文章目录
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache 2.0 切换到 Confluent Community License,参见这里,下面是这篇文章的全部翻译。
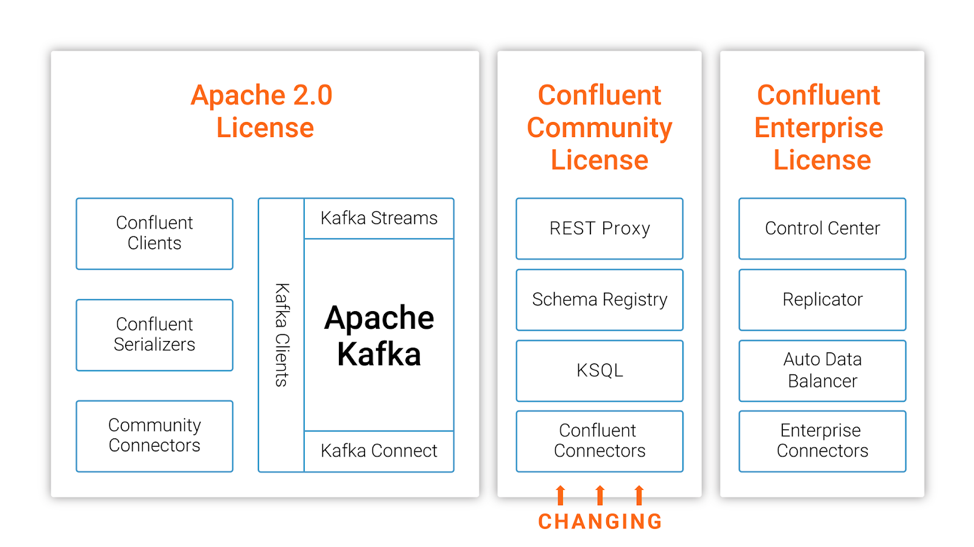
我们正在将 Confluent 平台的某些组件的许可证从 Apache 2.0 更改为 Confluent社区许可证(Confluent Community License)。 这个新许可证允许您免费下载,修改和重新分发代码(非常类似于 Apache 2.0),但它不允许您将软件作为 SaaS 产品提供给其他用户。
这些措施意味着什么呢?比如,你可以使用 KSQL,并觉得这个非常适合作为你自己的产品或服务的一部分,无论这些产品是以软件形式还是作为 SaaS 提供;但你无法创建 KSQL 即服务(KSQL-as-a-service)的产品。 我们接下来的开发仍然是开放的,同时也接受拉取请求(pull requests)和功能建议(feature suggestions)。 对于那些不是商业云提供商的用户,即这些项目的 99.9999% 的用户,这对他们来说没有任何有意义的限制,同时允许我们继续大力投入于研发。
这个措施对 Apache Kafka 没有任何影响,Apache Kafka 是作为 Apache Software Foundation 的一部分进行开发的,其仍然是使用 Apache 2.0 许可,并且我们将继续积极地为此做出贡献,这次协议的修改只会影响 Confluent 维护的开源组件。
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
为什么要这么做
我们认为这是很必要的一步。这使我们可以继续大量投资我们免费分发的代码,同时保持业务的健康发展,为这种投入提供资金。我会解释为什么这两件事都很重要。
首先,这种投资是否必要? 对于许多简单的开源项目,我认为没有必要。 有成千上万的库在 GitHub 上蓬勃发展,除了一些志愿者贡献之外,不需要太多的投资。 分布式数据系统是不同的,构建一个成功的新分布式数据平台是非常困难的。
你不需要接受我说的话,但事实证明就是如此。2009 - 2010 年期间出现了数十个 NoSQL 数据库。有些是作为业余项目创建的,有些来自大型网络公司的内部基础设施,有些是作为商业项目创建的。我认为最明显的是,迄今为止能够继续保持竞争力的是那些有稳定商业实体来维持其开发的系统。 做到这一点的系统(MongoDB,ElasticSearch,Cassandra,Hadoop)都继续蓬勃地发展并成为现代堆栈的一部分。那些没有相关商业公司的支持的系统(Voldemort,Dynomite,CouchDB等),尽管早期受欢迎,但都已经被淘汰了。 它们可能仍然存在,但你很可能从未听说过它们。
这种差异的原因在我看来似乎很明显,我曾经参与了开源项目的开发,包括在 LinkedIn 公司作为志愿者参与,或者是作为 Confluent 的一部分。当我们最初在 LinkedIn 开发 Kafka 时,我所在的团队在大部分时间总共就几人。我利用圣诞节假期编写了原始代码库,因为该项目没有官方资源。那个小型的 Kafka 团队编写了代码,运行服务,倾向于开源社区,并最终说服 LinkedIn 将项目转移到 Apache。 这意味着在白天编写代码,然后处理向社区报告的 issues 和 bugs;晚上召开一些会议,并在深夜醒来处理一些偶尔会出现的操作问题。但随着社区的发展,需求增长得更快:外部补丁的代码审查常常滞后,而 Java 之外的客户端基本上运行不了。
Confluent 的建立使我们的投资远远超过 LinkedIn。很多纯粹是在激情基础上深夜做出贡献的人现在可以得到报酬,并全职参与工作。 Confluent 不仅可以为代码贡献提供资金,还可以为运行大规模分布式压力测试所需的大笔云费用支付费用,以确保代码库稳定,同时扩展来自不断增长社区的贡献,虽然代码依然不完美,但改进的速度却大大加快了。
