Spark 的 shell 作为一个强大的交互式数据分析工具,提供了一个简单的方式来学习 API。它可以使用 Scala(在 Java 虚拟机上运行现有的 Java 库的一个很好方式) 或 Python。我们很可能会在Spark Shell模式下运行下面的测试代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="scala"]scala> imp w397090770 7年前 (2017-04-26) 2870℃ 0评论9喜欢
本书由Andrew Morgan所著,全书共560页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Learn the design patterns that integrate Spark into industrialized data science pipelines 2、See how commercial data scientists design scalable code and reusable code for data science services 3、Explore cutting edge data science methods so that you can study tre zz~~ 7年前 (2017-04-17) 3436℃ 2评论8喜欢
最近几年关于Apache Spark框架的声音是越来越多,而且慢慢地成为大数据领域的主流系统。最近几年Apache Spark和Apache Hadoop的Google趋势可以证明这一点:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop上图已经明显展示出最近五年,Apache Spark越来越受开发者们的欢迎,大家通过Google搜索更多关 w397090770 7年前 (2017-04-12) 6537℃ 0评论46喜欢
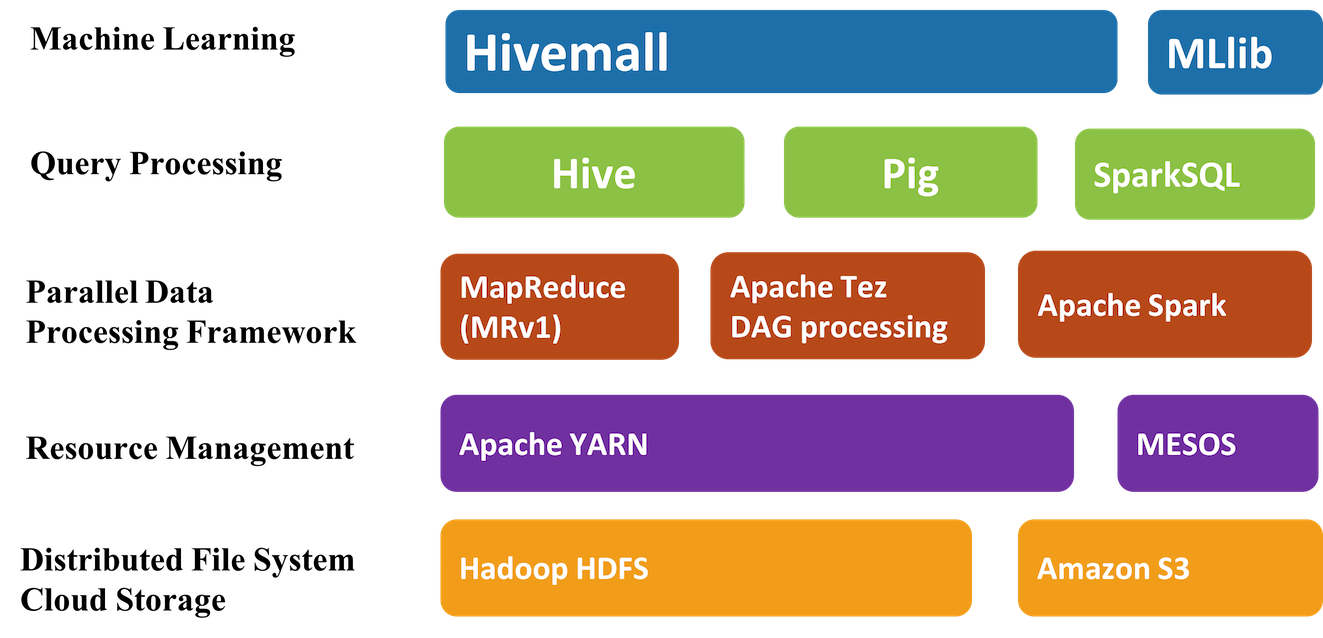
Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。 Apache Hivemall提供了各种功能包括:回归( w397090770 7年前 (2017-03-29) 3324℃ 1评论10喜欢
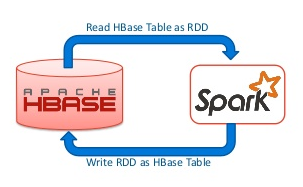
在使用Spark操作Hbase的时候,其返回的数据类型是RDD[ImmutableBytesWritable,Result],我们可能会对这个结果进行其他的操作,比如join等,但是因为org.apache.hadoop.hbase.io.ImmutableBytesWritable 和 org.apache.hadoop.hbase.client.Result 并没有实现 java.io.Serializable 接口,程序在运行的过程中可能发生以下的异常:[code lang="bash"]Serialization stack: - object not ser w397090770 7年前 (2017-03-23) 5331℃ 1评论13喜欢
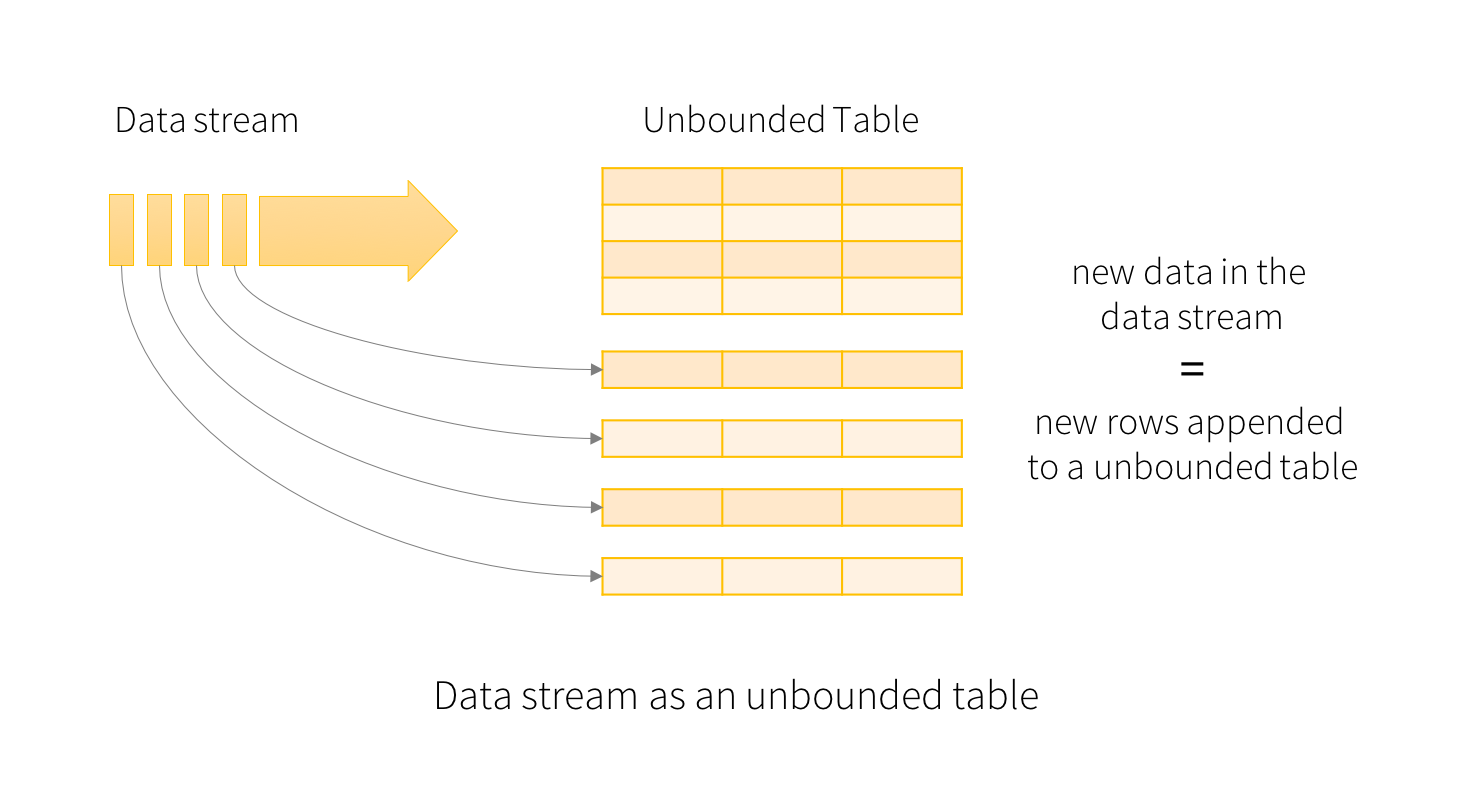
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming zz~~ 7年前 (2017-03-22) 10721℃ 2评论11喜欢
本文作者:李寅威,从事大数据、机器学习方面的工作,目前就职于CVTE联系方式:微信(coridc),邮箱(251469031@qq.com)原文链接: Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入门1 引言 Apache CarbonData是一个面向大数据平台的基于索引的列式数据格式,由华为大数据团队贡献给Apache社区,目前最新版本是1.0.0版。介于 zz~~ 7年前 (2017-03-13) 3412℃ 0评论11喜欢
