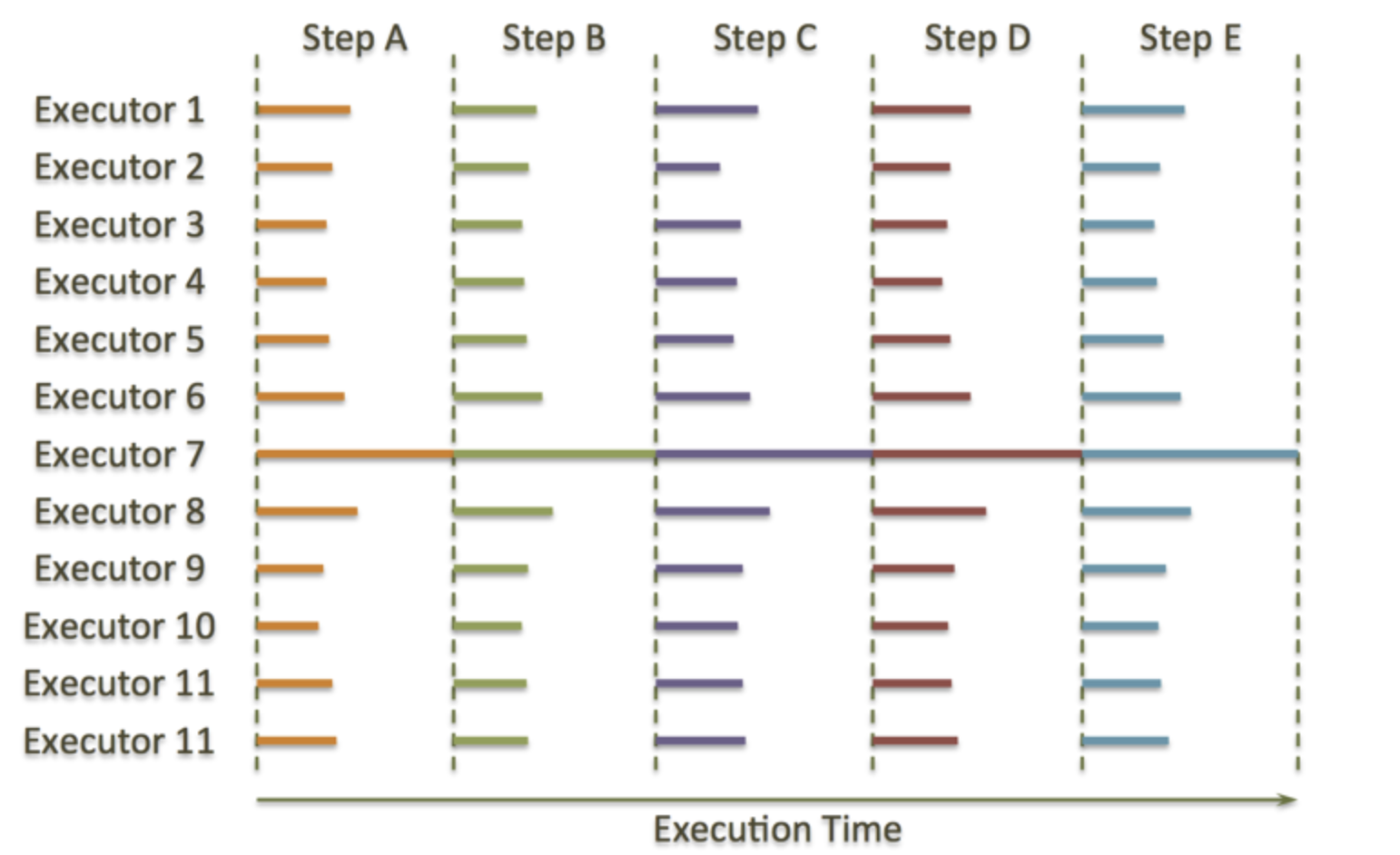
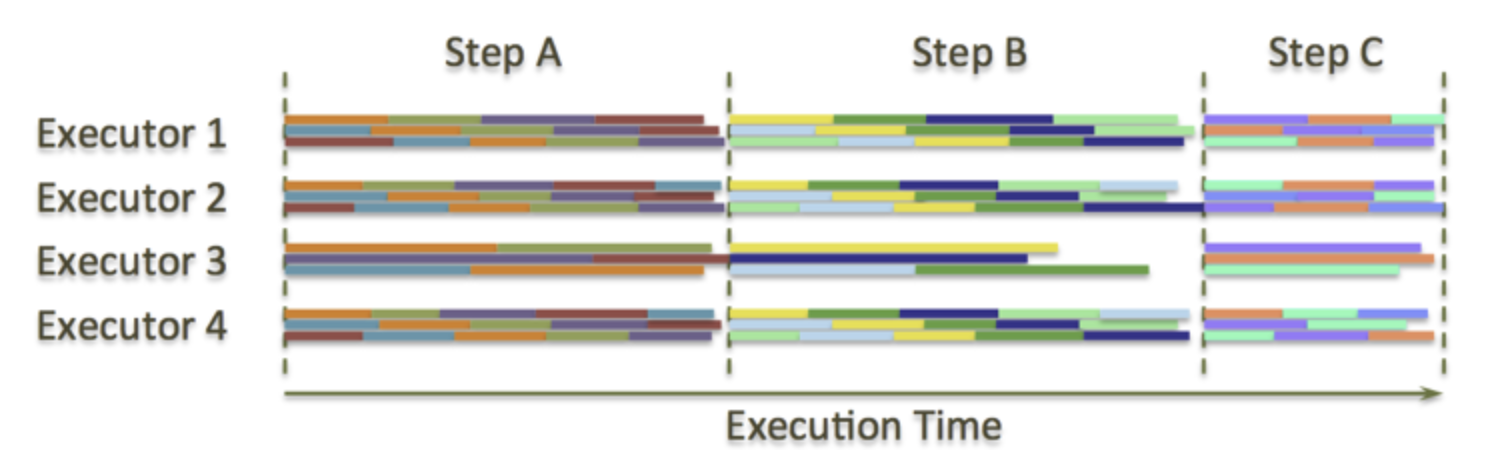
但是,这样的设计对于所有的MPP解决方案来说都有一个主要的问题——短板效应。如果一个节点总是执行的慢于集群中其他的节点,整个集群的性能就会受限于这个故障节点的执行速度(所谓木桶的短板效应),无论集群有多少节点,都不会有所提高。这里有一个例子展示了故障节点(下图中的Executor 7)是如何降低集群的执行速度的。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
大多数情况下,除了Executor 7 其他的所有执行器都是空闲状态。这是因为他们都在等待Executor 7执行完成后才能执行同步过程,这也是我们的问题的根本。比如,当MPP系统中某个节点的RAID由于磁盘问题导致的性能很慢,或者硬件或者系统问题带来的CPU性能问题等等,都会产生这样的问题。所有的MPP系统都面临这样的问题。
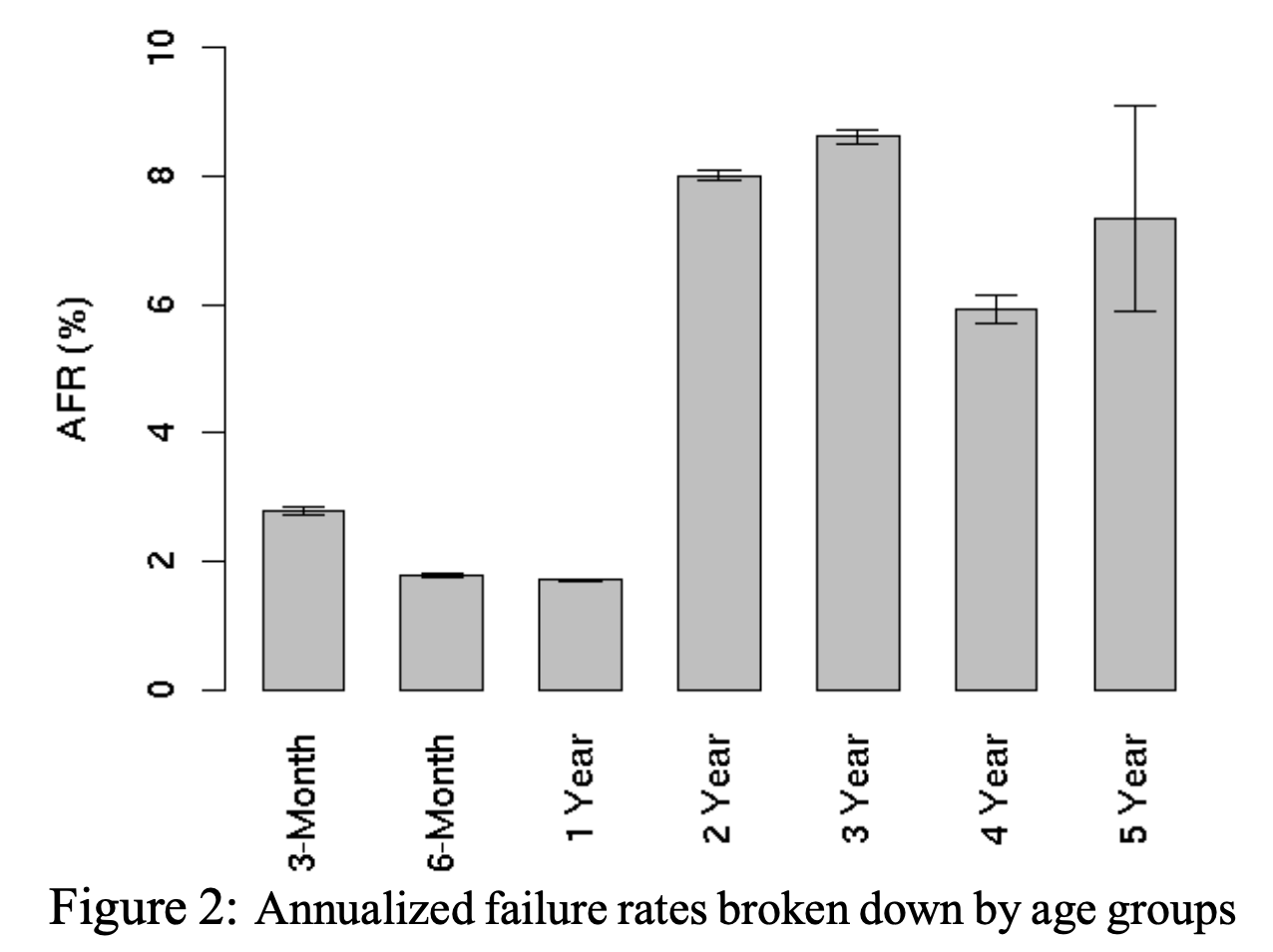
如果你看一下Google的磁盘错误率统计报告,你就能发现观察到的AFR(annualized failure rate,年度故障率)在最好情况下,磁盘在刚开始使用的3个月内有百分之二十会发生故障。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果一个集群有1000个磁盘,一年中将会有20个出现故障或者说每两周会有一个故障发生。如果有2000个磁盘,你将每周都会有故障发生,如果有4000个,将每周会有两次错误发生。两年的使用之后,你将把这个数字乘以4,也就是说,一个1000个磁盘的集群每周会有两次故障发生。
事实上,在一个确定的量级,你的MPP系统将总会有一个节点的磁盘队列出现问题,这将导致该节点的性能降低,从而像上面所说的那样限制整个集群的性能。这也是为什么在这个世界上没有一个MPP集群是超过50个节点服务器的。
