2021年2月15日,Apache Flink 创建者、Ververica 公司(前身 DataArtisans)的联合创始人 Fabian Hueske 在 Twitter 宣布其已经从 Ververica 离职, 不过离职原因不得而知。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop另外,Ververica 公司原 COO Holger Temme 将接替 Kostas Tzoumas 成为新的 CEO。Kostas Tzoumas (原 CEO) 4年前 (2021-02-18) 1157℃ 0评论5喜欢
2021年2月4日,负责维护 Docker 引擎的 Justin Cormack 在 Docker 官方博客宣布把 Docker 发行版(Docker Distribution)捐献给了 CNCF,全文如下:我们很高兴地宣布,Docker 已经把 Docker 发行版(Docker Distribution)捐献给了 CNCF。Docker 致力于开源社区和我们许多项目的开放标准,这一举动将确保 Docker 发行版有一个广泛的团队来维护许多注册中心 4年前 (2021-02-06) 338℃ 0评论2喜欢
2021年2月1日, Databricks 在其博客宣布将投资10亿美元,以应对其统一数据平台(unified data platform)在全球的快速普及。 本次融资由富兰克林·邓普顿(Franklin Templeton)领投,加拿大养老金计划投资委员会(Canada Pension Plan Investment Board)、富达管理与研究有限责任公司(Fidelity Management & Research LLC)和 Whale Rock(美国的媒体和技术公 5年前 (2021-02-02) 680℃ 0评论3喜欢
本版本迁移指南 If migrating from release older than 0.5.3, please also check the upgrade instructions for each subsequent release below. Specifically check upgrade instructions for 0.6.0. This release does not introduce any new table versions. The HoodieRecordPayload interface deprecated existing methods, in favor of new ones that also lets us pass properties at runtime. Users areencouraged to migrate out of the depr 5年前 (2021-01-31) 380℃ 0评论0喜欢
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展 5年前 (2021-01-28) 2670℃ 0评论10喜欢
