

在过去,Spark UI一直是用户应用程序调试的帮手。而在最新版本的Spark 1.4中,我们很高兴地宣布,一个新的因素被注入到Spark UI——数据可视化。在此版本中,可视化带来的提升主要包括三个部分:
- Spark events时间轴视图
- Execution DAG
- Spark Streaming统计数字可视化
我们会通过一个系列的两篇博文来介绍上述特性,本次则主要分享前两个部分——Spark events时间轴视图和Execution DAG。Spark Streaming统计数字可视化将在下一篇博文中解释。
Spark events时间轴视图
从Spark 初期版本至今,Spark events一直是面向用户API的一部分。在最新的1.4版本,Spark UI将会把这些events在一个时间轴中显示,让用户可以一眼区别相对和交叉顺序。
时间轴视图可以覆盖3个等级:所有Job,指定的某个Job,以及指定的某个stage。在下图中,时间轴显示了横跨一个应用程序所有作业中的Spark events。
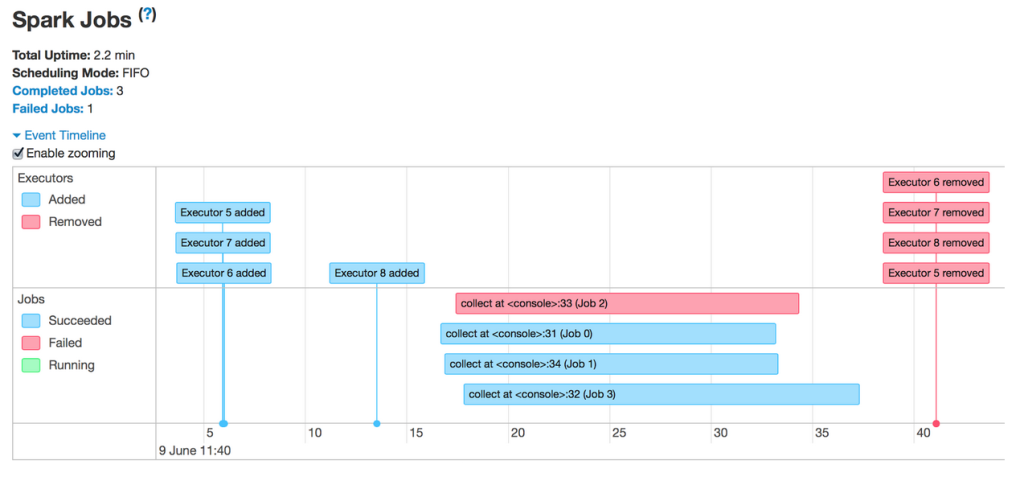
这里的events顺序相对简单,在所有 executors 注册后,在应用程序并行运行的4个job中,有一个失败,其余成功。当所有工作完成,并在应用程序退出后,executors同样被移除。下面不妨点击关注其中的一个job:

该job在3个文件中做word count,最后join并输出结果。从时间轴上看,很明显, 3个 word count stages 并行运行,因为它们不互相依赖。同时,最后一个阶段需要依赖前3个文件word count的结果,所以相应阶段一直等到所有先行阶段完成后才开始。下面着眼单个stage:

