本文是 2021-10-13 日周三下午13:30 举办的议题为《Enabling Presto Caching at Uber with Alluxio》的分享,作者来自 Uber 的 Zhongting Hu 和 Alluxio 发 Dr. Beinan Wang。Zhongting Hu is Tech Lead Manager of the Interactive Analytics Team at Uber. He is leading and managing Presto ecosystems inside Uber.Dr. Beinan Wang is a software engineer from Alluxio and is the committer of PrestoDB. Prior to Alluxio, he w397090770 4年前 (2021-10-27) 290℃ 0评论0喜欢
在《ASM 与 Presto 动态代码生成简介》这篇文章中,我们简单介绍了 Presto 动态代码生成的原理以及 Presto 在计算表达式的地方会使用到动态代码生成技术。为了加深理解,本文将以两个例子介绍 Presto 里面动态代码生成的使用。EmbedVersion我们往 Presto 提交 SQL 查询以及 TaskExecutor 启动 TaskRunner 执行 Task 的时候都会使用到 EmbedVersion 类 w397090770 4年前 (2021-10-12) 776℃ 0评论1喜欢
Presto 是由 Facebook 开发并开源的分布式 SQL 交互式查询引擎,很多公司都是用它实现 OLAP 业务分析。本文列出了 Presto 常用的函数列表。数学函数数学函数作用于数学公式。下表给出了详细的数学函数列表。abs(x)返回 x 的绝对值。使用如下:[code lang="bash"]presto:default> select abs(1.23) as absolute; absolute ---------- 1.23[/code] w397090770 4年前 (2021-10-07) 6026℃ 0评论1喜欢
代码生成是很多计算引擎中常用的执行优化技术,比如我们熟悉的 Apache Spark 和 Presto 在表达式等地方就使用到代码生成技术。这两个计算引擎虽然都用到了代码生成技术,但是实现方式完全不一样。在 Spark 中,代码生成其实就是在 SQL 运行的时候根据相关算子动态拼接 Java 代码,然后使用 Janino 来动态编译生成相关的 Java 字节码并 w397090770 4年前 (2021-09-28) 739℃ 0评论3喜欢
文章来源团队:腾讯医疗资讯与服务部-技术研发中心 前言:随着产品矩阵和团队规模的扩张,跨业务、APP的数据处理、分析总是不可避免。一个显而易见的问题就是异构数据源的连通。我们基于PrestoDB构建了业务线内适应腾讯生态的联邦查询引擎,连通了部门内部20+数据源实例,涵盖了90%的查询场景。同时,我们参与公司级的Pre w397090770 4年前 (2021-09-08) 604℃ 0评论1喜欢
