

文章目录
为什么选择Spark
SequoiaDB是NoSQL数据库,它可以将数据复制到不同的物理节点上,而且用户可以在应用程序中指定使用哪个备份块。它能够在同一个集群中使用最少的I/O或者CPU来分析或者操作一些工作。
Apache Spark和SequoiaDB的整合允许用户创建单个平台来在同一个物理集群上同时运行多种不同的workloads 。
Spark-SequoiaDB Connector使得SequoiaDB能够和Spark整合
Spark-SequoiaDB Connector是Spark数据源,它运行用户使用Spark SQL对SequoiaDB collections中的数据集进行读写操作。它的用处就是使得SequoiaDB和Spark能够整合,充分利用带有动态索引的无模式存储模型和Spark集群的优势。

Spark和SequoiaDB可以安装在同一个物理节点或者不同集群上,Spark-SequoiaDB Connector可以将查询条件下传到SequoiaDB,并且仅仅遍历那些匹配到的数据。这种优化使得我们可以直接在源数据集上操作分析,而不需要在SequoiaDB和Spark之间进行一些ETL的操作。
下面是如何在SparkSQL中使用Spark-SequoiaDB Connector的例子:
/**
* User: 过往记忆
* Date: 2015-08-05
* Time: 上午01:26
* bolg:
* 本文地址:/archives/1418
* 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货
* 过往记忆博客微信公共帐号:iteblog_hadoop
*/
sqlContext.sql("CREATE temporary table org_department ( deptno string, deptname string,
mgrno string, admrdept string, location string ) using com.sequoiadb.spark
OPTIONS ( host 'host-60-0-16-2:50000', collectionspace 'org', collection 'department',
username 'sdbreader', password 'sdb_reader_pwd')")
res2: org.apache.spark.sql.DataFrame = []
sqlContext.sql("CREATE temporary table org_employee ( empno int, firstnme string,
midinit string, lastname string, workdept string, phoneno string, hiredate date,
job string, edlevel int, sex string, birthdate date, salary int, bonus int,
comm int ) using com.sequoiadb.spark
OPTIONS ( host 'host-60-0-16-2:50000', collectionspace 'org',
collection 'employee', username 'sdb_reader', password 'sdb_reader_pwd')")
res3: org.apache.spark.sql.DataFrame = []
sqlContext.sql("select * from org_department a, org_employee b where a.deptno='D11'")
.collect().take(3).foreach(println)
[D11,MANUFACTURING SYSTEMS,000060,D01,null,10,CHRISTINE,I,HAAS,A00,3978,null,PRES,18,F,null,152750,1000,4220]
[D11,MANUFACTURING SYSTEMS,000060,D01,null,20,MICHAEL,L,THOMPSON,B01,3476,null,MANAGER,18,M,null,94250,800,3300]
[D11,MANUFACTURING SYSTEMS,000060,D01,null,30,SALLY,A,KWAN,C01,4738,null,MANAGER,20,F,null,98250,800,3060]

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
金融服务行业使用案例:改进交易历史记录存档系统
Spark和SequoiaDB的联合解决方案可以帮助企业保留更多或者获得更多对他们有价值的数据。下面我们将展示一个金融服务行业使用案例,这家银行使用Spark和SequoiaDB来改进他们的交易记录存档系统。
在过去的几十年里,大多数银行在大型机器上运行他们的核心银行系统,而大型机器技术上的限制使得他们不得不把那些超过一年的交易历史数据从大型机上移到归档磁带上。
然而,现在的银行客户通过广泛的网上和移动银行的推动拥有比以往更高的要求。为了更有效地争夺客户,我们的一个客户(一个大银行)想通过客户能够搜索超过一年的交易的方式来提供他们产品的竞争力。

使用SequoiaDB,这家银行可以在50台机器上保存15年所有客户的交易信息,这些数据占用了1PB的磁盘空间。这个新系统使得客户能够轻松地通过移动端或者网站来访问他们所有的历史交易信息。

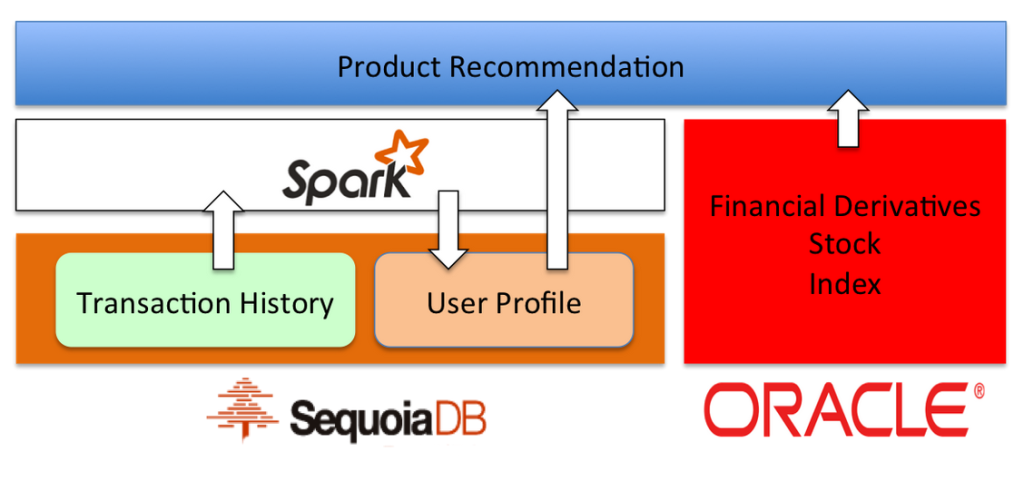
金融服务行业使用案例:使用Spark和SequoiaDB整合来进行产品推荐
有了上面的系统之后,该银行基于这个交易数据系统建立了客户分析系统,以便为每个客户找到合适的投资品种。
当客户分析系统利用所有的交易数据和日志进行产品推荐计算时,这些信息被写回到数据库中,并且为每个客户生成一个标记矩阵。
这些属性被前台工作人员和推荐引擎使用,以确认每个客户的潜在利益。部署该系统后,对金融衍生品的推荐成功率提高了十倍以上。
Spark和SequoiaDB整合的下一步计划
我们绝大多数的金融客户对流处理(反洗钱和高频交易用例)和交互式SQL处理(政府监管用例)有着极大的兴趣。我们将付出更多的努力来提高与Apache Spark整合特性和稳定性,比如使得SparkSQL支持标准的SQL2003。
转载请表明出处!
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【使用SequoiaDB Connector和Apache Spark整合】(https://www.iteblog.com/archives/1418.html)







