背景B站的YARN以社区的2.8.4分支构建,采用CapacityScheduler作为调度器, 期间进行过多次核心功能改造,目前支撑了B站的离线业务、实时业务以及部分AI训练任务。2020年以来,随着B站业务规模的迅速增长,集群总规模达到8k左右,其中单集群规模已经达到4k+ ,日均Applicati...... w397090770 3年前 (2022-04-11) 872℃ 0评论2喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最...... w397090770 4年前 (2021-09-18) 635℃ 0评论4喜欢
Efficient processing of big data, especially with Spark, is really all about how much memory one can afford, or how efficient use one can make of the limited amount of available memory. Efficient memory utilization, however, is not what one can take for ...... w397090770 5年前 (2020-09-09) 1020℃ 0评论0喜欢
2019 年 7 月 17 日,Cloudera 官方博客发文开源了一个内部研发使用很久的大数据存储和通用计算平台交叉的新项目 YuniKorn。Yunikorn 是一个新的独立通用资源调度程序,负责为大数据工作负载分配/管理资源,包括批处理作业和长时间运行的服务。介绍YuniKorn 是一种轻量级...... w397090770 6年前 (2019-07-17) 3912℃ 0评论0喜欢
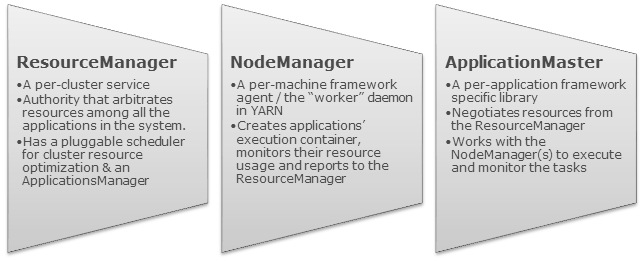
Apache YARN是将之前Hadoop 1.x的 JobTracker 功能分别拆到不同的组件里面了,每个组件分别负责不同的功能。在Hadoop 1.x中, JobTracker 负责管理集群的资源,作业调度以及作业监控;YARN把这些功能分别拆到ResourceManager 和 ApplicationMaster 中了。而之前的TaskTracke...... w397090770 8年前 (2017-06-01) 4128℃ 0评论31喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=con...... w397090770 9年前 (2016-12-29) 4313℃ 1评论11喜欢
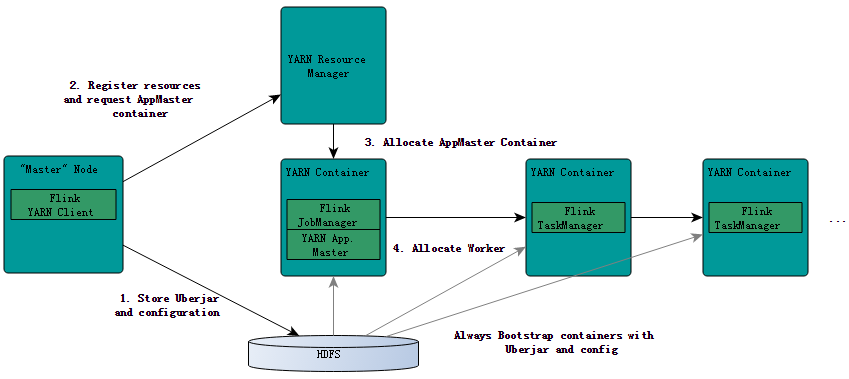
在前面(《Flink on YARN部署快速入门指南》的文章中我们简单地介绍了如何在YARN上提交和运行Flink作业,本文将简要地介绍Flink是如何与YARN进行交互的。 YRAN客户端需要访问Hadoop的相关配置文件,从而可以连接YARN资源管理器和HDFS。它使用下面的规则来决定Hadoop配...... w397090770 9年前 (2016-04-04) 6076℃ 0评论8喜欢
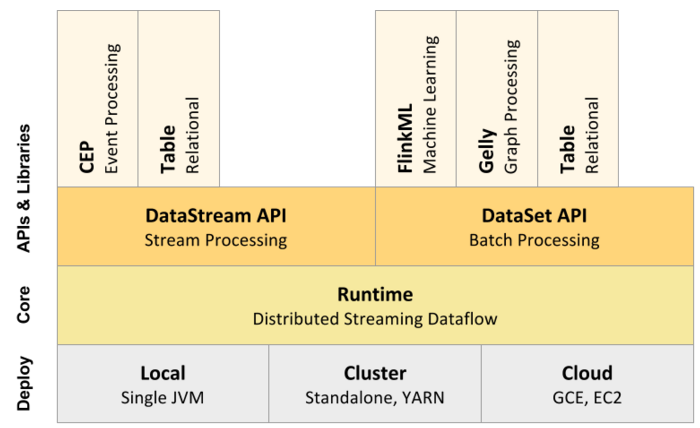
Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。 从Flink官方...... w397090770 9年前 (2016-03-30) 24404℃ 6评论22喜欢
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HO...... w397090770 10年前 (2016-01-22) 12149℃ 16评论12喜欢
我使用的是Spark 1.5.2和HDP 2.2.4.8,在启动spark-shell的时候出现了以下的异常:[itebog@www.iteblog.com ~]$ bin/spark-shell --master yarn-client...at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala):10: error: not found: value sqlCon...... w397090770 10年前 (2016-01-15) 4705℃ 0评论2喜欢