导读:本文的主题是Presto高性能引擎在美图的实践,首先将介绍美图在处理ad-hoc场景下为何选择Presto,其次我们如何通过外部组件对Presto高可用与稳定性的增强。然后介绍在美图业务中如何做到合理与高效的利用集群资源,最后如何利用Presto应用于部分离线计算场景中。使大家了解Presto引擎的优缺点,适合的使用场景,以及在美图 w397090770 4年前 (2021-09-01) 877℃ 0评论1喜欢
随着越来越多的公司广泛部署 Presto,Presto 不仅用于查询,还用于数据摄取和 ETL 作业。所有很有必要提高 Presto 文件写入的性能,尤其是流行的列文件格式,如 Parquet 和 ORC。本文我们将介绍 Presto 的全新原生的 Parquet writer ,它可以直接将 Presto 的列式数据结构写到 Parquet 的列式格式,最高可提高6倍的吞吐量,并减少 CPU 和内存开销 w397090770 4年前 (2021-08-14) 629℃ 0评论2喜欢
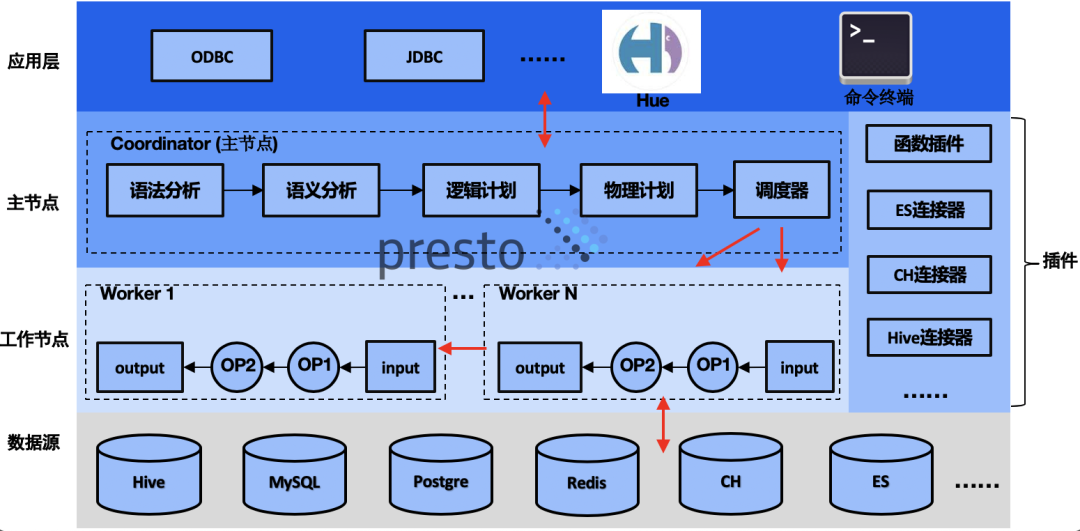
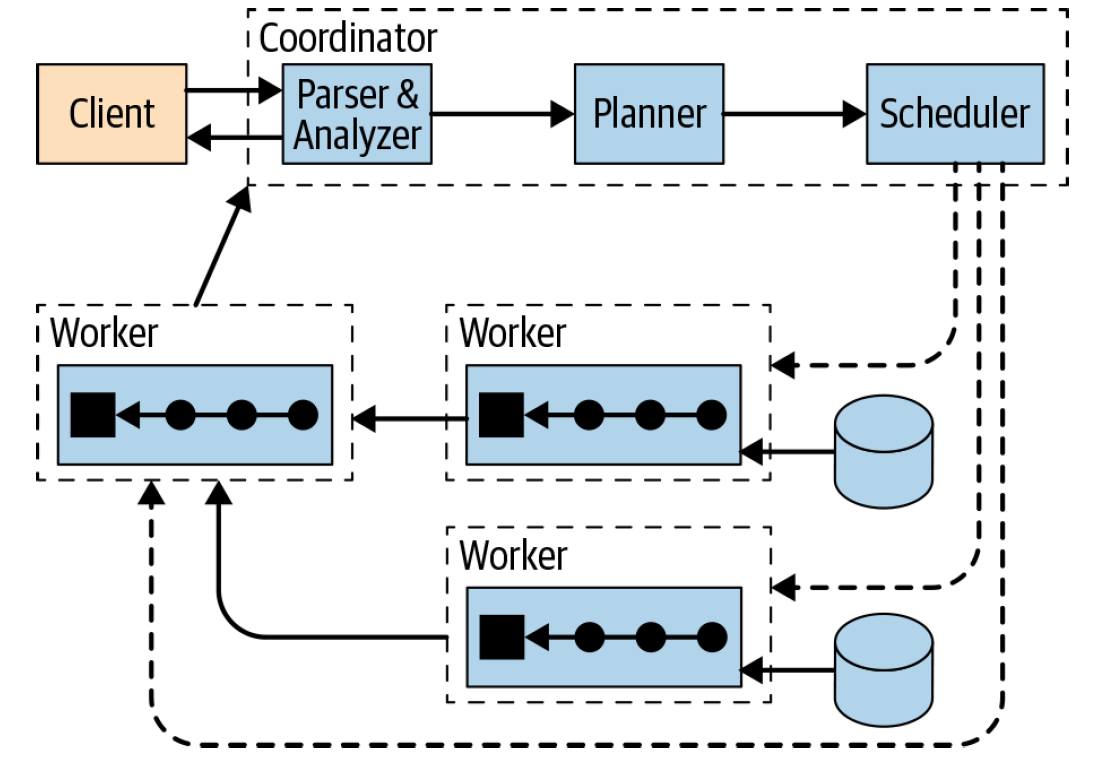
背景在介绍 Presto 计算下推之前,我们先来回顾一下 Presto 从对应的 Connector 上读取数据的流程,过程如下:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从上图可以看出,client 提交 SQL 到 Coordinator 上,Coordinator 接收到 SQL 之后,会进行 SQL 语法语义解析,生成逻辑计划树,然后经过 pla w397090770 4年前 (2021-08-12) 1761℃ 0评论4喜欢
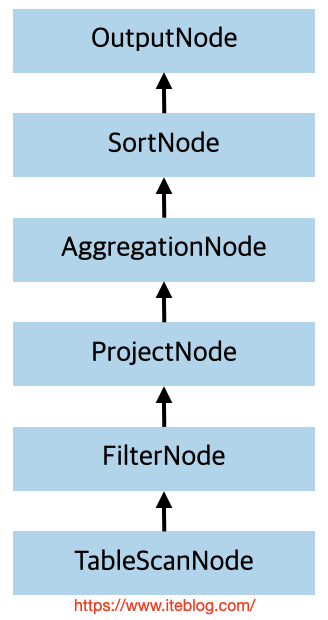
和其他计算引擎一样,一条 SQL 从客户的提交到 Coordinator 端经过 SqlParser 进行词法和语法解析形成 AST 树,然后经过 Analyzer 进行语义分析,生成了逻辑计划(LogicalPlan);接着经过优化器处理(优化规则都是在 PlanOptimizers 里面定义好的,然后在 LogicalPlanner 里面循环遍历每个规则)生成物理计划(PhysicalPlan);最后使用 PlanFragmenter 并 w397090770 4年前 (2021-08-08) 1340℃ 0评论3喜欢
PrestoCon Day 2021 在3月24日于在线的形式举办,会议的议程可以参见这里。这里主要是收集了本次会议的 PPT 和视频等资料供大家学习交流使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据下载途径关注微信公众号 过往记忆大数据 或者 Java与大数据架构 并回复 10011 获取。可下载 w397090770 4年前 (2021-07-31) 621℃ 0评论4喜欢