从Apache Zeppelin 0.5.6 版本开始,内置支持 Elasticsearch Interpreter了。我们可以直接在Apache Zeppelin中
查询 ElasticSearch 中的数据。但是默认的 Apache Zeppelin 发行版本中可能并没有包含 Elasticsearch Interpreter。这种情况下我们需要自己安装。如果你参照了官方的这篇文档,即使你全部看完这篇文档,也是无法按照上面的说明启用 Elasticsearch Interpreter 的!所以基于这种情况,本文将教大家在 Apache Zeppelin中安装Elasticsearch Interpreter。下面的安装教程是基于 Apache Zeppelin 0.7.2 版本。
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
安装Elasticsearch Interpreter
安装的命令其实很简单,我们只需要在 Apache Zeppelin 的安装目录下执行下面的命令即可安装好,操作如下:
[iteblog@www.iteblog.com zeppelin-0.7.2-bin-netinst]$ ./bin/install-interpreter.sh --name elasticsearch
如果运行完上面的命令得到类似于如下的输出信息,说明 Elasticsearch Interpreter 已经成功安装成功。
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512m; support was removed in 8.0 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/iteblog/zeppelin-0.7.2-bin-netinst/lib/interpreter/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/iteblog/zeppelin-0.7.2-bin-netinst/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Install elasticsearch(org.apache.zeppelin:zeppelin-elasticsearch:0.7.2) to /home/iteblog/zeppelin-0.7.2-bin-netinst/interpreter/elasticsearch ... Interpreter elasticsearch installed under /home/iteblog/zeppelin-0.7.2-bin-netinst/interpreter/elasticsearch. 1. Restart Zeppelin 2. Create interpreter setting in 'Interpreter' menu on Zeppelin GUI 3. Then you can bind the interpreter on your note
然后需要重启 Zeppelin,使得安装生效。
上面的命令其实会在 $ZEPPELIN_HOME/interpreter 目录下创建一个名为 elasticsearch 目录,如下:
[iteblog@www.iteblog.com zeppelin-0.7.2-bin-netinst]$ ll interpreter/ total 8 drwxr-xr-x 2 iteblog iteblog 4096 Jul 5 10:11 elasticsearch drwxr-xr-x 5 iteblog iteblog 4096 Jun 28 2016 spark
这个目录里面包含了所有和 ElasticSearch 相关的类库。
如果你在安装 Elasticsearch Interpreter 出现以下的异常:
[iteblog@www.iteblog.com zeppelin-0.7.2-bin-netinst]$ ./bin/install-interpreter.sh --name elasticsearch Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512m; support was removed in 8.0 SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/iteblog/zeppelin-0.6.0-bin-netinst/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/iteblog/zeppelin-0.6.0-bin-netinst/lib/zeppelin-interpreter-0.6.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Install elasticsearch(org.apache.zeppelin:zeppelin-elasticsearch:0.6.0) to /home/iteblog/zeppelin-0.6.0-bin-netinst/interpreter/elasticsearch ... Exception in thread "main" java.lang.NullPointerException at org.sonatype.aether.impl.internal.DefaultRepositorySystem.resolveDependencies(DefaultRepositorySystem.java:352) at org.apache.zeppelin.dep.DependencyResolver.getArtifactsWithDep(DependencyResolver.java:161) at org.apache.zeppelin.dep.DependencyResolver.loadFromMvn(DependencyResolver.java:114) at org.apache.zeppelin.dep.DependencyResolver.load(DependencyResolver.java:77) at