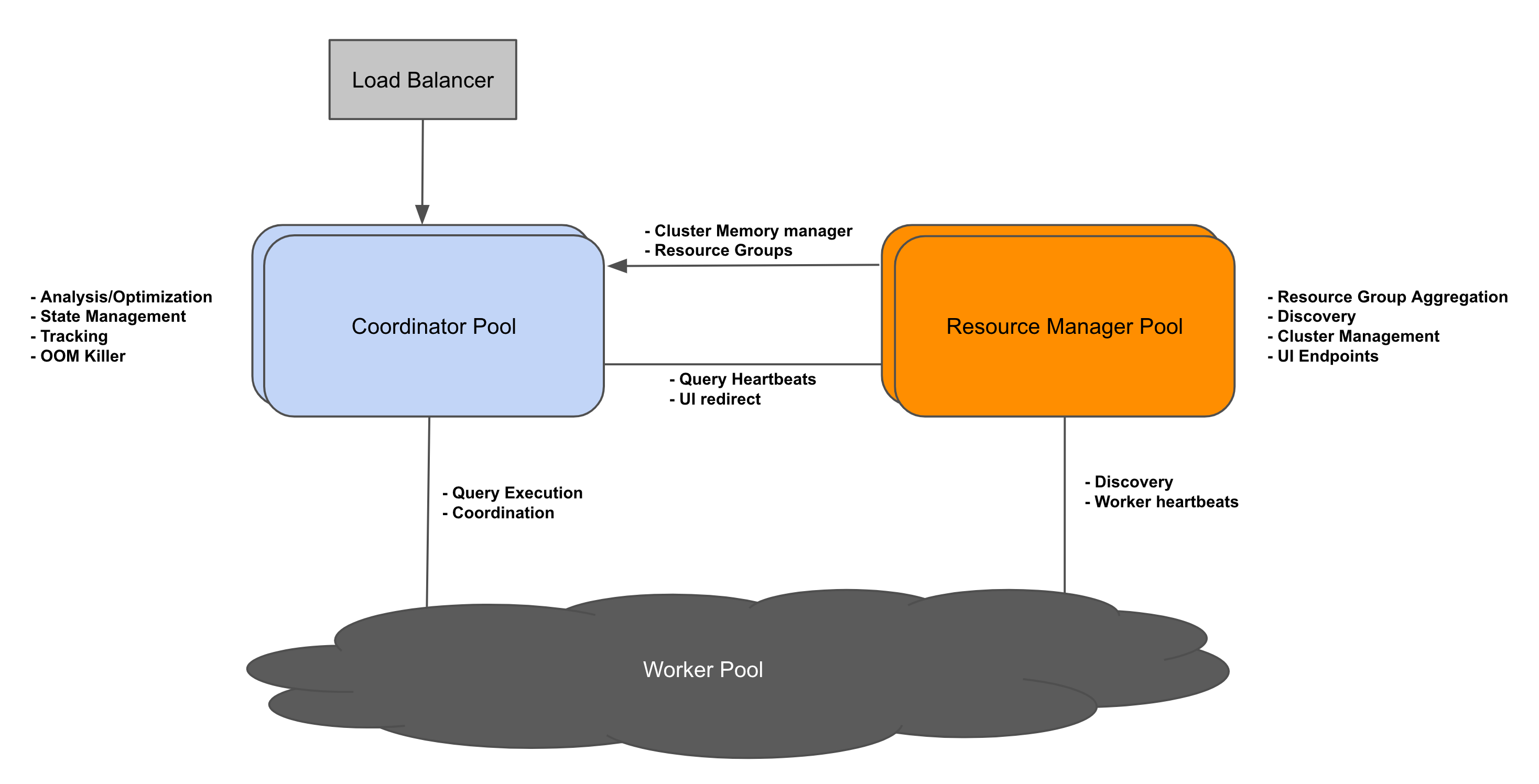
背景Presto 的架构最初只支持一个 coordinator 和多个 workers。多年来,这种方法一直很有效,但也带来了一些新挑战。使用单个 coordinator,集群可以可靠地扩展到一定数量的 worker。但是运行复杂、多阶段查询的大集群可能会使供应不足的 coordinator 不堪重负,因此需要升级硬件来支持工作负载的增加。单个 coordinator 存在单点故障 zz~~ 3年前 (2022-04-22) 1023℃ 0评论1喜欢
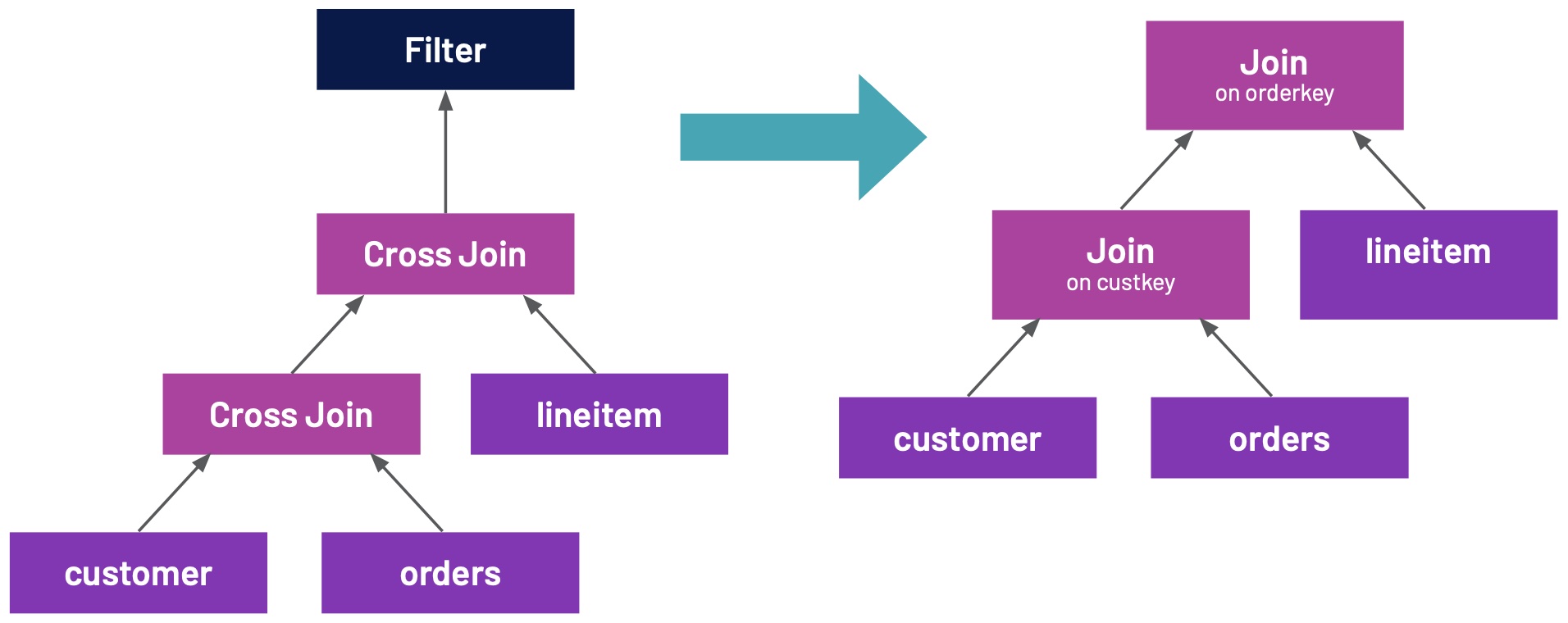
Depending on the complexity of your SQL query there are many, often exponential, query plans that return the same result. However, the performance of each plan can vary drastically; taking only seconds to finish or days given the chosen plan.That places a significant burden on analysts who will then have to know how to write performant SQL. This problem gets worse as the complexity of questions and SQL queries increases. In the abse w397090770 3年前 (2022-04-20) 714℃ 0评论1喜欢
