在 Spark 或 Hive 中,我们可以使用 LATERAL VIEW + EXPLODE 或 POSEXPLODE 将 array 或者 map 里面的数据由行转成列,这个操作在数据分析里面很常见。比如我们有以下表:[code lang="sql"]CREATE TABLE `default`.`iteblog_explode` ( `id` INT, `items` ARRAY<STRING>)[/code]表里面的数据如下:[code lang="sql"]spark-sql> SELECT * FROM iteblog_explode;1 ["iteblog.co w397090770 3年前 (2022-08-08) 2046℃ 0评论7喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 3年前 (2022-07-20) 1380℃ 0评论1喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 3年前 (2022-07-10) 654℃ 0评论3喜欢
Presto 在 Facebook 的诞生最开始是为了填补当时 Facebook 内部实时查询和 ETL 处理之间的空白。Presto 的核心目标就是提供交互式查询,也就是我们常说的 Ad-Hoc Query,很多公司都使用它作为 OLAP 计算引擎。但是随着近年来业务场景越来越复杂,除了交互式查询场景,很多公司也需要批处理;但是 Presto 作为一个 MPP 计算引擎,将一个 MPP 体 w397090770 3年前 (2022-06-23) 1691℃ 0评论3喜欢
Apache Spark 3.3.0 从2021年07月03日正式开发,历时近一年,终于在2022年06月16日正式发布,在 Databricks Runtime 11.0 也同步发布。这个版本一共解决了 1600 个 ISSUE,感谢 Apache Spark 社区为 Spark 3.3 版本做出的宝贵贡献。根据经验,这个版本应该不是稳定版,想在线上环境使用的小伙伴们可以再等等。如果想及时了解Spark、Hadoop或者HBase相关 w397090770 3年前 (2022-06-18) 2086℃ 0评论2喜欢
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于美国时间 2022 年 6 月 16 日 宣布,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。 以下内容译自 Apache Doris 官网(https://doris.apache.org/ )。Apache Doris 是一个基于 MPP 的现代化、高性能、实时的分析型数据库,以极速易用的 zz~~ 3年前 (2022-06-16) 693℃ 0评论2喜欢
