

hadoop更新实在是太快了,现在已经更新到Hadoop-2.3.0版本(2014-02-11)。看了一下文档,和之前Hadoop-2.2.0的文档大部分类似,这篇文章主要是翻译一下Hadoop-2.3.0的文档。
Apache Hadoop 2.3.0和之前的Hadoop-1.x稳定版有了很大的提升。本篇文章主要是简要说说Hadoop 2.3.0中的HDFS和Mapreduce的提升(4、5两个特性是Hadoop2.x开始就支持的)。
(1)、HDFS支持异构的存储结构:Support for Heterogeneous Storage hierarchy in HDFS;
(2)、HDFS数据可以缓存到内存中,支持集中式管理:In-memory cache for HDFS data with centralized administration and management.
(3)、在YARN中,将MapReduce类库从HDFS中分离出来:Simplified distribution of MapReduce binaries via HDFS in YARN Distributed Cache.
(4)、HDFS Federation
为了提高name service的水平扩展性,HDFS Federation用到了多个互相独立的NameNodes/Nodespaces。这些NameNodes之间是联合的关系,这就是说,这些NameNodes之间是独立的,并且NameNodes之间也不需要互相协作。DataNode主要是被所有的NameNodes存储块数据。所有的DataNode都需要向集群中所有的NameNode注册自己,DataNodes会每隔一段时间向所有的NameNode发送心跳和处理来自NameNode的命令。
更多关于HDFS Federation,请参见《 HDFS Federation》。
(5)、下一代的Mapreduce(也称为YARN,MRv2)
Hadoop 2.3.0的体系结构把以前JobTracker的两个主要的功能分开来了,这两个主要的功能为:资源管理和作业管理。新的资源管理器管理全局的资源分配;而每个application的ApplicationMaster管理自己的作业调度和协作。
每一个application在典型的MapReduce中是一个单独的作业;同时你也可以把application看作一个DAG(有向循环图)。
从计算角度看,ResourceManager和每台机器上的NodeManager守护线程管理在那台机器上用户提交的作业。
实际上,每个application的ApplicationMaster是一个特殊的框架库,负责和ResourceManager谈判以此得到需要的资源,并且和NodeManager(s)一起工作来运行和监控作业。
下图是Hadoop1.x和Hadoop2.x之间架构的变化。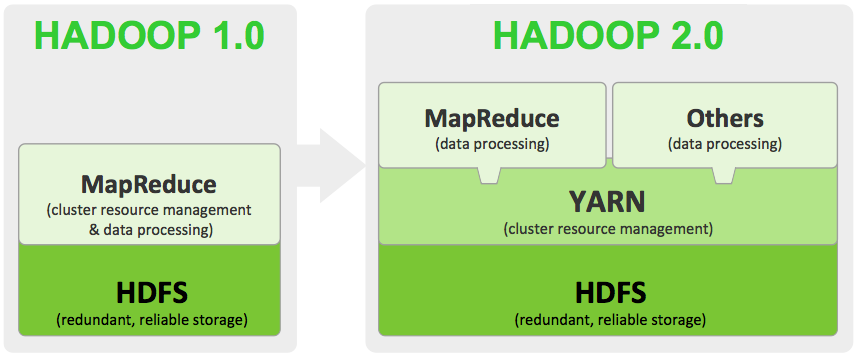
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Hadoop 2.3.0三大重要的提升】(https://www.iteblog.com/archives/959.html)