本书将向您展示如何利用Python的强大功能并将其用于Spark生态系统中。您将首先了解Spark 2.0的架构以及如何为Spark设置Python环境。通过本书,你将会使用Python操作RDD、DataFrames、MLlib以及GraphFrames等;在本书结束时,您将对Spark Python API有了全局的了解,并且学习到如何使用它来构建数据密集型应用程序。通过本书你将学习到以下的知识 zz~~ 7年前 (2017-03-09) 10734℃ 0评论12喜欢
第十二次Shanghai Apache Spark Meetup聚会,由Splunk中国大力支持。活动将于2017年03月18日12:30~16:45在上海淞沪路303号901 (大学路智星路路口汇丰银行楼9楼)Splunk 中国进行。 举办地点交通方便,靠近地铁10号线江湾体育场站,座位有限(大约120),先到先得,速速行动啊。大会主题《利用Spark开发高并发,高可靠的分布式大数据采集调 w397090770 7年前 (2017-03-09) 1423℃ 0评论2喜欢
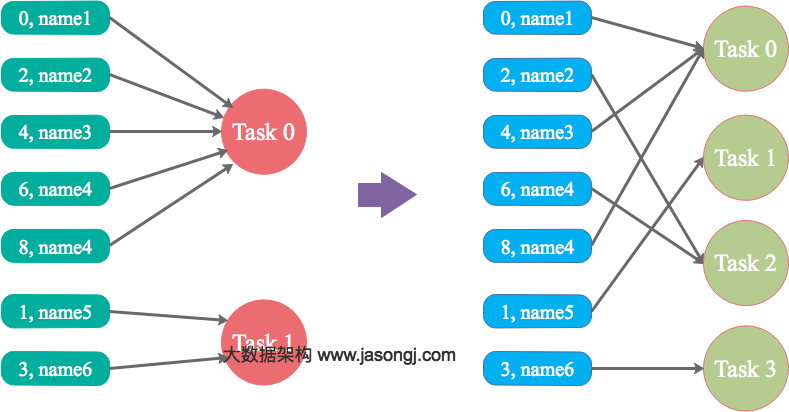
本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。为何要处理数据倾斜(Data Skew)什么是数据倾斜对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。何谓数据倾 w397090770 7年前 (2017-03-07) 13237℃ 2评论27喜欢

![[电子书]Mastering Spark for Data Science PDF下载](https://www.iteblog.com/pic/books/mastering-spark-data-science_iteblog.jpg)


![[电子书]Learning PySpark PDF下载](https://www.iteblog.com/pic/books/Learning_PySpark_iteblog.jpg)