问题我们应该知道,Hive中存在两种类型的表:管理表(Managed table,又称Internal tables)和外部表(External tables),详情请参见《Hive表与外部表》。在公司内,特别是部门之间合作,很可能会通过 HDFS 共享一些 Hive 表数据,这时候我们一般都是参见外部表。比如我们有一个共享目录:/user/iteblog_hadoop/order_info,然后我们需要创建一个 w397090770 8年前 (2017-06-27) 5004℃ 1评论16喜欢
本书作者:Hanish Bansal、Saurabh Chauhan、Shrey Mehrotra,由Packt出版社于2016年4月出版,全书共486页。通过本书将学习到以下的知识:(1)、Learn different features and offering on the latest Hive(2)、Understand the working and structure of the Hive internals(3)、Get an insight on the latest development in Hive framework(4)、Grasp the concepts of Hive Data Model(5)、M zz~~ 8年前 (2017-05-26) 6481℃ 0评论22喜欢
我们在使用Hive的时候肯定遇到过建立了一张分区表,然后手动(比如使用 cp 或者 mv )将分区数据拷贝到刚刚新建的表作为数据初始化的手段;但是对于分区表我们需要在hive里面手动将刚刚初始化的数据分区加入到hive里面,这样才能供我们查询使用,我们一般会想到使用 alter table add partition 命令手动添加分区,但是如果初始化 w397090770 8年前 (2017-02-21) 16597℃ 0评论31喜欢
在大规模数据量的数据分析及建模任务中,往往针对全量数据进行挖掘分析时会十分耗时和占用集群资源,因此一般情况下只需要抽取一小部分数据进行分析及建模操作。本文就介绍 Hive 中三种数据抽样的方法块抽样(Block Sampling)Hive 本身提供了抽样函数,使用 TABLESAMPLE 抽取指定的 行数/比例/大小,举例:[code lang="sql"]CREA w397090770 9年前 (2017-02-10) 6359℃ 0评论7喜欢
我在《使用Hive读取ElasticSearch中的数据》文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到ElasticSearch中。在使用前同样需要加入 elasticsearch-hadoop-2.3.4.jar 依赖,具体请参见前文介绍。我们先在Hive里面建个名为iteblog的表,如下:[code lang="sql"]CREATE EXTERNAL TABLE iteblog ( id b w397090770 9年前 (2016-11-07) 20142℃ 1评论24喜欢
本文将介绍如何通过Hive来读取ElasticSearch中的数据,然后我们可以像操作其他正常Hive表一样,使用Hive来直接操作ElasticSearch中的数据,将极大的方便开发人员。本文使用的各组件版本分别为 Hive0.12、Hadoop-2.2.0、ElasticSearch 2.3.4。 我们先来看看ElasticSearch中相关表的mapping:[code lang="bash"]{ "user": { "propert w397090770 9年前 (2016-10-26) 17201℃ 0评论30喜欢
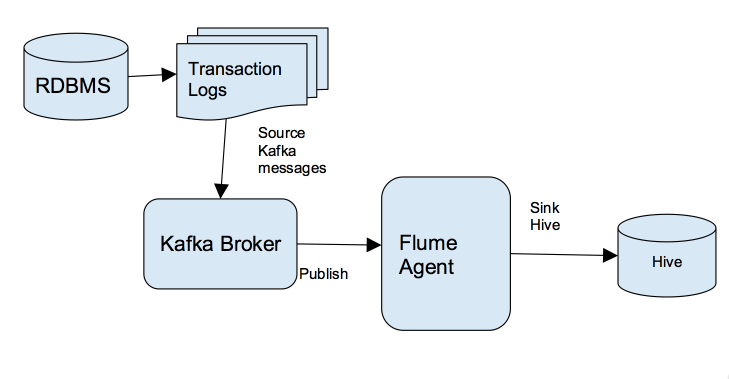
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 9年前 (2016-08-30) 11566℃ 6评论26喜欢
本文讲解的Hive和HBase整合意思是使用Hive读取Hbase中的数据。我们可以使用HQL语句在HBase表上进行查询、插入操作;甚至是进行Join和Union等复杂查询。此功能是从Hive 0.6.0开始引入的,详情可以参见HIVE-705。Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-1.2.0.jar工具里面的类实现 w397090770 9年前 (2016-07-31) 17569℃ 0评论42喜欢
我们在使用Hive查询数据的时候经常会看到如下的输出:[code lang="java"]Query ID = iteblog_20160704104520_988f81d4-0b82-4778-af98-43cc1950d357Total jobs = 1Launching Job 1 out of 1Number of reduce tasks determined at compile time: 1In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number>In order to limit the maximum number of reducers: w397090770 9年前 (2016-06-28) 15301℃ 1评论39喜欢
我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT '(7id', `name` string COMMENT '(7�')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTF w397090770 9年前 (2016-06-08) 11387℃ 0评论13喜欢

![[电子书]Apache Hive Cookbook PDF下载](https://www.iteblog.com/pic/Apache_Hive_Cookbook-iteblog.jpg)