今年的1月份,Cloudera 的工程师、Apache Ambari PMC 主席 Jayush Luniya 曾经给社区发了一份提议将 Apache Ambari 一定 Attic 的邮件。原因是在过去的两年里,Ambari 只发布了一个版本(2.7.6),大多数提交者(Committer)和 PMC 成员都没有积极参与到这个项目中来。按照 Apache 的项目生命周期(https://attic.apache.org/process.html),其应该是 reached its end of w397090770 3年前 (2022-06-12) 1109℃ 0评论0喜欢
一个功能健全的kafka集群可以处理相当大的数据量,由于消息系统是很多大型应用的基石,因此broker集群在性能上的缺陷,都会引起整个应用栈的各种问题。Kafka的度量指标主要有以下三类:1.Kafka服务器(Kafka)指标2.生产者指标3.消费者指标另外,由于Kafka的状态靠Zookeeper来维护,对于Zookeeper性能的监控也成为了整个Ka zz~~ 3年前 (2022-05-01) 1391℃ 0评论0喜欢
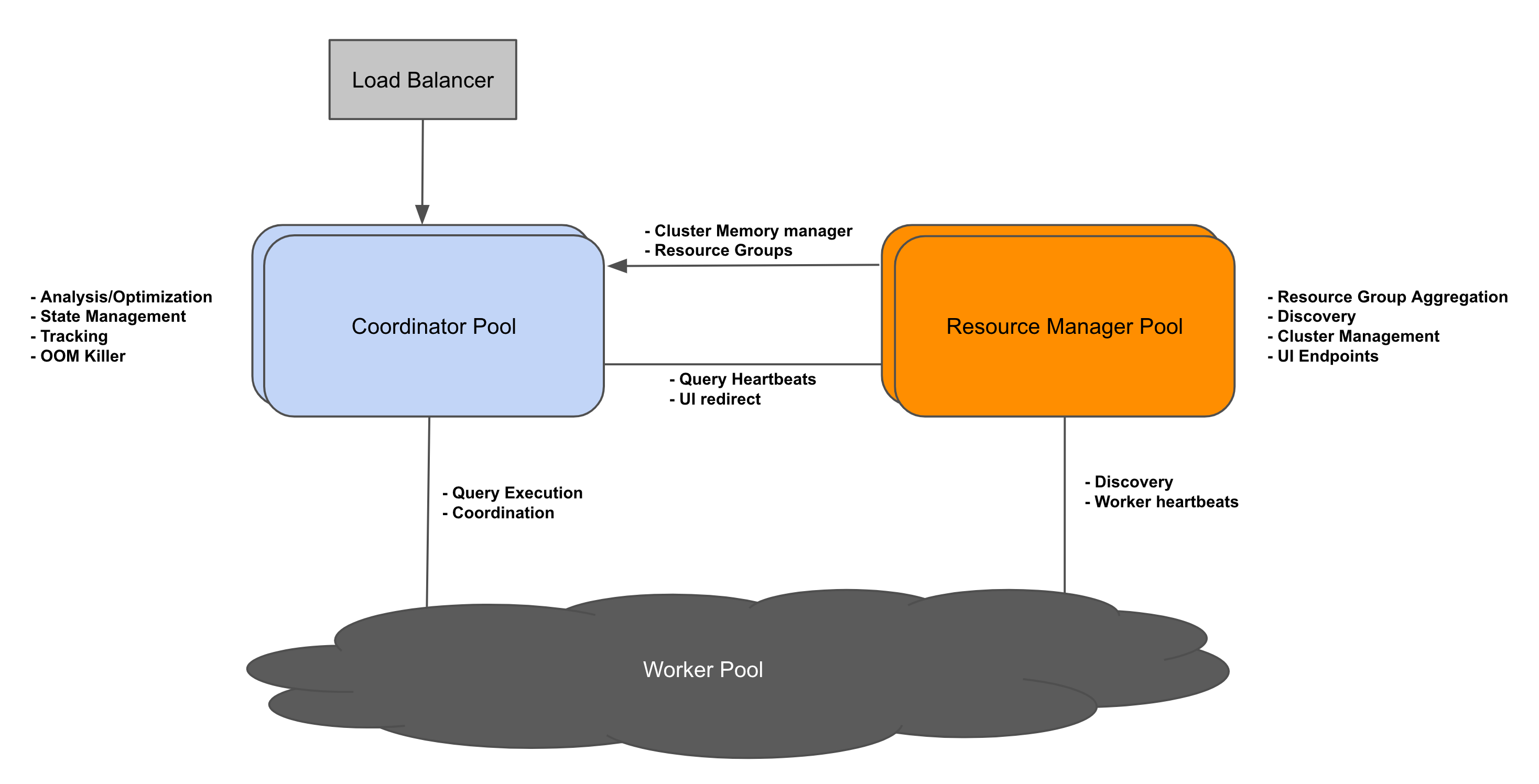
背景Presto 的架构最初只支持一个 coordinator 和多个 workers。多年来,这种方法一直很有效,但也带来了一些新挑战。使用单个 coordinator,集群可以可靠地扩展到一定数量的 worker。但是运行复杂、多阶段查询的大集群可能会使供应不足的 coordinator 不堪重负,因此需要升级硬件来支持工作负载的增加。单个 coordinator 存在单点故障 zz~~ 3年前 (2022-04-22) 969℃ 0评论1喜欢
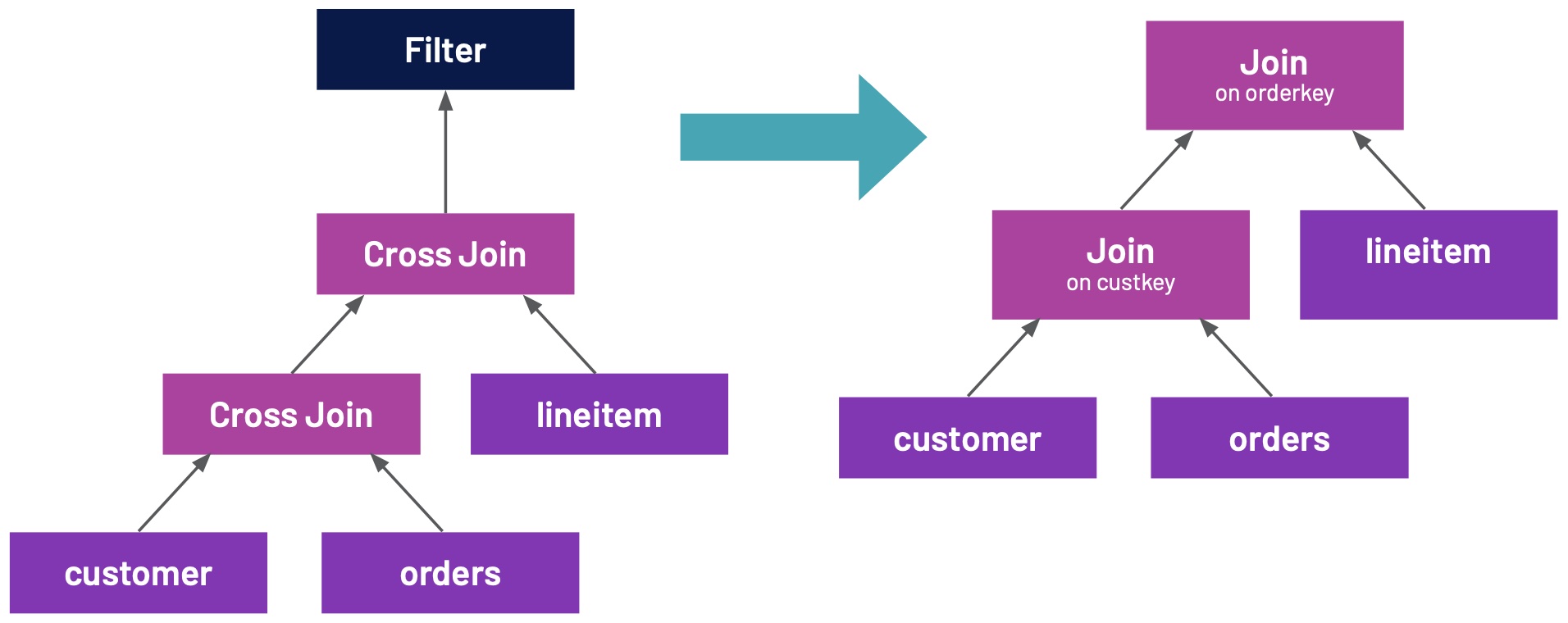
Depending on the complexity of your SQL query there are many, often exponential, query plans that return the same result. However, the performance of each plan can vary drastically; taking only seconds to finish or days given the chosen plan.That places a significant burden on analysts who will then have to know how to write performant SQL. This problem gets worse as the complexity of questions and SQL queries increases. In the abse w397090770 3年前 (2022-04-20) 659℃ 0评论1喜欢