

文章目录
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。
Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。
Apache Cassandra 是分布式的 NoSQL 数据库。
在这篇文章中,我们将介绍如何通过这三个组件构建一个高扩展、容错的实时数据处理平台。
准备
在进行下面文章介绍之前,我们需要先创建好 Kafka 的主题以及 Cassandra 的相关表,具体如下:
在 Kafka 中创建名为 messages 的主题
$KAFKA_HOME$\bin\windows\kafka-topics.bat --create \ --zookeeper localhost:2181 \ --replication-factor 1 --partitions 1 \ --topic messages
在 Cassandra 中创建 KeySpace 和 table
CREATE KEYSPACE vocabulary
WITH REPLICATION = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};
USE vocabulary;
CREATE TABLE words (word text PRIMARY KEY, count int);
上面我们创建了名为 vocabulary 的 KeySpace,以及名为 words 的表。
添加依赖
我们使用 Maven 进行依赖管理,这个项目使用到的依赖如下:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector-java_2.11</artifactId>
<version>1.5.2</version>
</dependency>
数据管道开发
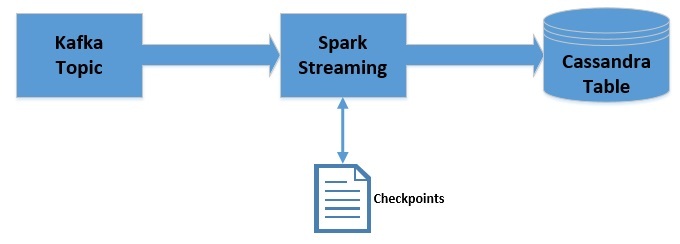
我们将使用 Spark 在 Java 中创建一个简单的应用程序,它将与我们之前创建的Kafka主题集成。应用程序将读取已发布的消息并计算每条消息中的单词频率。 然后将结果更新到 Cassandra 表中。整个数据架构如下:
现在我们来详细介绍代码是如何实现的。
获取 JavaStreamingContext
Spark Streaming 中的切入点是 JavaStreamingContext,所以我们首先需要获取这个对象,如下:
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("WordCountingApp");
sparkConf.set("spark.cassandra.connection.host", "127.0.0.1");
JavaStreamingContext streamingContext = new JavaStreamingContext(
sparkConf, Durations.seconds(1));
从 Kafka 中读取数据
有了 JavaStreamingContext 之后,我们就可以从 Kafka 对应主题中读取实时流数据,如下:
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "localhost:9092");
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "use_a_separate_group_id_for_each_stream");
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("enable.auto.commit", false);
Collection<String> topics = Arrays.asList("messages");
JavaInputDStream<ConsumerRecord<String, String>> messages =
KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String> Subscribe(topics, kafkaParams));
我们在程序中提供了 key 和 value 的 deserializer。这个是 Kafka 内置提供的。我们也可以根据自己的需求自定义 deserializer。
处理 DStream
我们在前面只是定义了从 Kafka 中哪张表中获取数据,这里我们将介绍如何处理这些获取的数据:
JavaPairDStream<String, String> results = messages
.mapToPair(
record -> new Tuple2<>(record.key(), record.value())
);
JavaDStream<String> lines = results
.map(
tuple2 -> tuple2._2()
);
JavaDStream<String> words = lines
.flatMap(
x -> Arrays.asList(x.split("\\s+")).iterator()
);
JavaPairDStream<String, Integer> wordCounts = words
.mapToPair(
s -> new Tuple2<>(s, 1)
).reduceByKey(
(i1, i2) -> i1 + i2
);
将数据发送到 Cassandra 中
最后我们需要将结果发送到 Cassandra 中,代码也很简单。
wordCounts.foreachRDD(
javaRdd -> {
Map<String, Integer> wordCountMap = javaRdd.collectAsMap();
for (String key : wordCountMap.keySet()) {
List<Word> wordList = Arrays.asList(new Word(key, wordCountMap.get(key)));
JavaRDD<Word> rdd = streamingContext.sparkContext().parallelize(wordList);
javaFunctions(rdd).writerBuilder(
"vocabulary", "words", mapToRow(Word.class)).saveToCassandra();
}
}
);
启动应用程序
最后,我们需要将这个 Spark Streaming 程序启动起来,如下:
streamingContext.start(); streamingContext.awaitTermination();
使用 Checkpoints
在实时流处理应用中,将每个批次的状态保存下来通常很有用。比如在前面的例子中,我们只能计算单词的当前频率,如果我们想计算单词的累计频率怎么办呢?这时候我们就可以使用 Checkpoints。新的数据架构如下
为了启用 Checkpoints,我们需要进行一些改变,如下:
streamingContext.checkpoint("./.checkpoint");
这里我们将 checkpoint 的数据写入到名为 .checkpoint 的本地目录中。但是在现实项目中,最好使用 HDFS 目录。
现在我们可以通过下面的代码计算单词的累计频率:
JavaMapWithStateDStream<String, Integer, Integer, Tuple2<String, Integer>> cumulativeWordCounts = wordCounts
.mapWithState(
StateSpec.function(
(word, one, state) -> {
int sum = one.orElse(0) + (state.exists() ? state.get() : 0);
Tuple2<String, Integer> output = new Tuple2<>(word, sum);
state.update(sum);
return output;
}
)
);
部署应用程序
最后,我们可以使用 spark-submit 来部署我们的应用程序,具体如下:
$SPARK_HOME$\bin\spark-submit \ --class com.baeldung.data.pipeline.WordCountingAppWithCheckpoint \ --master local[2] \target\spark-streaming-app-0.0.1-SNAPSHOT-jar-with-dependencies.jar
最后,我们可以在 Cassandra 中查看到对应的表中有数据生成了。完整的代码可以参见 https://github.com/eugenp/tutorials/tree/master/apache-spark
微信公众号和钉钉群交流
为了营造一个开放的 Cassandra 技术交流,我们建立了微信公众号和钉钉群,为广大用户提供专业的技术分享及问答,定期在国内开展线下技术沙龙,专家技术直播,欢迎大家加入。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【使用 Kafka + Spark Streaming + Cassandra 构建数据实时处理引擎】(https://www.iteblog.com/archives/2602.html)






