背景在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 w397090770 6年前 (2018-05-28) 26590℃ 409评论62喜欢
杭州第六次 Spark & Flink Meetup 于2018年05月12日在华为杭研所1号楼1楼报告厅进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop议题本次会议的议题如下:冯叶磊 - 华为云 《Time GeoSpatial on Flink SQL》范文臣 - Spark PMC 《deep dive into structural streaming》梁永峰 - 阿里《基于Flink的流计算平台 w397090770 6年前 (2018-05-13) 3885℃ 1评论8喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 6年前 (2018-04-01) 19580℃ 4评论92喜欢
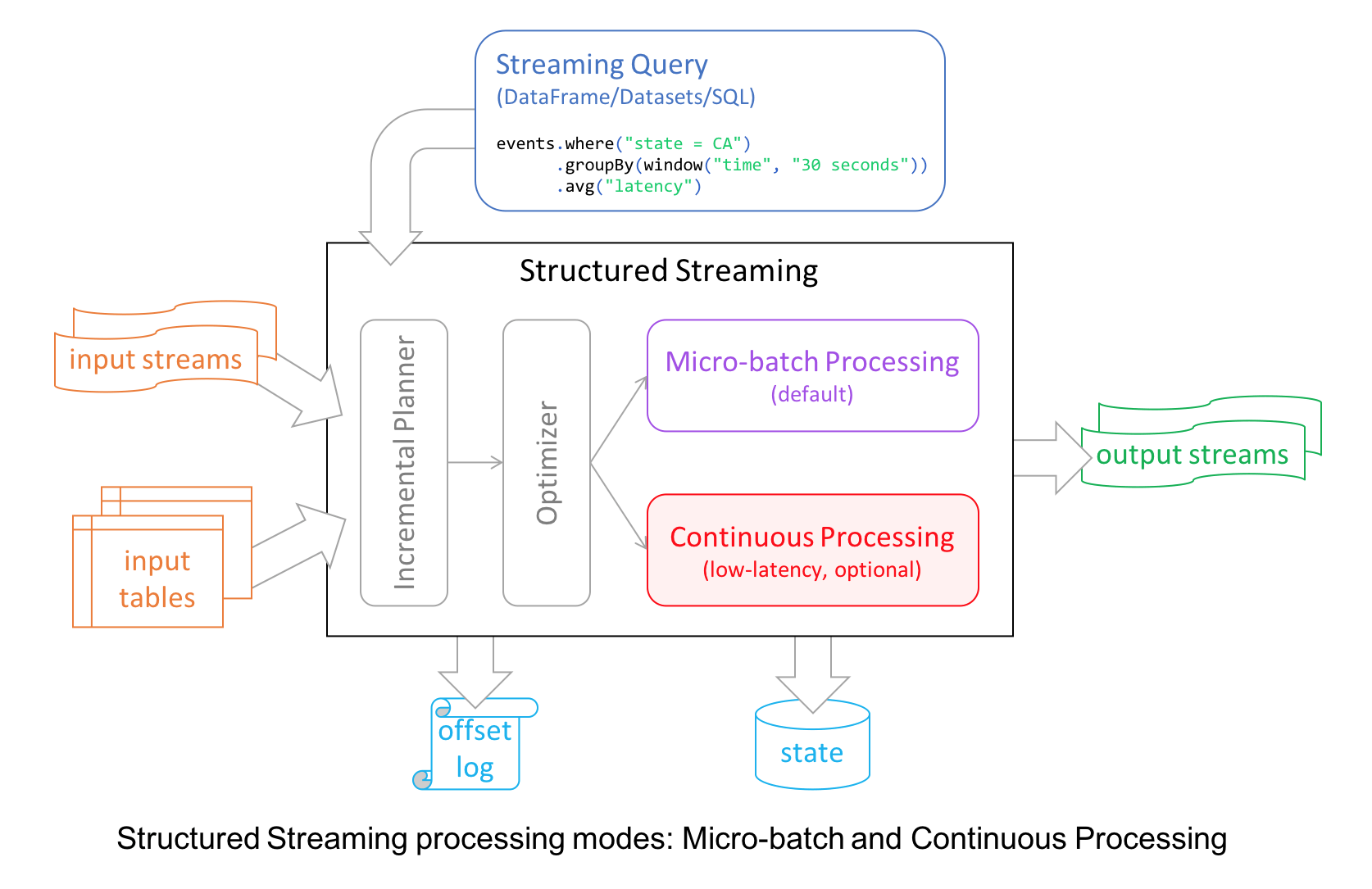
本文翻译自:Introducing Apache Spark 2.3为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.3 在许多模块都做了重要的更新,比如 Structured Streaming 引入了低延迟的连续处理(continuous processing);支持 stream-to-stream joins;通过改善 pandas UDFs 的性能来提升 PySpark;支持第四种调度引擎 Kubernetes clusters(其他三种分别是自带的独立模式St w397090770 6年前 (2018-03-01) 7184℃ 3评论32喜欢
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,我们在此与大家分享一下我们在简化Spark使用和编程以及加快Spark在生产环境落地上做的一些努力。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop一个Spark Streaming读取Kafka w397090770 6年前 (2018-02-28) 6579℃ 0评论13喜欢
