Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖使用Apache Zeppelin 编译和启动完Zeppelin相关的进程之后,我们就可以来使用Zeppelin了。我们进入到https://www.iteblog.com:8080页面,我们可以在页面上直接操作Zeppelin,依次选择Notebook->Create new note,然后会弹出一个对话框 w397090770 8年前 (2016-02-03) 25189℃ 2评论31喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。本文所有的操作都是基于Apache Zeppelin w397090770 8年前 (2016-02-02) 20502℃ 9评论20喜欢
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:[code lang="bash"]export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/[/code]然后启动Zeppelin,但是我们有时会发现日志出现了以下的异常信息:ERRO w397090770 8年前 (2016-01-22) 12003℃ 16评论12喜欢
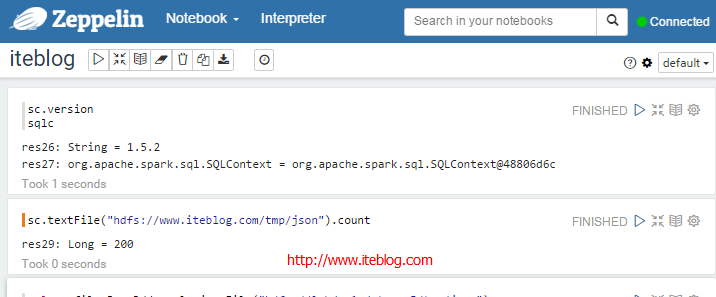
我下载的Apache Zeppelin和Apache Spark版本分别为:0.6.0-incubating-SNAPSHOT和1.5.2,在Zeppelin中使用SQLContext读取Json文件创建DataFrame的过程中出现了以下的异常:[code lanh="scala"]val profilesJsonRdd =sqlc.jsonFile("hdfs://www.iteblog.com/tmp/json")val profileDF=profilesJsonRdd.toDF()profileDF.printSchema()profileDF.show()profileDF.registerTempTable("profiles") w397090770 8年前 (2016-01-21) 6800℃ 2评论11喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 8年前 (2016-01-18) 7577℃ 0评论6喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 8年前 (2016-01-17) 22890℃ 0评论23喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 8年前 (2016-01-16) 6484℃ 0评论16喜欢
我使用的是Spark 1.5.2和HDP 2.2.4.8,在启动spark-shell的时候出现了以下的异常:[code lang="bash"][itebog@www.iteblog.com ~]$ bin/spark-shell --master yarn-client...at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala):10: error: not found: value sqlContext import sqlContext.implicits._:10: error: not found: value sqlContext import sqlContext.sql[/code]你打开Application w397090770 8年前 (2016-01-15) 4606℃ 0评论2喜欢
在本博客的《使用Spark SQL读取Hive上的数据》文章中我介绍了如何通过Spark去读取Hive里面的数据,不过有时候我们在创建SQLContext实例的时候遇到类似下面的异常:[code lang="java"]java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.ql.session.SessionState.start(Se w397090770 8年前 (2016-01-11) 16348℃ 5评论14喜欢
历时一个多月的投票和补丁修复,Apache Spark 1.6.0于今天凌晨正式发布。Spark 1.6.0是1.x线上第七个发行版.本发行版有来自248+的贡献者参与。详细邮件如下:Hi All,Spark 1.6.0 is the seventh release on the 1.x line. This release includes patches from 248+ contributors! To download Spark 1.6.0 visit the downloads page. (It may take a while for all mirrors to update.)A huge t w397090770 8年前 (2016-01-05) 2963℃ 1评论5喜欢