背景 现状 HDFS 全称是 Hadoop Distributed File System,其本身是 Apache Hadoop 项目的一个模块,作为大数据存储的基石提供高吞吐的海量数据存储能力。自从 2006 年 4 月份发布以来,HDFS 目前依然有着非常广泛的应用,以字节跳动为例,随着公司业务的高速发展,目前 HDFS 服务的规模已经到达“双 10”的级别: 单集群节点 10 万台级别单 4年前 (2021-07-29) 743℃ 0评论2喜欢
本次的分享内容分成四个部分:系统概述:认识kudu,理解Kudu的系统设计与定位生产实践:分享网易内部的典型使用场景遇到的问题:实际使用过程中遇到的问题和问题的排障过程功能展望:对Kudu功能特性的展望Kudu定位与架构Kudu是一个存储引擎,可以接入Impala、Presto、Spark等Olap计算引擎进行数据分析,容易融入Hadoop社区 4年前 (2021-07-17) 355℃ 0评论1喜欢
我们在开发过程中,难免会进行一些误操作,比如下面我们提交 723cc1e commit 的时候把 2b27deb 和 0ff665e 不小心也提交到这个分支了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据0ff665e 是属于其他还没有合并到 master 分支的 MR,所以我们这里肯定不能把它带上来。我们需要把它删了。值得 4年前 (2021-07-09) 668℃ 0评论1喜欢
