NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 4年前 (2020-05-15) 687℃ 0评论2喜欢
我们使用数据库可以快速访问业务数据,但是随着时间的推移,数据库会不断增长,提取信息所需的时间也会更长,数据操作成为瓶颈。这时候我们就需要对数据进行分区(partition)了。分区是将数据库或其组成元素划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性或负载平衡的原因而进行的。在分布式数据 4年前 (2020-05-14) 1052℃ 0评论2喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中 4年前 (2020-05-14) 2114℃ 0评论4喜欢
我已经在之前的 《一条 SQL 在 Apache Spark 之旅(上)》、《一条 SQL 在 Apache Spark 之旅(中)》 以及 《一条 SQL 在 Apache Spark 之旅(下)》 这三篇文章中介绍了 SQL 从用户提交到最后执行都经历了哪些过程,感兴趣的同学可以去这三篇文章看看。这篇文章中我们主要来介绍 SQL 查询计划(Query Plan)常见的处理模型(processing model)。数 4年前 (2020-05-13) 1624℃ 0评论6喜欢
OpenCSVSerde 使用大家使用 Hive 分析数据的时候,CSV 格式的数据应该是很常见的,所以从 0.14.0 开始(参见 HIVE-7777) Hive 跟我们提供了原生的 OpenCSVSerde 来解析 CSV 格式的数据。从名字可以看出,OpenCSVSerde 是基于 Open-CSV 2.3 类库实现的,其解析 csv 的功能还是很强大的。为了在 Hive 中使用这个 serde,我们需要在建表的时候指定 row form 4年前 (2020-05-04) 1627℃ 0评论3喜欢
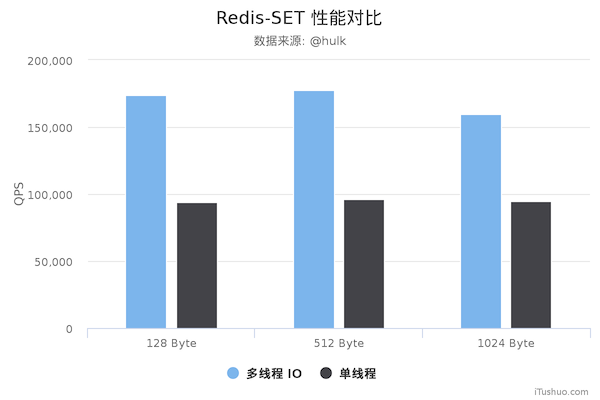
五一期间,Redis 6.0.0 稳定版(GA)终于发布,Redis 6.0 最终的发布一共经历了四个 RC(Release Candidate)版,从第一个候选版本的发布到一个稳定版本前后经历了大概四个半月(Redis 6.0 RC1 于 2019-12-19 发布)。Redis 6 是 Redis 有史以来最大的版本,虽然现在发布了 GA 版,但是在将它投入生产之前仍然需要谨慎。本文将介绍 Redis 6.0 RC1 到 GA 4年前 (2020-05-01) 1210℃ 0评论4喜欢
