本文列出了 kubectl 常用命令。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Kubectl 自动补全BASH[code lang="bash"]source <(kubectl completion bash) # 在 bash 中设置当前 shell 的自动补全,要先安装 bash-completion 包。echo "source <(kubectl completion bash)" >> ~/.bashrc # 在您的 bash shell 中永久 2年前 (2022-02-28) 292℃ 0评论1喜欢
本文我们将花点时间来回顾一下 Databricks 和 Apache Spark™ 在流数据处理方面所取得的巨大进步!2021年,工程团队和开源贡献者在以下三个目标取得了一些进展:降低延迟并改进有状态流处理;提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性;改进资源分配和可伸缩性。下面我们来简单地看下这些目标。目标一: 2年前 (2022-02-23) 759℃ 0评论3喜欢
数据处理现状:当前基于Hive的离线数据仓库已经非常成熟,数据中台体系也基本上是围绕离线数仓进行建设。但是随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于两个相关的热点问题:实时数仓建设和大数据架构的批流一体建设。实时数仓建设:实时数仓1.0 传统 2年前 (2022-02-18) 595℃ 0评论1喜欢
分享嘉宾:Xiaochun He OPPO,编辑整理:门君仪 澳洲国立大学 导读:OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次 2年前 (2022-02-18) 378℃ 0评论1喜欢
摘要:本文整理自快手实时计算团队技术专家张静、张芒在 Flink Forward Asia 2021 的分享。主要内容包括: Flink SQL 在快手功能扩展性能优化稳定性提升未来展望 一、Flink SQL 在快手 经过一年多的推广,快手内部用户对 Flink SQL 的认可度逐渐提高,今年新增的 Flink 作业中,SQL 作业达到了 60%,与去年相比有了一倍的提升,峰值吞吐 2年前 (2022-02-18) 873℃ 0评论1喜欢
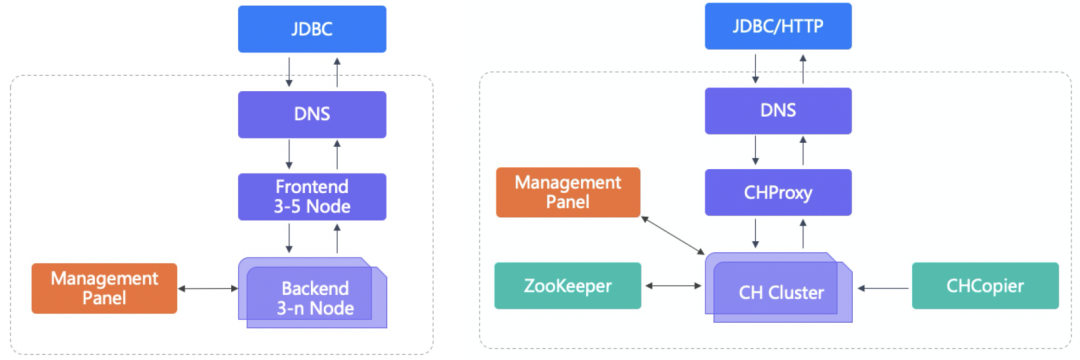