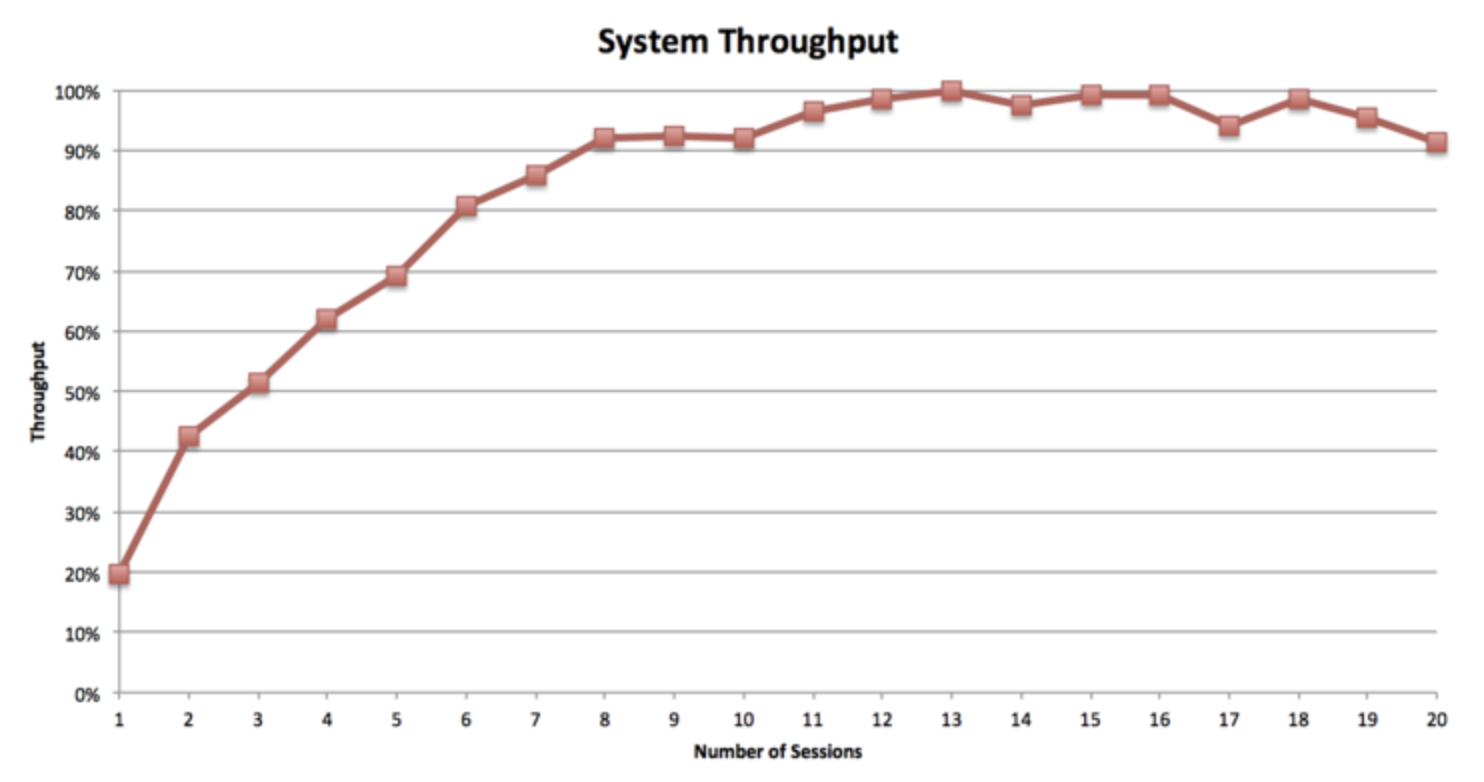
MPP和批处理方案如MapReduce之间有一个更重要的不同就是并发度。并发度就是同一时刻可以高效运行的查询数。MPP是完美对称的,当查询运行的时候,集群中每个节点并发的执行同一个任务。这也就意味着MPP集群的并发度和集群中节点的数量是完全没有关系的。比如说,4个节点的集群和400个节点的集群将支持同一级别的并发度,而且他们性能下降的点基本上是同样。下面是我所说情况的一个例子。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
正如你所见,10-18个并行查询会话产生了整个集群最大的吞吐量。如果你将会话数提高到20个以上的时候,吞吐量将慢慢下降到70%甚至更低。在此声明,吞吐量是在一个固定的时间区间内(时间足够长以产生一个代表性的结果),执行的相同种类的查询任务的数量。Yahoo团队调查Impala并发度限制时产生了一个相似的测试结果。Impala是一个基于Hadoop的MPP引擎。因此从根本上来说,较低的并发度是MPP方案必须承担的以提供它的低查询延迟和高数据处理速度。
批处理架构
为了解决这个问题,伴随着MapReduce论文的发表和其衍生技术的出现,一种新的解决方案诞生。这种设计原则被应用到了Apache Hadoop MapReduce,Apache Spark以及其他的工具上。主要的思想是将两个同步点之间的每个单个的执行阶段(“step”),切分为一系列的独立的”tasks”,”tasks”的数目跟”exexutors”的数量完全没有相关性。比如说,HDFS上,MapReduce的”tasks”数目等于输入文件切片的数量,也就是说等于输入文件所对应的HDFS block数量(单个节点上)。在同步点之间,这些”tasks”被随机的分配在空闲的”executors”上。与此相反,MPP上每个处理数据的task被绑定到持有该数据切片的指定executor上。MapReduce的同步点执行Job的启动,shuffle,和job的停止。