本文作者:汪愈舟 俞育才 郭晨钊 程浩(英特尔),李元健(百度)Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇到不少易用性和可扩展性的挑战。为了应对这些挑战,英特尔大数据技术团 w397090770 6年前 (2018-01-11) 90817℃ 0评论75喜欢
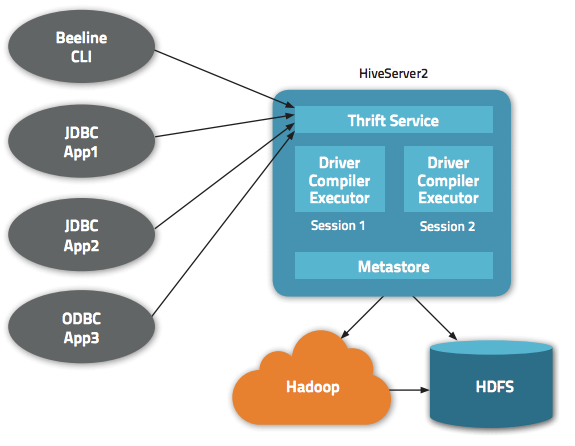
Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可 w397090770 6年前 (2018-01-11) 13073℃ 5评论18喜欢
Apache Spark 2.2.0 于今年7月份正式发布,这个版本是 Structured Streaming 的一个重要里程碑,因为其可以正式在生产环境中使用,实验标签(experimental tag)已经被移除; CBO (Cost-Based Optimizer)有了进一步的优化;SQL完全支持 SQL-2003 标准;R 中引入了新的分布式机器学习算法;MLlib 和 GraphX 中添加了新的算法更多详情请参见:Apa w397090770 6年前 (2017-12-13) 2640℃ 0评论19喜欢
第十四次Shanghai Apache Spark Meetup聚会,由中国平安银行大力支持。活动将于2017年12月23日12:30~17:00在上海浦东新区上海海神诺富特酒店三楼麦哲伦厅举行。举办地点交通方便,靠近地铁4号线浦东大道站。座位有限,先到先得。大会主题《Spark在金融领域的算法实践》(13:20 – 14:05)演讲嘉宾:潘鹏举,平安银行大数据平台架构师 zz~~ 6年前 (2017-12-06) 1949℃ 0评论11喜欢
在 《如何在Spark、MapReduce和Flink程序里面指定JAVA_HOME》文章中我简单地介绍了如何自己指定 JAVA_HOME 。有些人可能注意到了,上面设置的方法有个前提就是要求集群的所有节点的同一路径下都安装部署好了 JDK,这样才没问题。但是在现实情况下,我们需要的 JDK 版本可能并没有在集群上安装,这个时候咋办?是不是就没办法呢?答案 w397090770 6年前 (2017-12-05) 2951℃ 0评论18喜欢
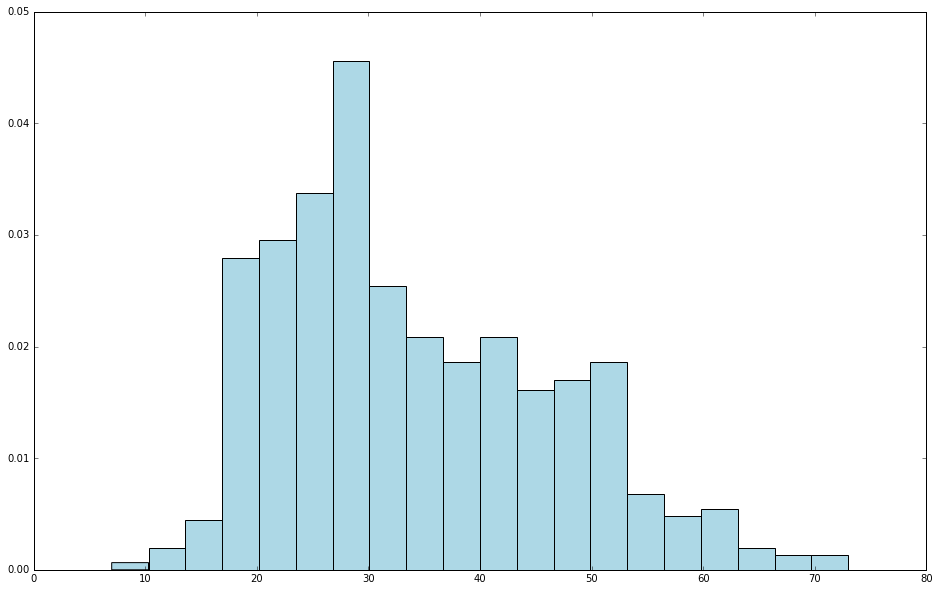
最近在使用 Python 学习 Spark,使用了 jupyter notebook,期间使用到 hist 来绘图,代码很简单如下:[code lang="python"]user_data = sc.textFile("/home/iteblog/ml-100k/u.user")user_fields = user_data.map(lambda line: line.split("|"))ages = user_fields.map(lambda x: int(x[1])).collect()hist(ages, bins=20, color='lightblue', normed=True)fig = matplotlib.pyplot.gcf()fig.set_size_inch w397090770 6年前 (2017-12-04) 4607℃ 0评论19喜欢
