本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 5年前 (2020-11-24) 1242℃ 0评论4喜欢
本文来自车好多大数据离线存储团队相关同事的投稿,本文作者: 车好多大数据离线存储团队:冯武、王安迪。升级的背景HDFS 集群作为大数据最核心的组件,在公司承载了DW、AI、Growth 等重要业务数据的存储重任。随着业务的高速发展,数据的成倍增加,HDFS 集群出现了爆炸式的增长,使用率一直处于很高的水位。同时 HDFS文件 5年前 (2020-11-24) 1521℃ 0评论2喜欢
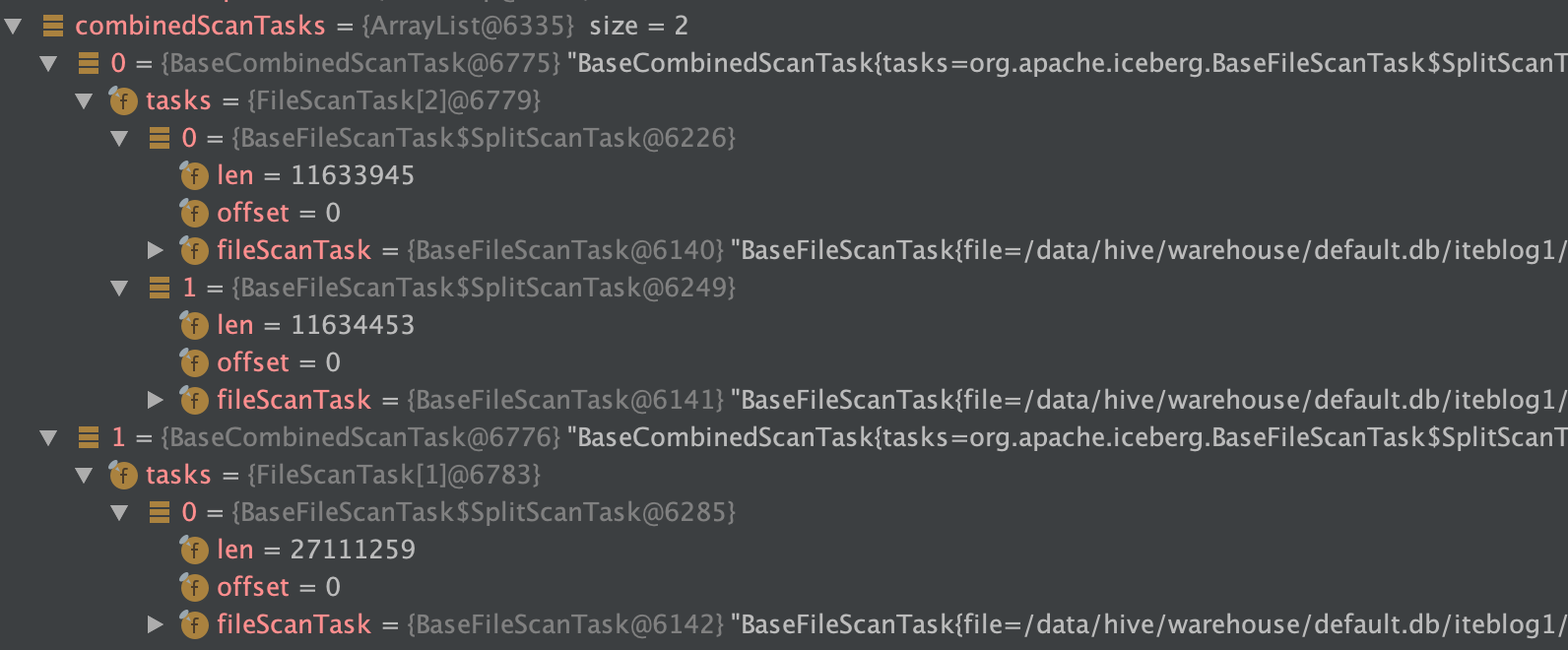
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):[code lang="bash"]/data/hive/warehouse/default.db/iteblog├── data│ └── ts_year=2020│ ├── id_bucket=0│ │ ├── 00000-0-19603f5a-d38a 5年前 (2020-11-20) 7284℃ 6评论8喜欢
本文基于 Apache Iceberg 0.9.0 最新分支,主要分析 Apache Iceberg 中使用 Spark 2.4.6 来写数据到 Iceberg 表中,也就是对应 iceberg-spark2 模块。当然,Apache Iceberg 也支持 Flink 来读写 Iceberg 表,其底层逻辑也 Spark 类似,感兴趣的同学可以去看看。使用 Spark2 将数据写到 Apache Iceberg在介绍下面文章之前,我们先来看下在 Apache Spark 2.4.6 中写数 5年前 (2020-11-12) 6385℃ 0评论9喜欢
HDFS集群随着使用时间的增长,难免会出现一些“性能退化”的节点,主要表现为磁盘读写变慢、网络传输变慢,我们统称这些节点为慢节点。当集群扩大到一定规模,比如上千个节点的集群,慢节点通常是不容易被发现的。大多数时候,慢节点都藏匿于众多健康节点中,只有在客户端频繁访问这些有问题的节点,发现读写变慢了, 5年前 (2020-11-12) 1819℃ 0评论7喜欢
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop使用 Hive catalog从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它 5年前 (2020-11-08) 2614℃ 0评论5喜欢
在 Zookeeper 中限制 transaction log 总大小主要有两种方法。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop限制 Zookeeper Transaction Log 里面的事务条数默认情况下,在写入 snapCount(100000) 事务后,Zookeeper 事务日志将会切换。如果 Zookeeper 的数据目录的空间不足与存储三个版本的 Zookeeper Transaction Lo 5年前 (2020-10-28) 950℃ 0评论1喜欢
问题的定义装箱问题(Bin packing problem),又称集装优化,是一个利用运筹学去解决实际生活的的经典问题。在维基百科的定义如下:In the bin packing problem, items of different volumes must be packed into a finite number of bins or containers each of a fixed given volume in a way that minimizes the number of bins used. In computational complexity theory, it is a combinatorial NP-hard 5年前 (2020-10-27) 7322℃ 0评论2喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在 这篇 文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:INNER JOINCROSS JOINLEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOINLEFT SEMI JOINLEFT ANTI JOIN在实现上 5年前 (2020-10-25) 1887℃ 0评论6喜欢
本文资料来自2020年9月23日举办的 Apache Spark Bogotá 题为《Apache Spark 3.0: Overview of What’s New and Why Care》 的分享。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Spark 3.0 继续坚持更快、更简单、更智能的目标,这个版本解决了3000多个 JIRAs。在这次演讲中,主要和 Bogota Spark 社区分享 Spark 3.0 的 5年前 (2020-10-24) 965℃ 0评论3喜欢