对于Apache Spark来说,同步点执行的是Job的启动,shuffle,缓存数据集(dataset),和Job的停止。下图是Apache Spark工作的一个实例,每个不同颜色的bar代表了不同的task,每个executor可以并行的执行3个tasks。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
你可以看到Executor 3是一个故障节点——它执行task的时间大约是其他Executor的两倍慢。但这不是一个问题,Executor 3会慢慢分配到更少的task执行。如果这个问题更加的严重,推测执行将会起作用,速度慢的节点上的task将会在其他节点上重新执行(MapReduce的机制之一,若某个task执行时间过长,会在其他节点上重新运行该task,取最先执行结束的task的结果)。
这项技术(推测执行)之所以可以实施是因为使用了共享存储。为了处理一块数据,你不需要将这块数据存储在你指定的机器上。相反,你可以从远程节点上获取需要的数据块。当然,远程处理相对于本地来说总是更加昂贵的,因为数据需要移动,所以机器节点尽可能的在本地处理数据。但是为了防止故障节点和完成批处理过程,推测执行将解决故障节点的问题,这在MPP中是完全无法解决的。
这里有个云端执行推测执行的研究.

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
这张图表是关于WordCount程序性能的。正如你所见的,在云环境下,推测执行将执行速度加快了2.5倍之多,而云环境的短板效应是众所周知的。共享存储和更加细粒度的调度(task))两种技术的结合使得批处理系统比MPP集群具有更好的可扩展性——可以支持上千个节点和上万个HDD。
批处理架构的问题
但是,每件事都是有代价的,MPP上你不需要将中间数据写入HDD因为一个单一的Executor只处理一个单个的task,因此你可以简单地直接将数据stream到下一个执行阶段。这被叫作”pipelining”,它提供了很大的性能提升。