Starburst provides connectors to the most popular data sources included in many of these connectors are a number of exclusive enhancements. Many of Starburst’s connectors when compared with open source Trino have enhanced extensions such as parallelism, pushdown and table statistics, that drastically improve the overall performance. Parallelism distributes query processing across workers, and uses many connections to the data source a w397090770 3年前 (2022-04-15) 681℃ 0评论0喜欢
Dynamic filtering optimizations significantly improve the performance of queries with selective joins by avoiding reading of data that would be filtered by join condition. In this respect, dynamic filtering is similar to join pushdown discussed above, however it is the equivalent of inner join pushdown across data sources. As a consequence we derive the performance benefits associated with selective joins when performing federated queri w397090770 3年前 (2022-04-15) 476℃ 0评论1喜欢
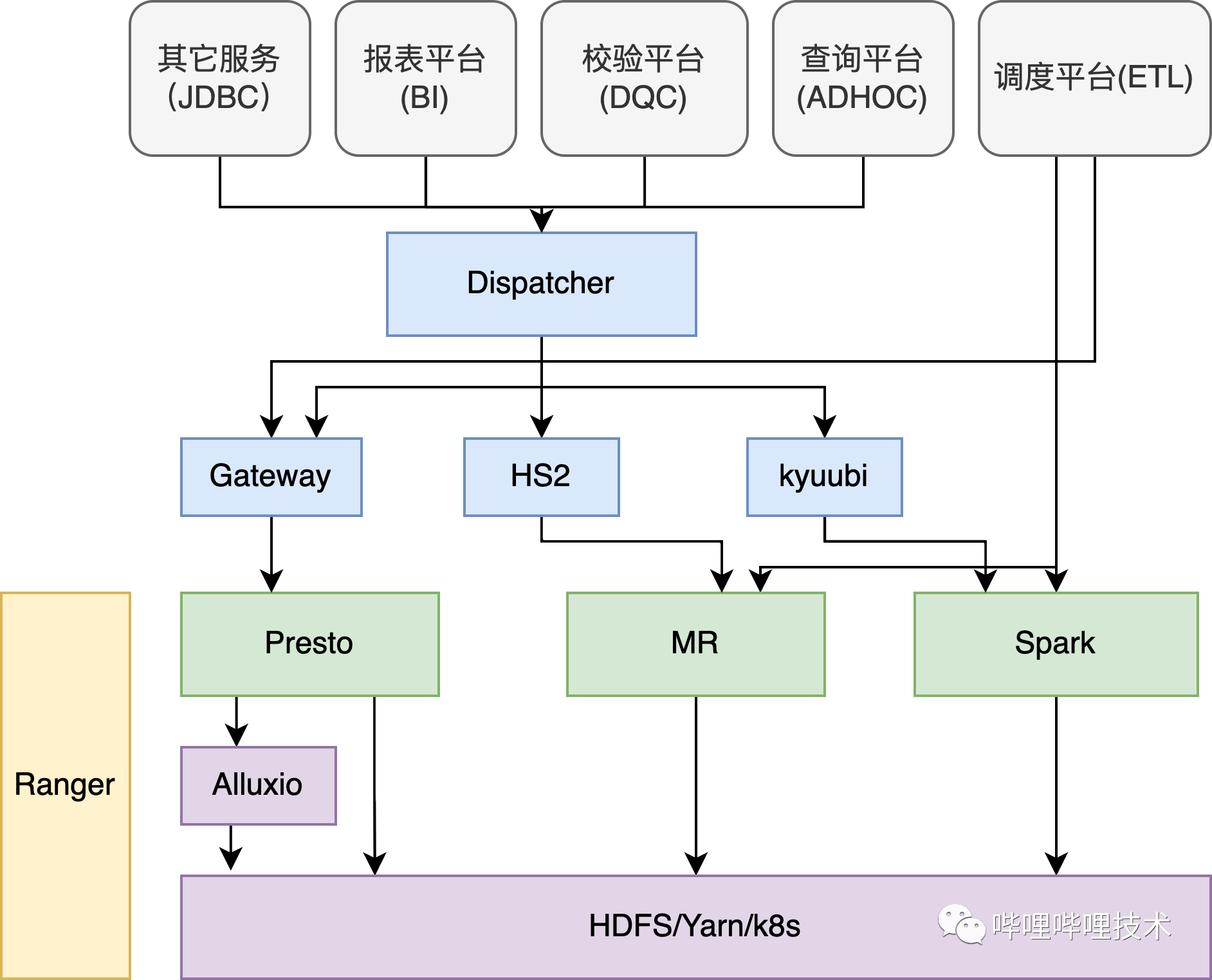
架构B站SQL On Hadoop 整体架构在介绍Presto在B站的实践之前,先从整体来看看SQL在B站的使用情况,在B站的离线平台,核心由三大计算引擎Presto、Spark、Hive以及分布式存储系统HDFS和调度系统Yarn组成。如下架构图所示,我们的ADHOC、BI、DQC以及数据探查等服务都是通过自研的Dispatcher路由服务来进行统一SQL调度,Dispatcher会结合查询 w397090770 3年前 (2022-04-14) 1997℃ 0评论4喜欢
Trino Summit 2021 由 Starburst 于 2021年10月21日-22日通过线上的方式进行。主要分享嘉宾有 Trino 的几个创始人、Apache Iceberg 的创建者 Ryan Blue 以及来自 DoorDash 的 Akshat Nair 和 Satya Boora 等。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop主要分享议题State of TrinoFast results using Iceberg and TrinoThe Future of w397090770 3年前 (2022-04-12) 732℃ 0评论5喜欢
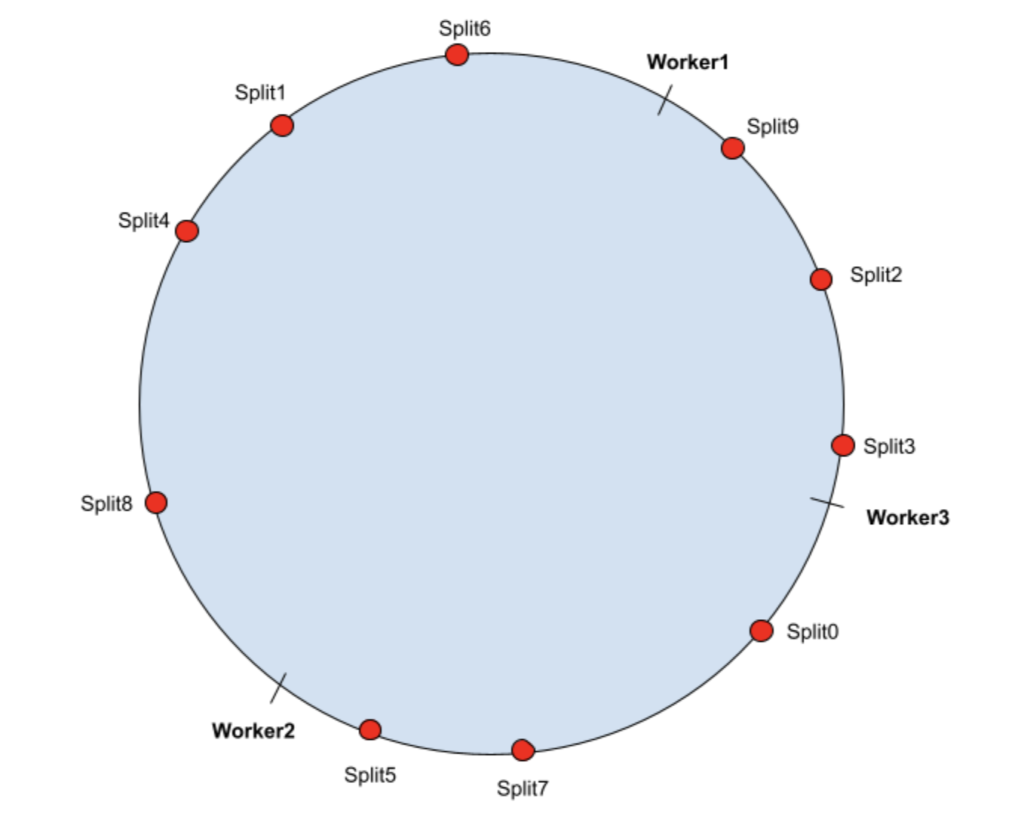