用户定义函数(User-defined functions, UDFs)是大多数 SQL 环境的关键特性,用于扩展系统的内置功能。 UDF允许开发人员通过抽象其低级语言实现来在更高级语言(如SQL)中启用新功能。 Apache Spark 也不例外,并且提供了用于将 UDF 与 Spark SQL工作流集成的各种选项。在这篇博文中,我们将回顾 Python,Java和 Scala 中的 Apache Spark UDF和UDAF(u w397090770 6年前 (2018-02-14) 14826℃ 0评论21喜欢
本文作者:汪愈舟 俞育才 郭晨钊 程浩(英特尔),李元健(百度)Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇到不少易用性和可扩展性的挑战。为了应对这些挑战,英特尔大数据技术团 w397090770 6年前 (2018-01-11) 90823℃ 0评论75喜欢
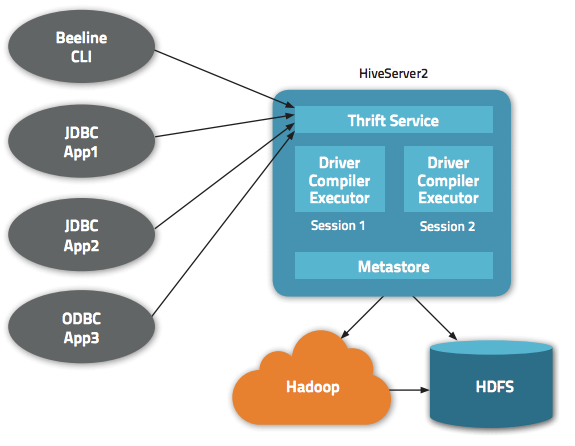
Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可 w397090770 6年前 (2018-01-11) 13076℃ 5评论18喜欢
Apache Spark 2.2.0 于今年7月份正式发布,这个版本是 Structured Streaming 的一个重要里程碑,因为其可以正式在生产环境中使用,实验标签(experimental tag)已经被移除; CBO (Cost-Based Optimizer)有了进一步的优化;SQL完全支持 SQL-2003 标准;R 中引入了新的分布式机器学习算法;MLlib 和 GraphX 中添加了新的算法更多详情请参见:Apa w397090770 6年前 (2017-12-13) 2641℃ 0评论19喜欢
第十四次Shanghai Apache Spark Meetup聚会,由中国平安银行大力支持。活动将于2017年12月23日12:30~17:00在上海浦东新区上海海神诺富特酒店三楼麦哲伦厅举行。举办地点交通方便,靠近地铁4号线浦东大道站。座位有限,先到先得。大会主题《Spark在金融领域的算法实践》(13:20 – 14:05)演讲嘉宾:潘鹏举,平安银行大数据平台架构师 zz~~ 6年前 (2017-12-06) 1949℃ 0评论11喜欢