在大牛博客讨论去中提到,要实现两个大表的join操作,Spark将会写HDD 3次(1. 表1根据join key 进行shuffle 2. 表2根据join key 进行shuffle 3. Hash表写入HDD), 而MPP只需要一次写入(Hash表写入)。这是因为MPP将mapper和reducer同时运行,而MapReduce将它们分成有依赖关系的tasks(DAG),这些task是异步执行的,因此必须通过写入中间数据共享内存来解决数据的依赖。
当你有一些不相关的tasks,且它们可以顺序的在单一的Executor上执行时,就像批处理那样,你除了将中间数据存储到本地磁盘上,别无它选。下一个执行阶段将会从本地磁盘读取中间数据并进行处理。这也是使得系统变慢的原因。
根据我的经验所知,将一个现代的MPP系统和Spark在一个相同的硬件集群上进行性能比较的话,Spark通常是慢3-5倍的。50个机器的MPP集群将会提供大约250个节点的Spark相同的处理能力,但Spark可以扩展到250个节点以上,这对于MPP来说是不可能的。
将MPP和Batch进行结合
我们现在可以看到两个架构的优点和短板。MPP是更快的,但是有两个关键痛点——短板效应和并发限制。而对于像MapReduce这样的批处理系统,我们需要花费时间来存储中间数据到磁盘上,但与此同时,我们获得了更高的扩展度而因此可以获得远远大于MPP的集群规模。我们如何才能将两者结合来获得MPP低延迟和高速处理,使用batch-like的设计来降低短板效应和并发度低的问题?我想如果我告诉你答案是新的Apache HAWQ的架构你是不会惊讶的。
再一次提出问题,MPP的查询是如何执行的?通过一定数量的平行执行的进程运行完全相同的代码,进程数目和集群的节点数量是完全一致的,在每个节点上处理本地数据。但是,当我们介绍HDFS的时候,你不会把数据和本地Executor绑定在一起,这也就意味着你可以摆脱Executor数目的限制,你也就不需要在固定的节点上处理本地存在的数据(在传统MPP上,你不能处理远程节点的数据).为什么?因为HDFS默认对同样的block存储3个备份,也就意味着集群中至少有3个节点上,你可以选择创建一个Executor并处理本地的数据。并且,HDFS支持远程读取数据,也就意味着至少有两个机架上可以处理本地机架上的数据,这样就可以通过最少的拓扑数来远程获取数据。