背景随着集群规模的不断扩张,文件数快速增长,目前集群的文件数已高达2.7亿,这带来了许多问题与挑战。首先是文件目录树的扩大导致的NameNode的堆内存持续上涨,其次是Full GC时间越来越长,导致NameNode宕机越发频繁。此外,受堆内存的影响,RPC延时也越来越高。针对上述问题,我们做了一些相关工作:控制文件数增长 4年前 (2021-07-02) 1441℃ 0评论4喜欢
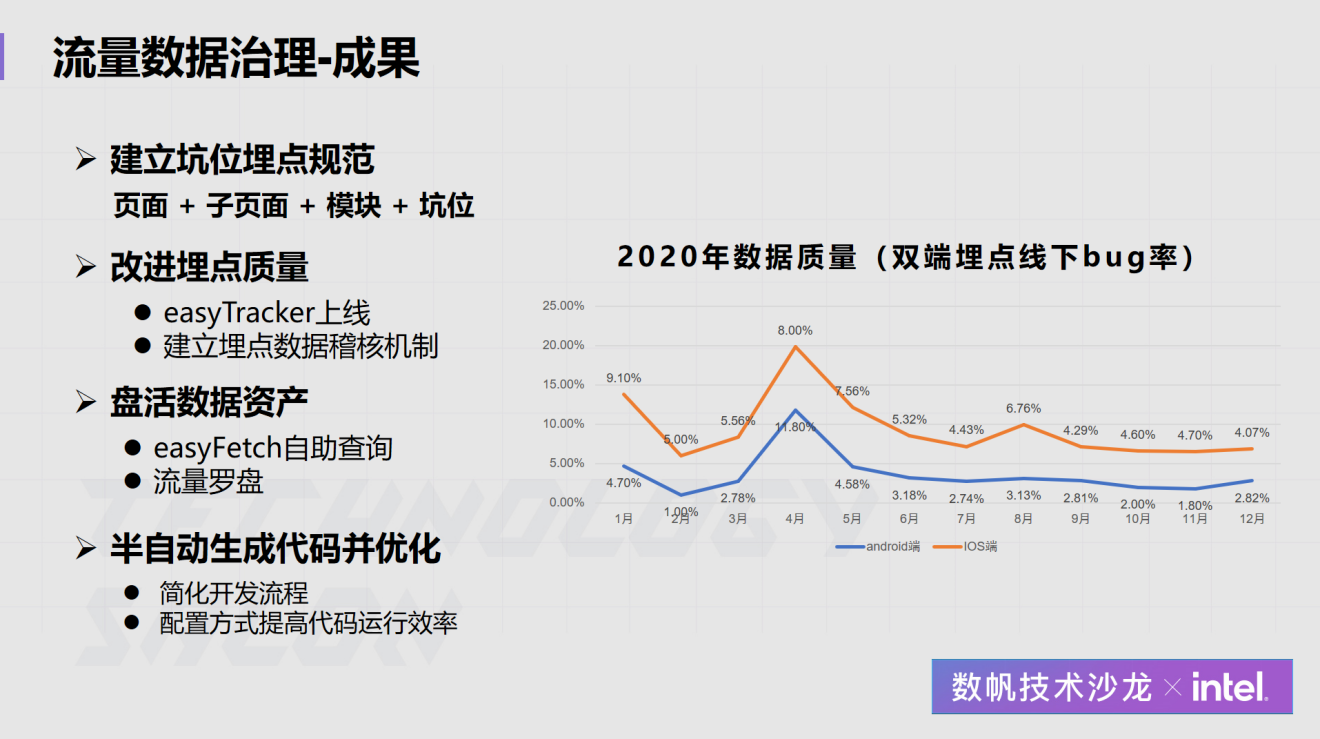
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 4年前 (2021-06-30) 1042℃ 0评论1喜欢
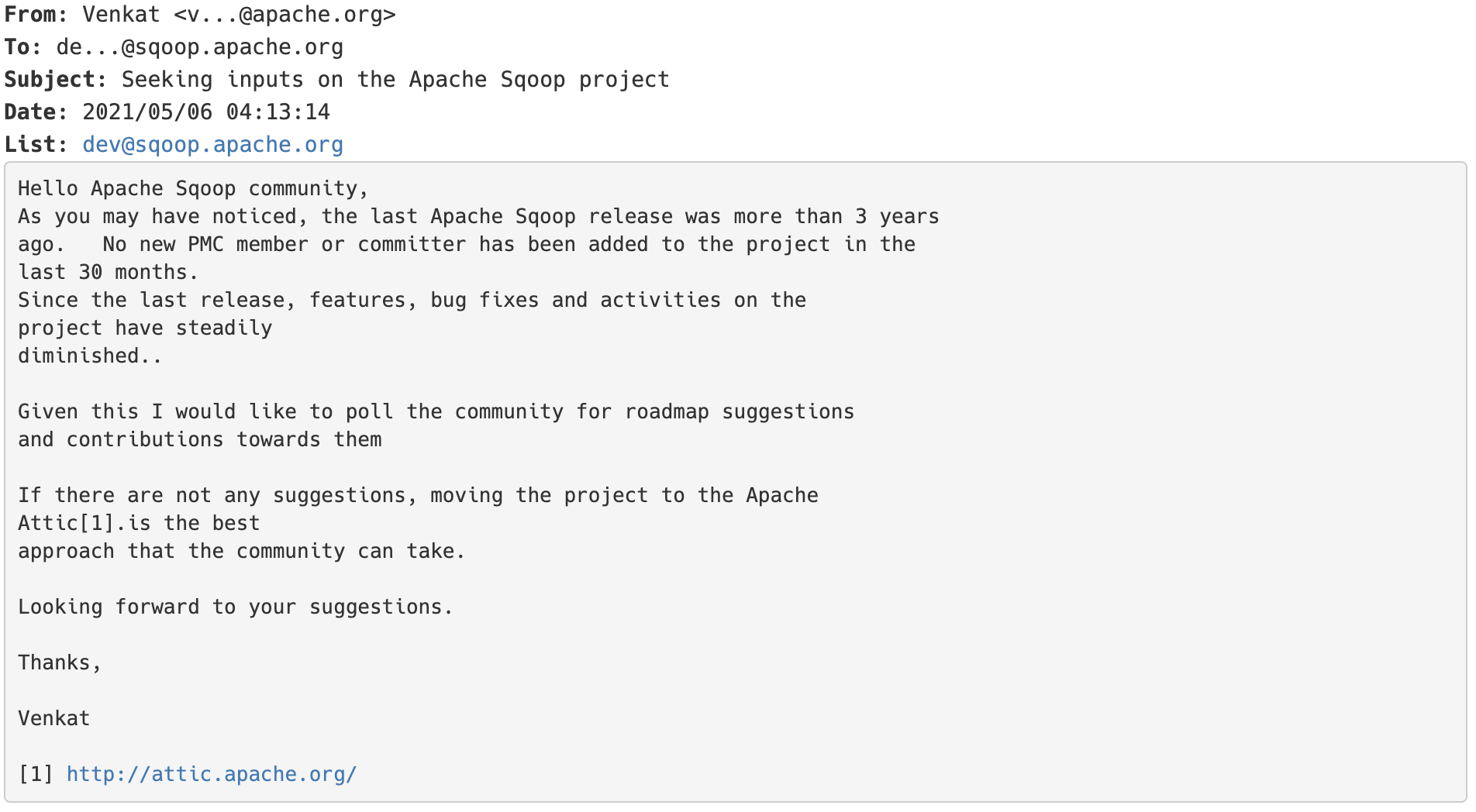
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 4年前 (2021-06-27) 835℃ 0评论2喜欢
和 MySQL 以及其他计算引擎类似,MongoDB 给我们提供了 explain 命令来查看某个查询的执行计划,其使用也比较简单,具体如下:[code lang="bash"]db.collection.explain().<method(...)>[/code]explain 命令默认是打印出查询的 queryPlanner,也就是什么参数都不传递。从 3.5.5 版本开始,explain 命名还支持 executionStats 和 allPlansExecution 两种运行模式 4年前 (2021-06-21) 479℃ 0评论0喜欢