R目前,越来越多的用户开始在 Presto 里面使用 Alluxio,它通过利用 SSD 或内存在 Presto workers 上缓存热数据集,避免从远程存储读取数据。 Presto 支持基于哈希的软亲和调度(hash-based soft affinity scheduling),强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的哈希算法在集 w397090770 3年前 (2022-04-01) 518℃ 0评论1喜欢
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。测试目的验证影响Alluxio加速收益的各种因素记录Alluxio w397090770 3年前 (2022-03-29) 873℃ 0评论2喜欢
什么是 Alluxio Local Cache随着云计算在基础设施领域的市场份额持续上升,主流数据分析引擎纷纷选择独立扩展存储、计算来适配云基础设施,并以此为云提供商降低成本。但是,存储计算分离也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。此外,元数据也面临远程网络来检索的性能问题。 w397090770 3年前 (2022-03-21) 806℃ 0评论3喜欢
2017 年初,我们开始探索 Presto 来解决 OLAP 用例,我们意识到了这个惊人的查询引擎的潜力。与 Apache Hive 相比,它最初是一种临时查询工具,供数据工程师和分析师以更快的方式运行 SQL 来构建查询原型。 当时很多内部仪表板都由 AWS-Redshift 提供支持,并将数据存储和计算耦合在一起。我们的数据呈指数级增长(每隔几天翻一番), w397090770 3年前 (2022-03-18) 422℃ 0评论1喜欢