这也就是为什么Apache HAWQ提出了”virtual segments”的概念——GreenPlum中的”segment” 是改进版的PostgreSQL数据库中的一个单一实例,它在每个节点上存在一个,并且在每次查询中产生”executor”进程。如果你有一个小的查询,它可以被4个executors执行甚至是一个。如果你有一个大的查询,你可以用100个甚至1000个executor执行。每个查询仍然是以MPP风格对本地数据进行处理,而且不需要将中间数据写入到HDD上,但是”virtual segments”允许executor运行在任何地方。下面是它的一个工作示例图(不同颜色代表了不同的查询,虚线代表了查询中的shuffle操作)
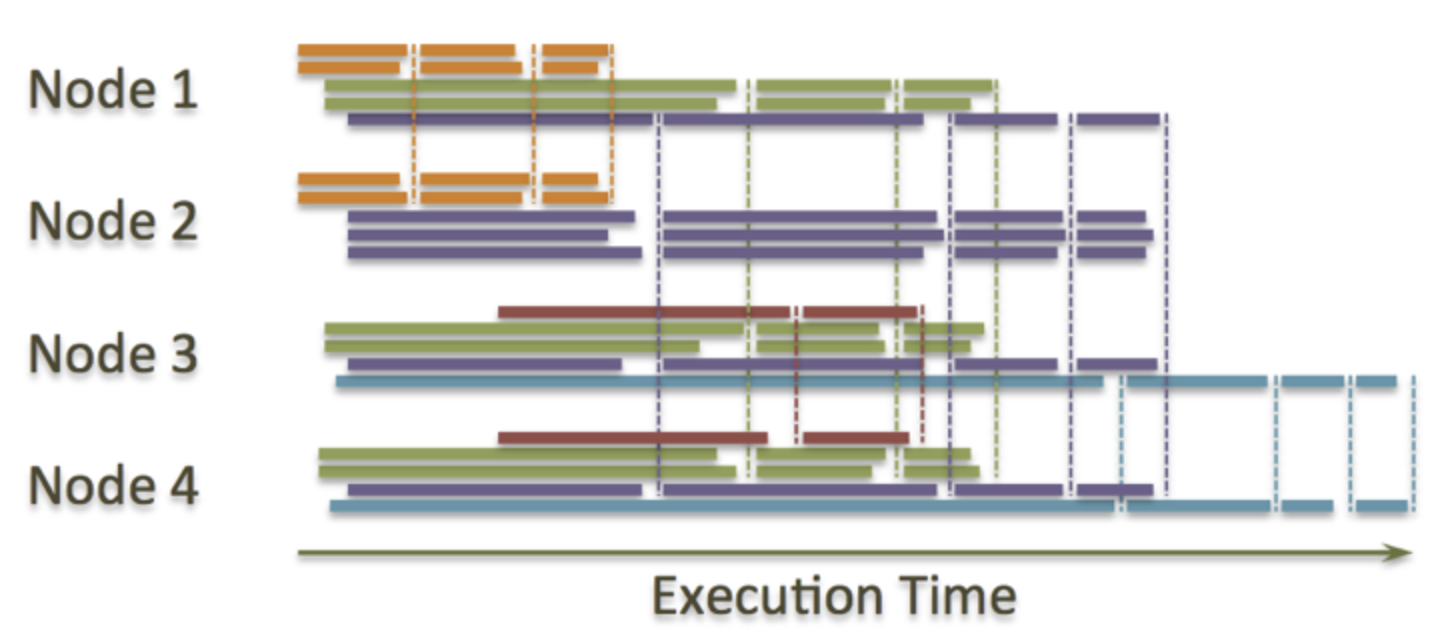
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
这赋予了你以下的特性:
- 减轻MPP系统的短板问题:因为我们可以动态的添加节点和删除节点。因此,严重的磁盘故障将不会影响整个集群的性能,系统可以拥有比传统MPP更大量级的集群。现在,我们可以暂时的将一个故障节点从集群中移除,那么就不会有更多的executor在上面开始运行。并且,移除节点时不会有停机时间。
- 一次查询现在被一个动态数量的executors进行执行,这也就带来了更高的并发度,缓和了MPP系统的限制并加入了batch系统的灵活性。想象一下拥有50个节点的集群,每个节点最多可以运行200个并行的进程。这就意味着你一共拥有了”50*200=10,000”个”execution slot”。你可以对20个查询每个执行500个executor,也可以对200个查询每个执行50个executor,甚至于你可以对1个查询运行10000个executor。在这里是完全灵活可控的。你也可能有一个大的查询要使用4000个segments和600个小的查询每个需要10个executors,这也是可以的。