Data + AI Summit 2021 于2021年05月24日至28日举行。本次会议是在线举办的,一共为期五天,第一、二天是培训,第三天到第五天是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta Lake、MLflow、Structured Streaming、BI和SQL分析、深度学习和机器学习 4年前 (2021-06-20) 1700℃ 0评论3喜欢
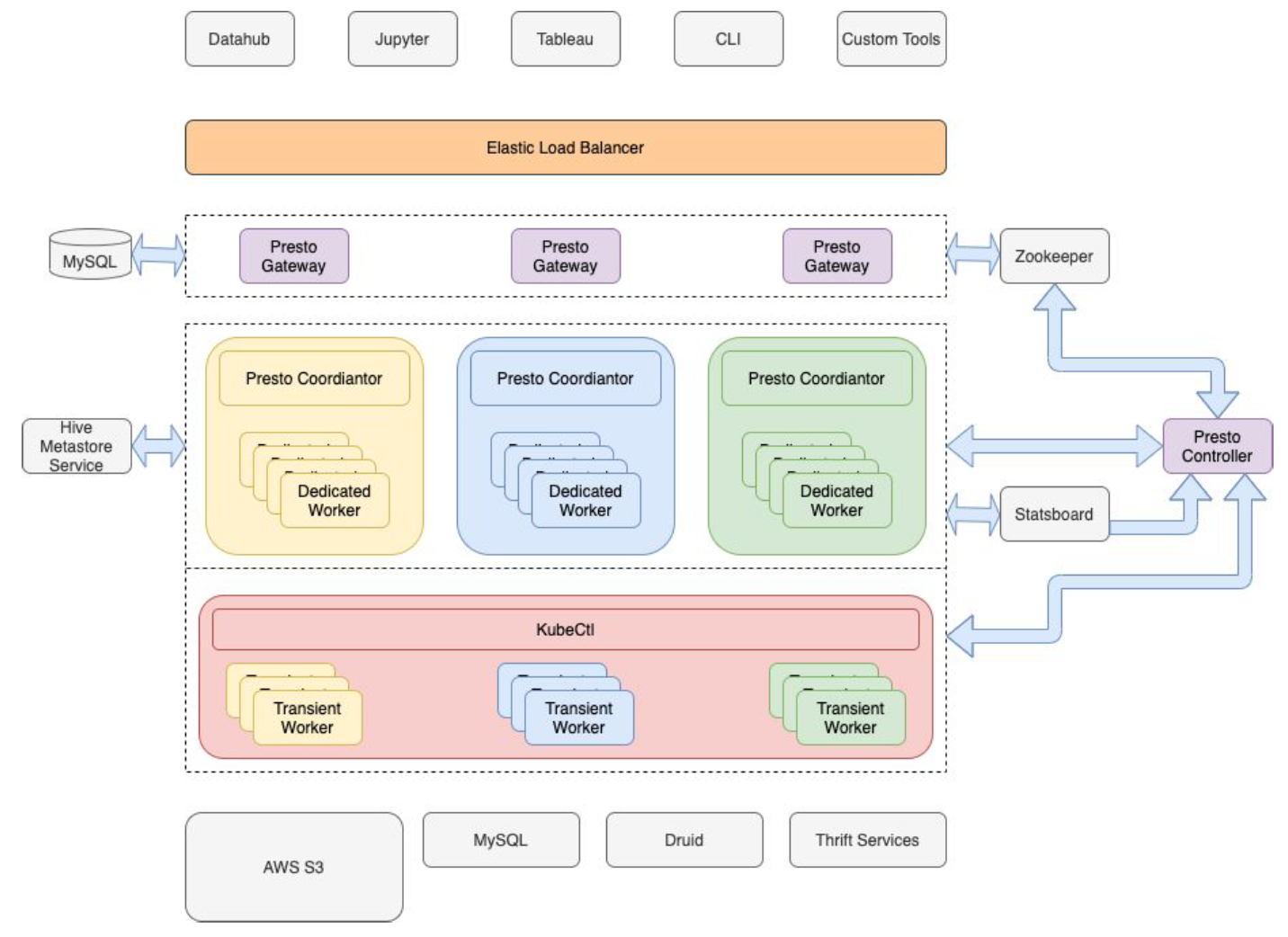
作为一家数据驱动型公司,Pinterest 的许多关键商业决策都是基于数据分析做出的。分析平台是由大数据平台团队提供的,它使公司内部的其他人能够处理 PB 级的数据,以得到他们需要的结果。数据分析是 Pinterest 的一个关键功能,不仅可以回答商业问题,还可以解决工程问题,对功能进行优先排序,识别用户面临的最常见问题, 4年前 (2021-06-20) 678℃ 0评论0喜欢
Apache HAWQ(incubating)的第一个版本受益于ASF(Apache software foundation)组织,通过将MPP(Massively Parallel Processing)和批处理系统(batch system)有效的结合,在性能上有了很大的提升,并且克服了一些关键的限制问题。一个新的重新设计的执行引擎在以下的几个问题在总体系统性能上有了很大的提高:硬件错误引起的短板问题(straggler)并发限制 4年前 (2021-06-18) 1221℃ 0评论0喜欢