今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 6年前 (2019-08-13) 5711℃ 2评论33喜欢
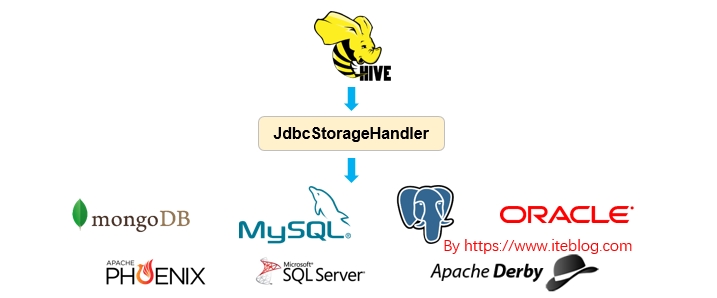
Apache Hive 从 HIVE-1555 开始引入了 JdbcStorageHandler ,这个使得 Hive 能够读取 JDBC 数据源,关于 Apache Hive 引入 JdbcStorageHandler 的背景可以参见 《Apache Hive 联邦查询(Query Federation)》。本文主要简单介绍 JdbcStorageHandler 的使用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop语法JdbcStorageHandler 使 w397090770 6年前 (2019-04-01) 3713℃ 0评论9喜欢
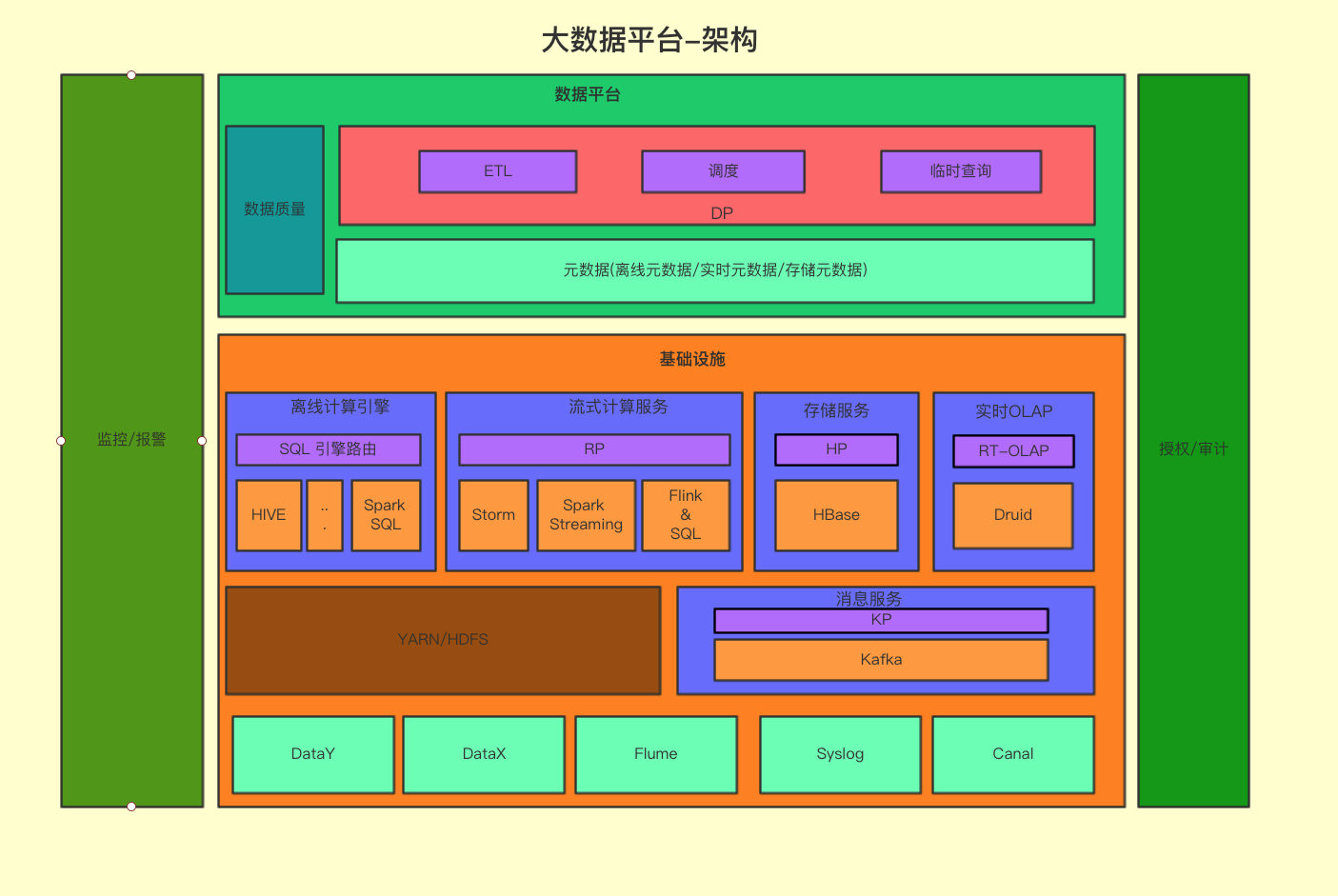
有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到的问题以及处理经验和优化建议,包括以下方面的内容:有赞数据平台的整体架构。SparkSQL 在有赞的技术演进 w397090770 6年前 (2019-03-20) 8347℃ 5评论29喜欢
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 6年前 (2019-03-16) 5302℃ 1评论8喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 7年前 (2018-07-22) 9828℃ 0评论10喜欢
问题我们都知道,Hive 内部提供了大量的内置函数用于处理各种类型的需求,参见官方文档:Hive Operators and User-Defined Functions (UDFs)。我们从这些内置的 UDF 可以看到两个用于解析 Json 的函数:get_json_object 和 json_tuple。用过这两个函数的同学肯定知道,其职能解析最普通的 Json 字符串,如下:[code lang="sql"]hive (default)> SELECT get_js w397090770 7年前 (2018-07-04) 20295℃ 0评论34喜欢