这个stage被切分为20个partitions,分别在4台主机上完成(图片并没有完全显示)。每段代表了这个阶段的一个单一任务。从这个时间轴来看,我们可以得到这个stage上的几点信息。
首先,partitions在机器中的分布状态比较乐观。其次,大部分的任务执行时间分配在原始的计算上,而不是网络或I/ O开销。这并不奇怪,因为传输的数据很少。最后,我们可以通过给executors分配更多的核心来提升并行度;从目前来看,每个executors可以同时执行不超过两个任务。
借此机会展示一下Spark通过该时间轴获得的另一个特性——动态分配。该特性允许Spark基于工作负载来动态地衡量executors 的数量,从而让集群资源更有效地共享。不妨看向下张图表:

首先要注意的是,这个应用程序是在工作的过程中获得executors ,而不是预先分配好。在第一个job结束后,用于该job的executors将闲置并返回到集群。因此在这个期间,同集群中运行的其他应用程序可以获得这些资源,从而增加集群资源利用率。只有当一个新的job执行时,Spark应用程序才会获取一组新的executors 来运行它。
在一个时间轴中查看Spark events的能力有助于确定应用程序瓶颈,从而在调试过程中进行更有针对性的优化。
Execution DAG
在新版本的Spark中,第二个可视化聚焦DAG执行的每个作业。在Spark中,job与被组织在DAG中的一组RDD依赖性密切相关,类似下图:
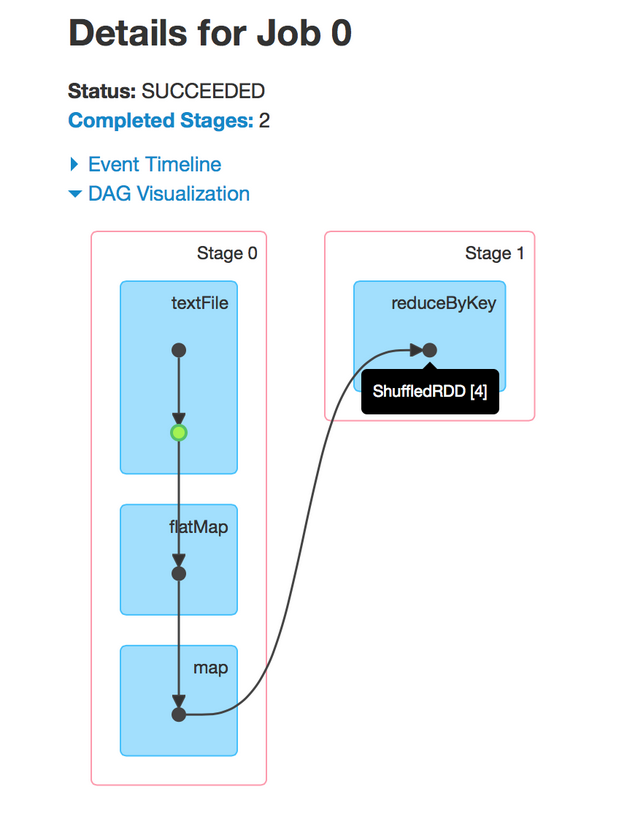