- 数据管道的完美应用:实时的从一个executor中将数据转移到另一个executor中。在执行阶段,单独的查询仍然是MPP的,而不是batch。因此,不需要将中间数据存储到本地磁盘中(无论何时,操作都允许数据管道)。这意味着我们离MPP的速度更近一步了。
- 像MPP那样,我们仍然尽可能的使用本地数据来执行查询,这一点可以通过HDFS的short-circuit read(当client和数据在同一节点上,可以通过直接读取本地文件来绕过DataNode,参考HDFS Short-Circuit Local Reads)来实现。每个executor会在拥有该文件最多块数的节点上创建并执行,这也最大化了执行效率。
了解更多
Apache HAWQ提出了一种新的设计方案,基本上是MPP和Batch的结合体,包含了两者的优点并抵消了各自的关键缺陷。当然,不存在一个理想的数据处理解决方案——MPP仍然是更快的且Batch仍然有更高的并发度和可扩展性。这也正是为什么为一个特定的场景选择一个特定的方案的关键所在,我们有很多的专家来提供支持。作为深入的了解,你可以阅读Apache HAWQ架构介绍,也可查看这里和这里.
小结
MPP和Batch架构,正在逐渐走向融合,今天在微信圈看到一篇《批处理已死,流处理当道》,唏嘘不已,Batch架构确实在实时响应性方面是缺点,同样的MPP架构由于扩展性和木桶效应导致集群规模不能很大。
如果你对扩展性有着更高要求,可以选择Batch架构,如果你希望提供更快的查询选择MPP架构。我不想过多讨论更多HAWQ(历史包袱),因为SQL on Hadoop已经出现太多失败的项目,而HAWQ的出现给我们提供了新思路和方向,Batch+MPP融合架构。目前基于Hadoop发展起来的各种Batch/Stream/MPP系统都在努力解决问题,为未来新型数据分析方法提供更多样化的解决方案。