在 《使用Python编写Hive UDF》 文章中,我简单的谈到了如何使用 Python 编写 Hive UDF 解决实际的问题。我们那个例子里面仅仅是一个很简单的示例,里面仅仅引入了 Python 的 sys 包,而这个包是 Python 内置的,所有我们不需要担心 Hadoop 集群中的 Python 没有这个包;但是问题来了,如果我们现在需要使用到 numpy 中的一些函数呢?假设我们 w397090770 8年前 (2018-01-25) 6622℃ 3评论23喜欢
Hive 内置为我们提供了大量的常用函数用于日常的分析,但是总有些情况这些函数还是无法满足我们的需求;值得高兴的是,Hive 允许用户自定义一些函数,用于扩展 HiveQL 的功能,这类函数叫做 UDF(用户自定义函数)。使用 Java 编写 UDF 是最常见的方法,但是本文介绍的是如何使用 Python 来编写 Hive 的 UDF 函数。如果想及时了解S w397090770 8年前 (2018-01-24) 14579℃ 0评论27喜欢
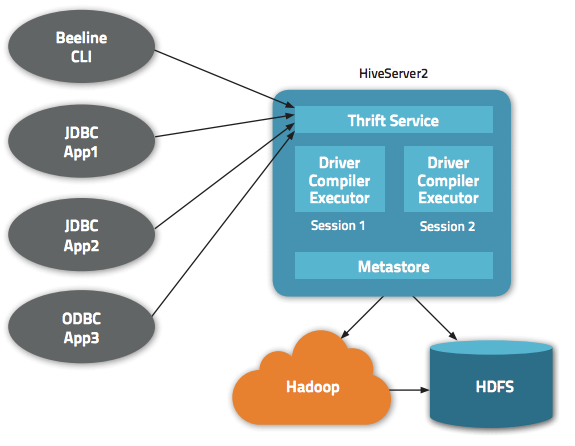
Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可 w397090770 8年前 (2018-01-11) 13637℃ 5评论18喜欢
关系运算1、等值比较: =语法:A=B操作类型:所有基本类型描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE[code lang="sql"]hive> select 1 from iteblog where 1=1;1[/code]2、不等值比较: 语法: A B操作类型: 所有基本类型描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A与表达式B不相等,则为TRUE;否则为 zz~~ 8年前 (2017-09-14) 94490℃ 3评论185喜欢