这个job执行一个简单的word cout。首先,它执行一个textFile从HDFS中读取输入文件,然后进行一个flatMap操作把每一行分割成word,接下来进行一个map操作,以形成form(word,1)对,最后进行一个reduceByKey操作总结每个word的数值。
可视化的蓝色阴影框对应到Spark操作,即用户调用的代码。每个框中的点代表对应操作下创建的RDDs。操作本身由每个流入的stages划分。
通过可视化我们可以发现很多有价值的地方。首先,根据显示我们可以看出Spark对流水线操作的优化——它们不会被分割。尤其是,从HDF S读取输入分区后,每个executor随后即对相同任务上的partion做flatMap和map,从而避免与下一个stage产生关联。
其次,RDDs在第一个stage中会进行缓存(用绿色突出表示),从而避免对HDFS(磁盘)相关读取工作。在这里,通过缓存和最小化文件读取可以获得更高的性能。
DAG可视化的价值在复杂jobs中体现的尤为明显。比如下图中的ALS计算,它会涉及到大量的map、join、groupByKey操作。
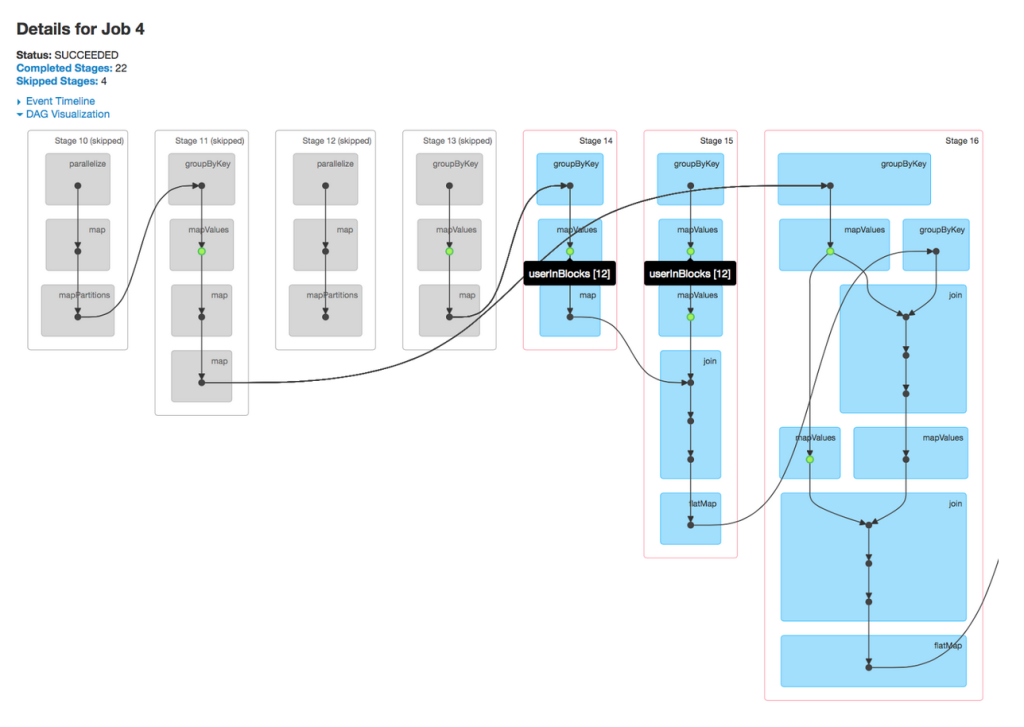
值得注意的是,在ALS中,缓存准确性将对性能产生的影响非常大,因为该算法在每次迭代中会重度使用之前步骤产生的结果。如今通过DAG可视化,用户和开发人员可以一目了然地查明RDDS是否被恰当地缓存,如果没有,可以快速理理解实现缓慢的原因。
与时间轴视图一样,DAG可视化允许用户点击进入一个stage进行更详细地观察。下图描述了ALS中一个独立的stage:
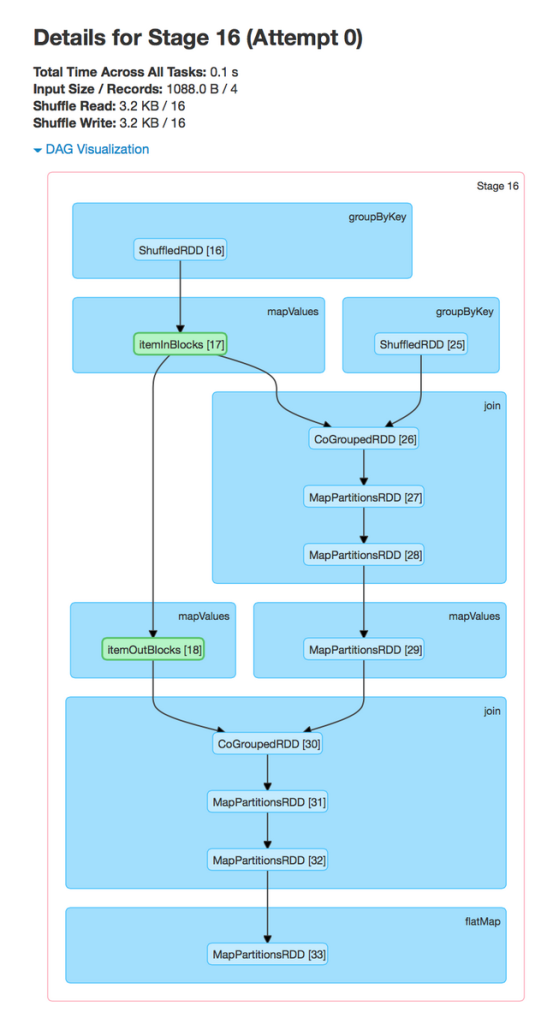
在stage视图中,属于这个stage的所有RDDS细节被自动展开。当前,用户可以快速地找到具体的RDDS信息,而不必job页面通过悬停各个点来猜测和检查。
最后,在这里突出一下DAG可视化和 SparkSQL之间的一个初步的集成。对比更接近物理实体层面的Spark操作,Spark SQL用户显然更熟悉一些高级操作,因此一些高级操作更需要被可视化。其结果类似将一个SQL查询计划映射到底层执行的DAG。
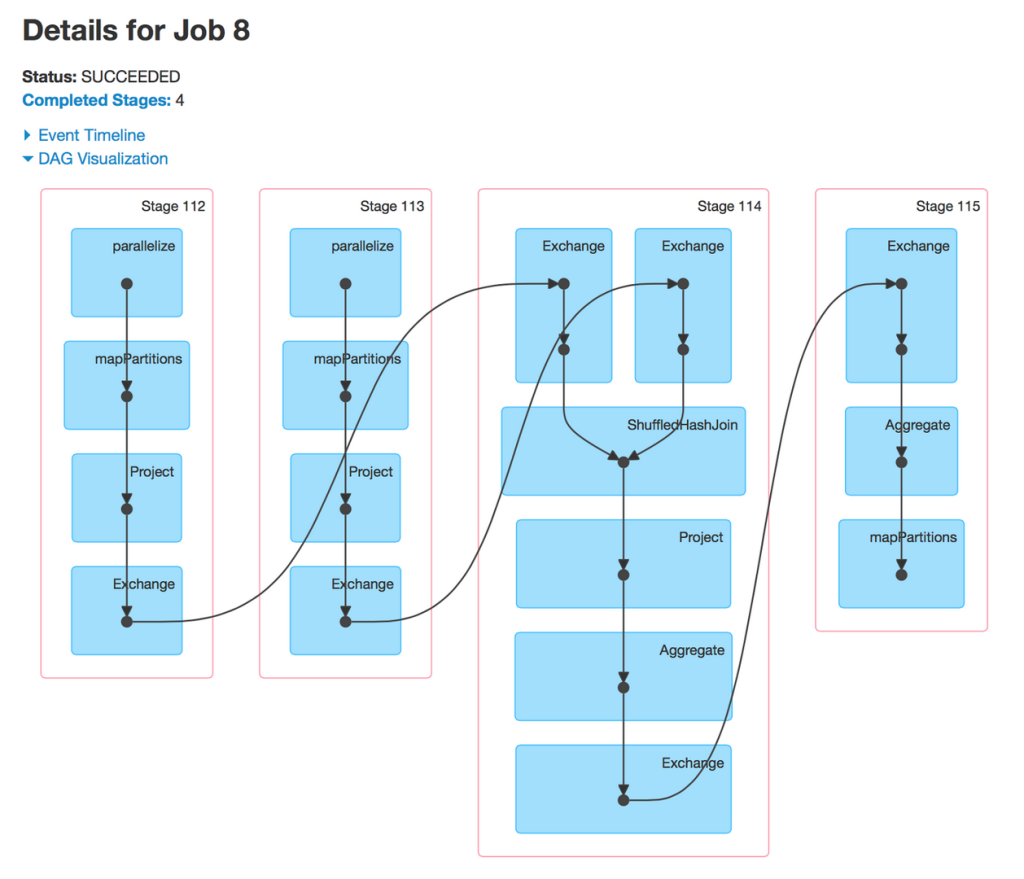
与SparkStreaming的整合在Spark 1.4版本中同样有所实现,这里在下一篇博文中会详细介绍。
在不久的将来,Spark UI可以更理解一些更高级别的函数库语义,以提供更多相关细节。 同时,Spark SQL将与Spark Streaming一样获得类似的标签。而在Spark Core中,当用户查看RDD时,类似partitions数量、调用点、缓存率都将会被可视化。
英文原文:https://databricks.com/blog/2015/06/22/understanding-your-spark-application-through-visualization.html
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【通过可视化途径理解你的Spark应用程序】(https://www.iteblog.com/archives/1405.html)








太多的新功能了。。。