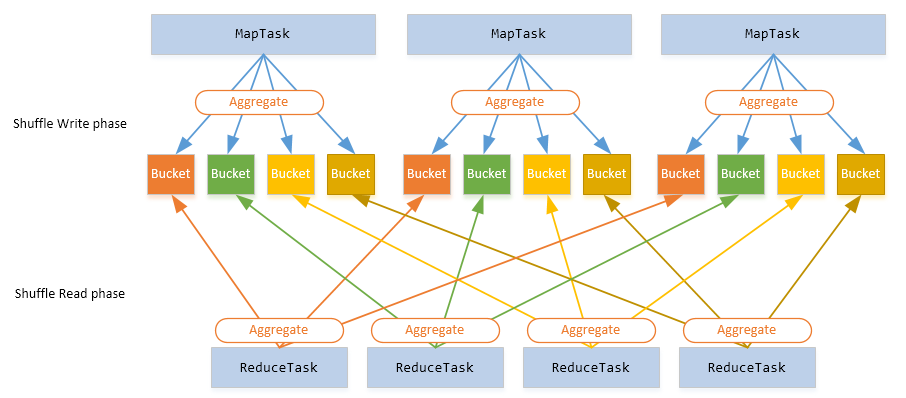
Spark Shuffle 基础在 MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Reduce 要读取到 Map 的输出必须要经过 Shuffle 这个环节;而 Reduce 和 Map 过程通常不在一台节点,这意味着 Shuffle 阶段通常需要跨网络以及一些磁盘的读写操作,因此 Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。与 MapReduce 计算框架一样,Spark 作 w397090770 7年前 (2017-11-15) 7318℃ 3评论30喜欢
在使用 Apache Spark 的时候,作业会以分布式的方式在不同的节点上运行;特别是当集群的规模很大时,集群的节点出现各种问题是很常见的,比如某个磁盘出现问题等。我们都知道 Apache Spark 是一个高性能、容错的分布式计算框架,一旦它知道某个计算所在的机器出现问题(比如磁盘故障),它会依据之前生成的 lineage 重新调度这个 w397090770 7年前 (2017-11-13) 10338℃ 0评论24喜欢
Spark Summit 2017 Europe 于2017-10-24 至 26在柏林进行,本次会议议题超过了70多个,会议的全部日程请参见:https://spark-summit.org/eu-2017/schedule/。本次议题主要包括:开发、研究、机器学习、流计算等领域。从这次会议可以看出,当前 Spark 发展两大方向:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spar w397090770 7年前 (2017-11-02) 3514℃ 0评论13喜欢
MMLSpark为Apache Spark提供了大量深度学习和数据科学工具,包括将Spark Machine Learning管道与Microsoft Cognitive Toolkit(CNTK)和OpenCV进行无缝集成,使您能够快速创建功能强大,高度可扩展的大型图像和文本数据集分析预测模型。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopMMLSpark需要Scala 2.11,Spark 2 w397090770 7年前 (2017-10-24) 4052℃ 0评论9喜欢




![Spark Summit 2017 Europe全部PPT及视频下载[共69个]](https://www.iteblog.com/pic/spark/spark-summit-2017-europe-iteblog.png)