1月15日,ElasticSearch 创始人、Elastic 公司 CEO Shay Banon 宣布,将把 Elasticsearch 和 Kibana 的 Apache 2.0-licensed 源码协议修改成 SSPL(Server Side Public License、服务器端公共许可证)和 Elastic License 双重协议!并且让用户可以选择申请哪个许可。Shay Banon 说这个决策是为了限制云服务提供商提供 Elasticsearch和 Kibana 服务来保护 Elastic 公司在开发免费 5年前 (2021-01-23) 418℃ 0评论3喜欢
2021年01月21日,Apache 官方博客宣布 Apache® Superset™ 成为顶级项目。Apache® Superset™ 是一个现代化的大数据探索和可视化平台,它允许用户使用简单的无代码可视化构建器和最先进的 SQL 编辑器轻松快速地构建仪表盘(dashboards)。该项目于2015年在 Airbnb 启动,并于2017年5月进入 Apache 孵化器。说白了,其实 Apache Superset 算是一个大数据 5年前 (2021-01-22) 814℃ 0评论1喜欢
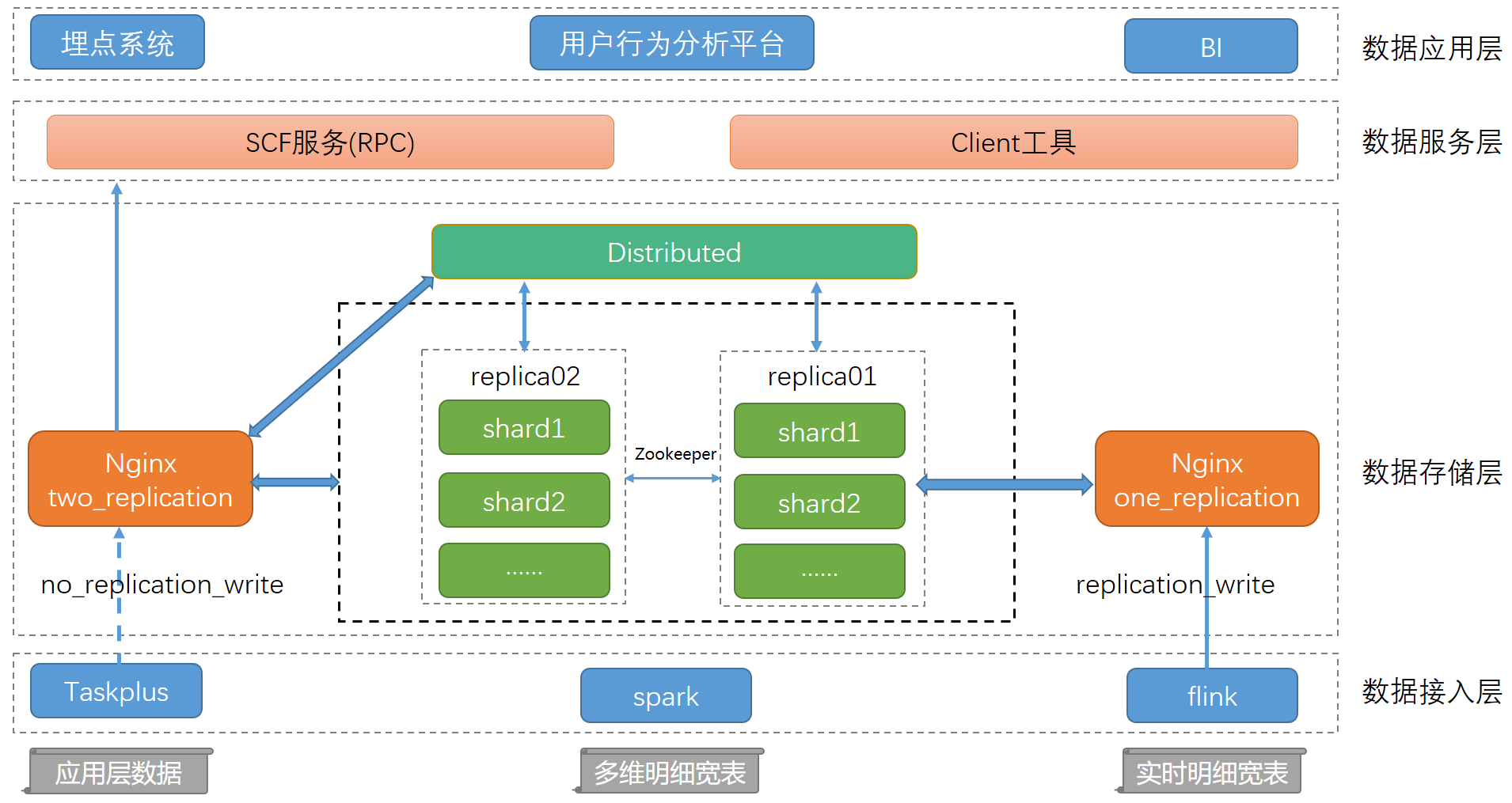
在数据量日益增长的当下,传统数据库的查询性能已满足不了我们的业务需求。而Clickhouse在OLAP领域的快速崛起引起了我们的注意,于是我们引入Clickhouse并不断优化系统性能,提供高可用集群环境。本文主要讲述如何通过Clickhouse结合大数据生态来定制一套完善的数据分析方案、如何打造完备的运维管理平台以降低维护成本,并结合具 5年前 (2021-01-22) 1948℃ 0评论2喜欢
由 Ahana 工程师 Vivek Bharathan、David E. Simmen 以及 George Wang 编写的《Learning and Operating Presto》图书计划在2021年11月发布,不过预览版已经可以下载了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书描述Presto 社区自2012年诞生于 Facebook 后迅速发展起来。但是,即使对最有经验的工程师来说 5年前 (2021-01-21) 578℃ 0评论2喜欢
1月15日,ElasticSearch 创始人、Elastic 公司 CEO Shay Banon 宣布,将把 Elasticsearch 和 Kibana 的 Apache 2.0-licensed 源码协议修改成 SSPL(Server Side Public License、服务器端公共许可证)和 Elastic License 双重协议!下面是 Shay Banon 修改 Elasticsearch 和 Kibana 开源协议的全文翻译。注:下面的我们是指 Elastic 公司(或 Shay Banon)我们正在将 ElasticSearch 5年前 (2021-01-17) 1246℃ 0评论4喜欢