包括一个很敏感的话题,Hadoop上云,我们慢慢讨论。
就因为忍受不了Batch系统,我才面带领团队研究DataFlow产品,解决Batch面对今天日益严峻的实时性数据分析响应问题,DataFlow产品会完全取代ETL,让数据一直在流,流动中被处理,并且被高效处理、实时反馈。
我在Clickhouse似乎看到的新型OLAP数据仓库的未来,虽然还有很多缺陷和问题需要解决完善.
目前OLAP分布式计算引擎系统发展的方向:
- Batch MapReduce -> Spark/Tez
- Stream SparkStreaming -> Flink Streams -> Kafka KSQL
- Batch + MPP Greenplum/HP Vertica -> Dremel -> Impala/Drill/PrestoDB/HAWQ
- Real-time Storage(Search/KV) Druid.io/ElesticSearch/CrateDB/Hbase
目前一分钟上百万数据实时入库,实时查询系统属于Real-time Storage(Search/KV)场景。
各种大数据系统和引擎都在不断进化,相互学习融合,界限也许没那么明显,大量淘沙,相信最后留下来的都是被市场认可能带来高价值的系统。
我目前在研发的DataFlow属于Stream + New MPP架构,我构想的是支持海量的IOT设备实时数据处理反馈,提供可视化操作。
参考
- http://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
- https://0x0fff.com/hadoop-vs-mpp/
- https://0x0fff.com/apache-spark-future/
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【MPP 和 Batch 架构优缺点对比】(https://www.iteblog.com/archives/9984.html)