换句话说,我相信企业可以帮助开源贡献的良性循环。
在数据系统作为内部部署软件交付的世界中,我们已经找到了如何建立可推动这种良性循环的可持续发展公司。这并不容易,但创办公司向来不容易。在这个模型中,我们发现 Apache 2.0 等许可的开源许可是维持软件产品健康蓬勃发展的主要组成部分。然而随着云行业的兴起,世界已经发生了巨大的变化,这云服务提供了软件即服务的产品。在这个新世界中,云提供商具有明显优势:他们控制所有服务提供商使用资源的定价,并且可以在他们的所有产品中集成自己的服务。
主要的云提供商(亚马逊,微软,阿里巴巴和谷歌)在开源的态度都有所不同。其中一些公司与开源公司合作,这些公司提供其系统的托管版本作为服务。其他人采用开源代码,将其引入到云产品中,并将自己的所有投资都投入到差异化的专有产品中。我并不想从道德上来评价这种行为,这些公司只是遵循其商业利益并在软件许可允许的范围内行事。
作为一家公司,我们可以追求的一个解决方案是为我们构建更多专有软件,并在开源方面减少投资。 但我们认为构建基础架构层的正确方法是使用开源代码。随着工作负载迁移到云端,我们需要一种机制来保持自由,同时实现投资周期,这是我们转变许可的动力。
我们认为这是积极的变化,可以帮助确保小型开源社区没有充当科技巨头免费的、不可持续发展的研发工具,科技巨头们将持续性资源只投入到它们自己的差异化专有产品中。
这么做意味着什么
我认为新的许可证很简单,即使对于非律师也能理解;在许可证和本公告中,我们都试图尽可能地预先考虑我们想要允许的做法,我们想要阻止的做法,以及为什么。
这个公告让我担心有两种愤世嫉俗的解释。首先,这表明 Confluent 正处于困境,需要这样做才能赚钱。事实并非如此,Confluent 的表现非常出色,我们认为这对我们的客户以及我们投资社区和开源的能力来说都是一件很棒的事情。我们之所以这么做的目标是确保我们能够保持这种增长,并继续投资开源免费的产品。
具有讽刺意味的是,第二种玩世不恭的解释恰恰相反:这是一种贪婪策略的一部分,以便通过一个贪婪的公司提取更多的钱。与此相反,我只能这样说:Confluent 并非是为了赚钱而创建的。我们对现代数据驱动型公司并以事件流为中心的架构有一个愿景,我们希望在世界上实现这一目标。 Confluent 是一群相信这个想法的人,对于我们中的许多人来说,我们在这个项目上的工作早于 Confluent 本身。 构建代码和社区方面的早期工作并不是将其实现商业化的长达十年的计划的一部分。相反,我们认为围绕事件流重新设计世界上所有公司的计划是一个大胆的计划,需要做大量的工作。这一变化使我们能够在未来几十年继续开展这项工作,为软件、社区和实践做贡献,从而实现这一目标。
当然,这些并不意味着我们不是商业实体,或者不会专注于我们正在建立的业务。如果我们取得成功,流媒体平台将成为公司架构的核心,与关系数据库一样,将成为重要,有价值和战略性的数据平台。 我们认为这代表了一个巨大的范式转变,并将成为一个梦幻般的业务的基础。我们认为,这代表一次巨大的范式转变,并且将是伟大商业的基础。
几个典型的问答
这个改变对 Apache Kafka 有什么影响
并没有影响。我们继续在 Apache 2.0 许可下通过 ASF 为 Apache Kafka 做出贡献。
我可以下载,修改或重新分发代码吗?
当然可以,代码仍然在 GitHub 上维护,地址:https://github.com/confluentinc。
我可以将代码嵌入我分发的软件中吗?
当然可以
我可以使用代码构建SaaS产品吗?
几乎在所有情况下是可以的。如果您正在构建 SaaS 产品,则可以使用 Confluent 社区软件。 唯一的限制是托管服务产品,它将软件作为我们自己的软件托管服务的竞争产品提供, 例如,要是 KSQL 本身就是提供的产品,那么你就无法构建 SaaS 产品。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Kafka 团队修改 KSQL 开源许可证,禁止其作为 SaaS 产品来提供】(https://www.iteblog.com/archives/2480.html)