Apache Kafka 2.5.0 稳定版于美国当地时间2020年4月15日正式发布,这个版本包含了一系列的重要功能发布,比较重要的可以特性重要包括:支持 TLS 1.3 (目前默认是用 1.2)Kafka Streams DSL 中支持 Co-groups; Kafka Consumer 支持增量再平衡(Incremental rebalance)为更好地洞察算子运行,引入了新的指标;Apache Zookeeper 升级到 3.5.7不再支持 Scala 4年前 (2020-04-19) 1498℃ 0评论3喜欢
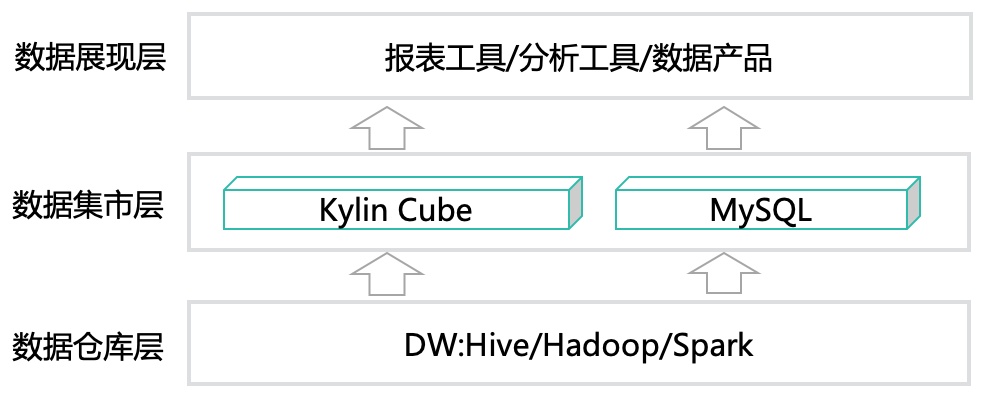
序言美团外卖数据仓库技术团队负责支撑日常业务运营及分析师的日常分析,由于外卖业务特点带来的数据生产成本较高和查询效率偏低的问题,他们通过引入Apache Doris引擎优化生产方案,实现了低成本生产与高效查询的平衡。并以此分析不同业务场景下,基于Kylin的MOLAP模式与基于Doris引擎的ROLAP模式的适用性问题。希望能对大家有 4年前 (2020-04-17) 2318℃ 0评论3喜欢
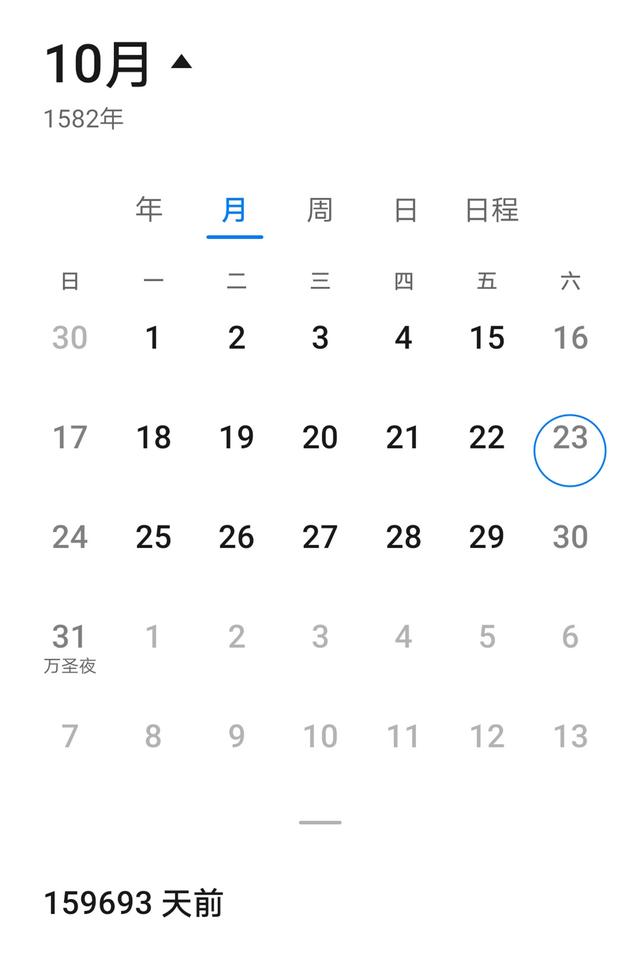
儒略历(Julian calendar)儒略历,是格里历(Gregorian calendar)的前身,由罗马共和国独裁官儒略·凯撒采纳埃及亚历山大的希腊数学家兼天文学家索西琴尼计算的历法,在公元前45年1月1日起执行,取代旧罗马历历法的历法。一年设12个月,大小月交替,四年一闰,平年365日,闰年于二月底增加一闰日,年平均长度为365.25日。因为1月1 4年前 (2020-04-16) 3711℃ 0评论10喜欢
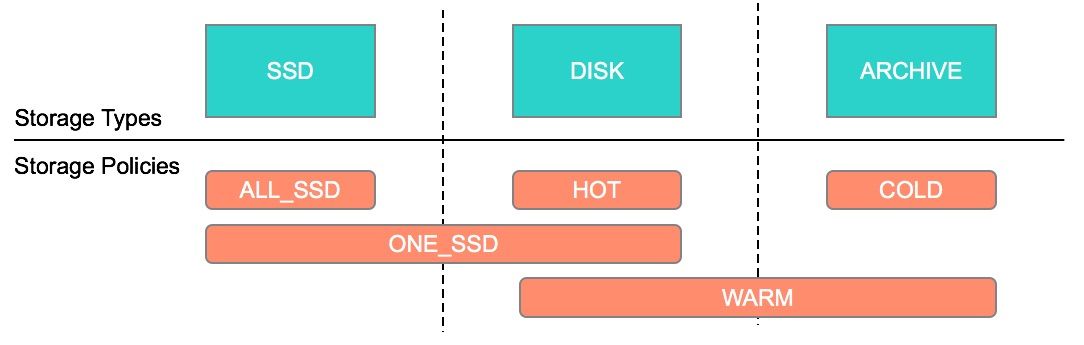
介绍HDFS 归档存储(Archival Storage)是从 Hadoop 2.6.0 开始引入的(参见 HDFS-6584)。归档存储是一种将增长的存储容量与计算容量解耦的解决方案。我们可以在集群中部署一些具有更高密度、更便宜的存储且提供更低计算能力的节点,并且可以用作集群中的冷数据存储器。根据我们的设置,可以将热数据移到冷存储介质中。通过添加更 4年前 (2020-04-15) 1661℃ 0评论3喜欢