org.apache.zeppelin.dep.DependencyResolver.load(DependencyResolver.java:94) at org.apache.zeppelin.dep.DependencyResolver.load(DependencyResolver.java:86) at org.apache.zeppelin.interpreter.install.InstallInterpreter.install(InstallInterpreter.java:170) at org.apache.zeppelin.interpreter.install.InstallInterpreter.install(InstallInterpreter.java:136) at org.apache.zeppelin.interpreter.install.InstallInterpreter.install(InstallInterpreter.java:128) at org.apache.zeppelin.interpreter.install.InstallInterpreter.main(InstallInterpreter.java:280)
很有可能是执行这个命令的用户对 $ZEPPELIN_HOME/interpreter 目录无写权限。
如果你需要按照其他的 interpreter,可以如下操作:
./bin/install-interpreter.sh --name md,shell,jdbc,python
我们只需要指定相应 interpreter 的名字即可,多个 interpreter 之间使用逗号分隔。
如果需要按照所有的 interpreter,只需要执行下面的命令即可:
./bin/install-interpreter.sh --all
使用Elasticsearch Interpreter
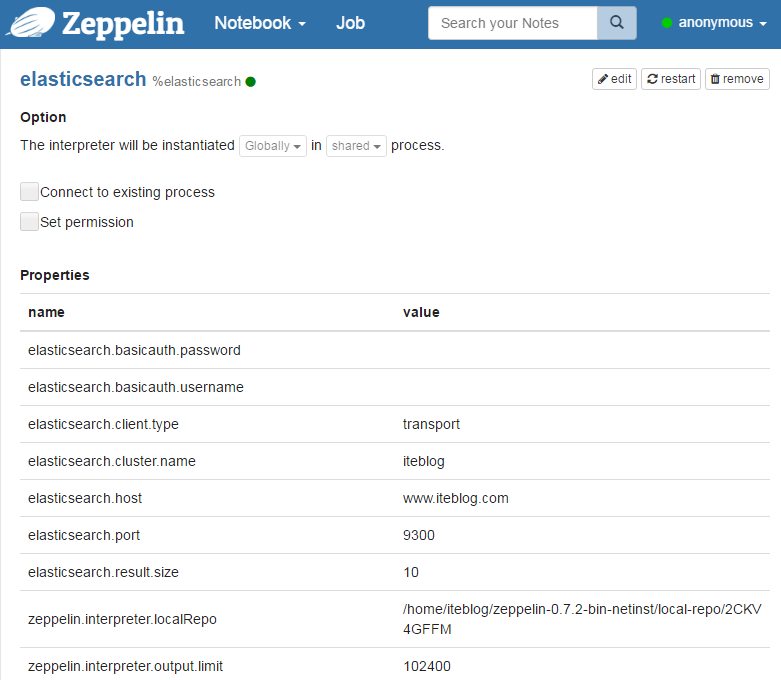
安装完 Elasticsearch Interpreter 之后,我们就可以配置 ElasticSearch 集群相关的参数了。目前支持的参数主要包括下面几个:
| 属性 | 默认值 | 描述 |
|---|---|---|
| elasticsearch.cluster.name | elasticsearch | ElasticSearch 集群的名字 |
| elasticsearch.host | localhost | 集群的节点地址 |
| elasticsearch.port | 9300 | 连接 ElasticSearch 集群的端口 ( 注意: 这个端口和 elasticsearch.client.type 有关) |
| elasticsearch.client.type | transport | Elasticsearch 集群的类型(可选值有 transport 或 http) |
| elasticsearch.basicauth.username | 集群认证的用户名 | |
| elasticsearch.basicauth.password | 集群认证的密码 | |
| elasticsearch.result.size | 10 | 搜索查询结果集的大小 |
我们在 Apache Zeppelin 中 Elasticsearch Interpreter 对应的页面配置好相关的参数,如下所示:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
elasticsearch.host 参数目前不支持设置多个 ElasticSearch 集群的节点,只能设置成一个。设置完之后保存,然后我们再新建一个 notebook,并选择将 Elasticsearch Interpreter 作为默认的 Interpreter,现在我们使用下面的命令查看 Elasticsearch Interpreter 是否设置好:
%elasticsearch
help
Elasticsearch interpreter:
General format: <command> /<indices>/<types>/<id> <option> <JSON>
- indices: list of indices separated by commas (depends on the command)
- types: list of document types separated by commas (depends on the command)
Commands:
- search /indices/types <query>
. indices and types can be omitted (at least, you have to provide '/')
. a query is either a JSON-formatted query, nor a lucene query
- size <value>
. defines the size of the result set (default value is in the config)
. if used, this command must be declared before a search command
- count /indices/types <query>
. same comments as for the search
- get /index/type/id
- delete /index/type/id
- index /index/type/id <json-formatted document>
. the id can be omitted, elasticsearch will generate one
如果有上面的输出,那恭喜你了,你的 Elasticsearch Interpreter已经成功安装完成,并已经设置好了。
剩下的操作,诸如查询、更新、删除等操作,请参见官方文档:Elasticsearch Interpreter for Apache Zeppelin,这里就不再介绍了。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【在Apache Zeppelin中安装使用Elasticsearch Interpreter】(https://www.iteblog.com/archives/2186.html)