上海Spark Meetup第四次聚会将于2015年7月18日在太库科技创业发展有限公司举办,详细地址上海市浦东新区金科路2889弄3号长泰广场 C座12层,太库。本次聚会由七牛和Intel联合举办。大会主题 1、hadoop/spark生态的落地实践 王团结(七牛)七牛云数据平台工程师。主要负责数据平台的设计研发工作。关注大数据处理,高 w397090770 9年前 (2015-08-26) 2883℃ 0评论3喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 9年前 (2015-08-26) 7171℃ 1评论40喜欢
Apache Spark 1.5版本目前正在社区投票中,相信到9月初应该会发布。这里先剧透一下Apache Spark 1.5版本的一些重要的修改和Bug修复。Apache Spark 1.5有来自220多位贡献者的1000多个commits。这里仅仅是列出重要的修改和Bug修复,详细的还请参见Apache JIRA changelog.如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:itebl w397090770 9年前 (2015-08-26) 2871℃ 0评论6喜欢
下面的大数据学习电子书我会陆续上传,敬请关注。一、Hadoop1、Hadoop Application Architectures2、Hadoop: The Definitive Guide, 4th Edition3、Hadoop Security Protecting Your Big Data Platform4、Field Guide to Hadoop An Introduction to Hadoop, Its Ecosystem, and Aligned Technologies5、Hadoop Operations A Guide for Developers and Administrators6、Hadoop Backup and Recovery Solutions w397090770 9年前 (2015-08-11) 20350℃ 2评论54喜欢
一、活动时间 北京第九次Spark Meetup活动将于2015年08月22日进行;下午14:00-18:00。二、活动地点 北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼三、活动内容 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and w397090770 9年前 (2015-08-07) 2809℃ 0评论1喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 9年前 (2015-08-06) 11279℃ 6评论29喜欢
为什么选择Spark SequoiaDB是NoSQL数据库,它可以将数据复制到不同的物理节点上,而且用户可以在应用程序中指定使用哪个备份块。它能够在同一个集群中使用最少的I/O或者CPU来分析或者操作一些工作。 Apache Spark和SequoiaDB的整合允许用户创建单个平台来在同一个物理集群上同时运行多种不同的workloads 。Spark-SequoiaDB Conne w397090770 9年前 (2015-08-05) 4584℃ 0评论2喜欢
近日,由华为团队开发的Spark-SQL-on-HBase项目通过Spark SQL/DataFrame并调用Hbase内置的访问API读取HBase上面的数据,该项目具有很好的可扩展性和可靠性。这个项目具有以下的特点: 1、基于部分评估技术,该项目具有强大的数据剪枝和智能扫描特点; 2、支持自定义过滤规则、协处理器等以便支持超低延迟的处理; 3 w397090770 9年前 (2015-07-23) 22575℃ 0评论22喜欢
Apache Spark于北京时间2015年07月16日05点正式发布。Spark 1.4.1主要是维护版本,包含了大量的稳定性修复。该版本是基于branch-1.4分支。社区推荐所有1.4.0使用升级到这个稳定版本。此版本有85位开发者参与。 Spark 1.4.1包含了大量的Bug修复,这些Bug出现在Spark的DataFrame、外部数据源支持以及其他组建的一些bug修复。一些比较重要 w397090770 9年前 (2015-07-16) 4332℃ 0评论10喜欢
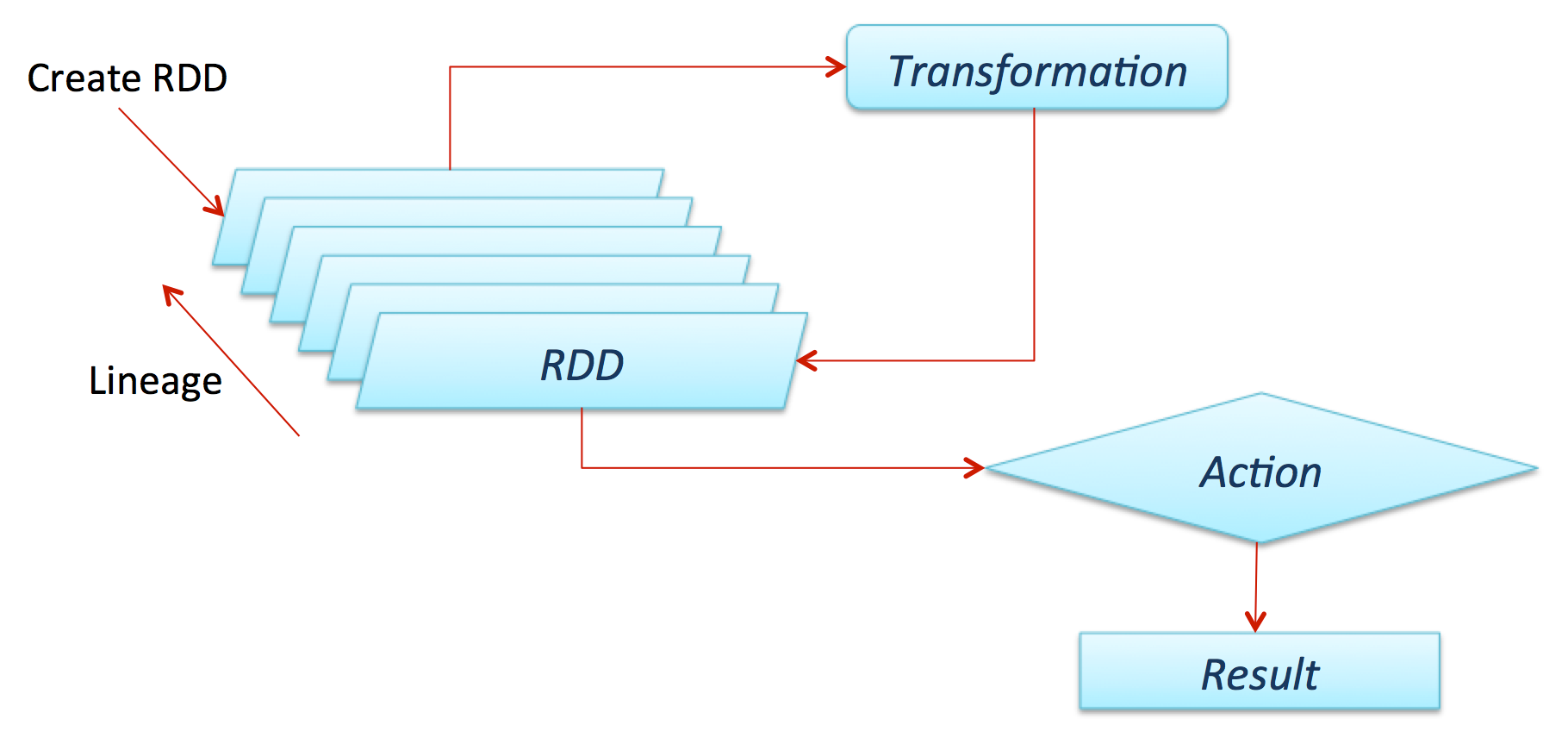
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》五、弹性分布式数据集(Resilient Distributed Dataset,RDD) 弹性分布式数据集(RDD,从Spark 1.3版本开始已被DataFrame替代)是Apache Spark的核心理念。它是由数据组成的不可变分布式集合,其主要进行两个操作:transformation和action。Tr w397090770 9年前 (2015-07-13) 7650℃ 0评论8喜欢




![Hadoop等大数据学习相关电子书[共85本]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/8.jpg)