背景介绍Apache Doris是由百度贡献的开源MPP分析型数据库产品,亚秒级查询响应时间,支持实时数据分析;分布式架构简洁,易于运维,可以支持10PB以上的超大数据集;可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。 ClickHouse 是俄罗斯的搜索公司Yadex开源的MPP架构的分析引 2年前 (2022-02-15) 2542℃ 0评论0喜欢
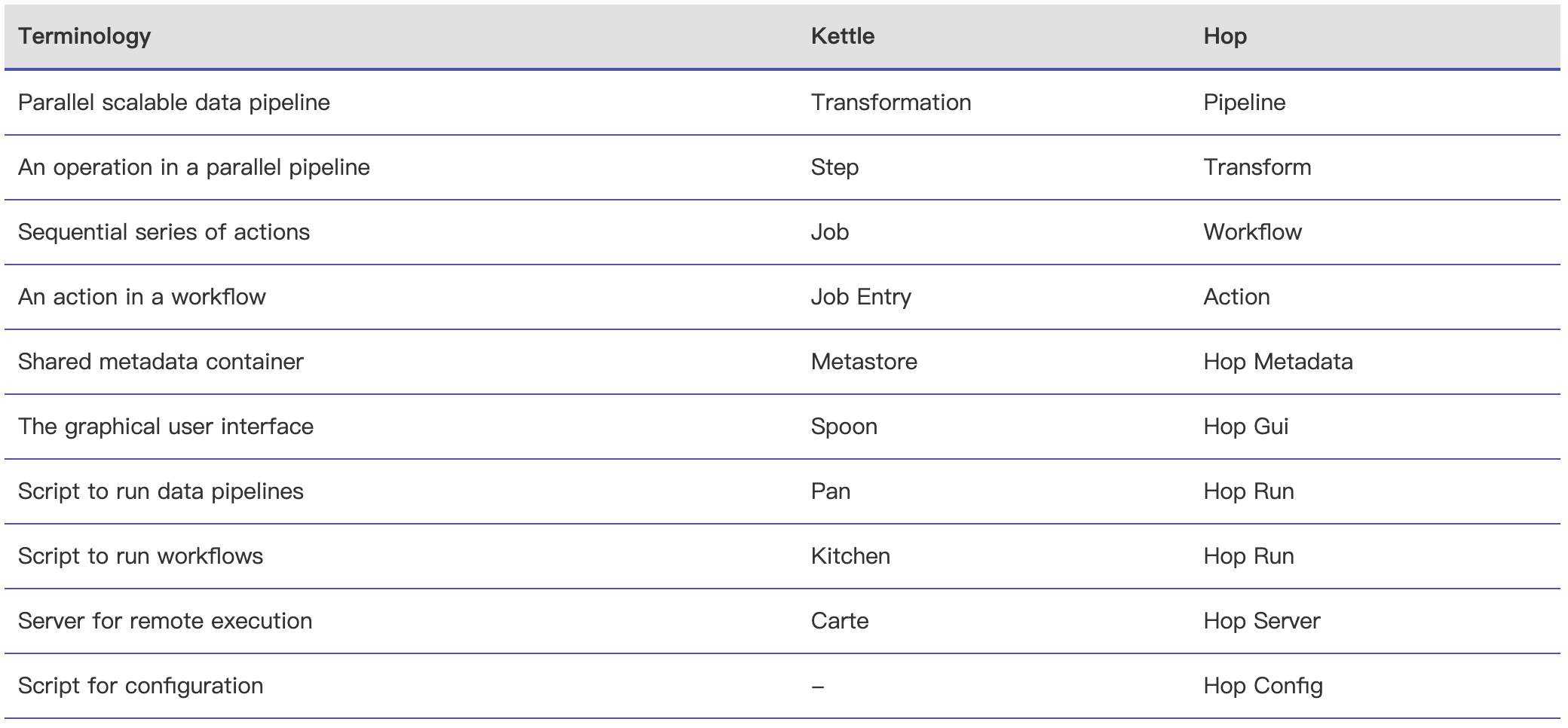
Apache Hop(Hop Orchestration Platform 的首字母缩写)是一种数据编排(data orchestration )和数据工程平台(data engineering platform),旨在促进数据和元数据编制。Hop 可以让我们专注于问题的解决,而不受技术的阻碍。该项目起源于 Kettle,经过数年的重构,并于2020年9月进入 Apache 孵化器;2022年1月18日正式成为 Apache 顶级项目。Hop 允许数据 2年前 (2022-01-22) 1475℃ 0评论2喜欢
2022年01月10日,来自 Cloudera 的工程师、Apache Ambari PMC 主席 Jayush Luniya 给 Ambari 社区发送了一封名为《[VOTE] Move Apache Ambari to Attic》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据邮件内容显示,在过去的两年里,Ambari 只发布了一个版本(2.7.6),大多数提交者(Committer)和 PMC 成员 2年前 (2022-01-16) 315℃ 0评论1喜欢
时间过得真快,2021年就过去了,又到了一年总结的时候了。本文将延续之前的惯例来总结一下过去一年大数据相关的项目顺利毕业成 Apache 顶级项目。在2021年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® DataSketches™、Apache® Gobblin™、Apache® DolphinScheduler™ 以及 Apache® Pinot™;同时有两个项目进入到 Apache 孵化器, 2年前 (2022-01-03) 1267℃ 0评论2喜欢
Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。如果想及时了解Spark、Hadoop或者HBase相关的文章, 2年前 (2022-01-01) 1064℃ 0评论3喜欢