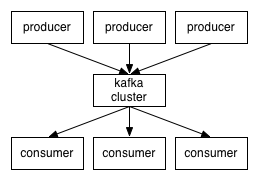
本文主要讲解 Kafka 是什么、Kafka 的架构包括工作流程和存储机制,以及生产者和消费者,最终大家会掌握 Kafka 中最重要的概念,分别是 broker、producer、consumer、consumer group、topic、partition、replica、leader、follower,这是学会和理解 Kafka 的基础和必备内容。1. 定义Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主 w397090770 4年前 (2020-03-14) 1578℃ 0评论10喜欢
2019年12月18日 Apache Kafka 2.4 正式发布了,这个版本有很多新功能,本文将介绍这个版本比较重要的功能,完整的更新可以参见 release notes如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopKafka broker, producer, 以及 consumer 新功能KIP-392: 允许消费者从最近的副本获取数据在 Kafka 2.4 版本之前,消费者 w397090770 4年前 (2019-12-25) 1449℃ 0评论3喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12323℃ 0评论31喜欢
最近很多粉丝后台留言问了一些大数据的面试题,其中包括了大量的 Kafka、Spark等相关的问题,所以我特意抽出一些时间整理了一些场景的大数据相关面试题,本文是 Kafka 面试相关问题,其他系列面试题后面会陆续整理,欢迎关注过往记忆大数据公众号。当然,由于个人知识面的限制,还有很多面试题相关的东西本文没有收集整理 w397090770 5年前 (2019-09-14) 16793℃ 3评论37喜欢
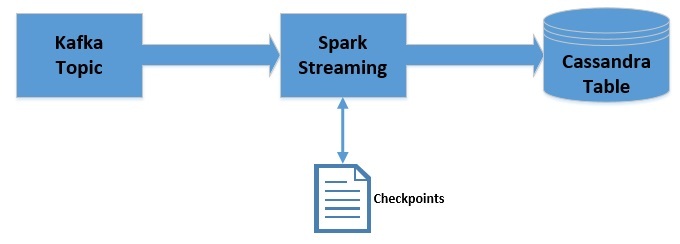
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 5年前 (2019-09-08) 3964℃ 0评论8喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 5年前 (2019-08-13) 5582℃ 2评论32喜欢
Apache Kafka 近期发布了 2.3.0 版本,主要的新特性如下:Kafka Connect REST API 已经有了一些改进。Kafka Connect 现在支持增量协同重新均衡(incremental cooperative rebalancing)Kafka Streams 现在支持内存会话存储和窗口存储;AdminClient 现在允许用户确定他们有权对主题执行哪些操作;broker 增加了一个新的启动时间指标;JMXTool现在可以连接到安 w397090770 5年前 (2019-06-27) 2977℃ 0评论6喜欢
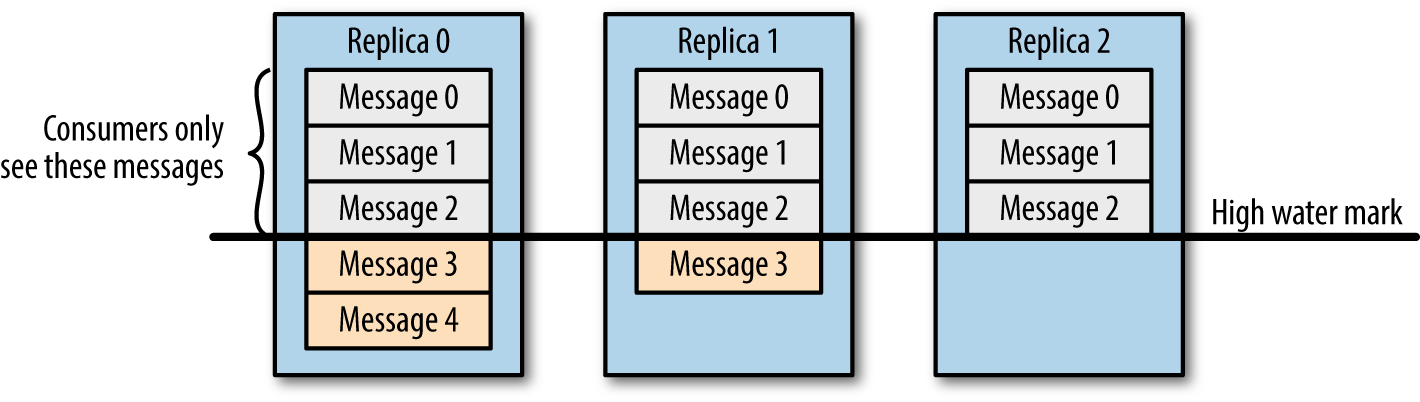
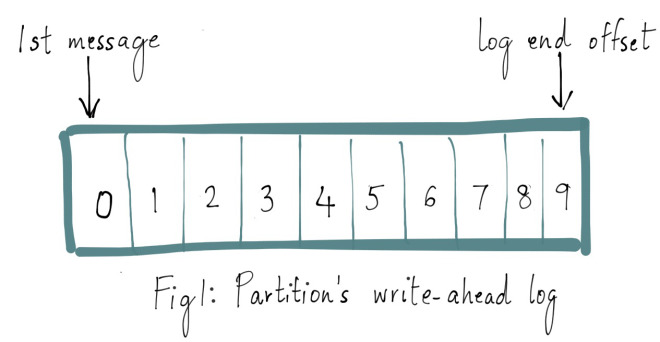
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 w397090770 5年前 (2019-06-11) 12635℃ 2评论42喜欢
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集 w397090770 5年前 (2019-05-26) 4985℃ 1评论14喜欢
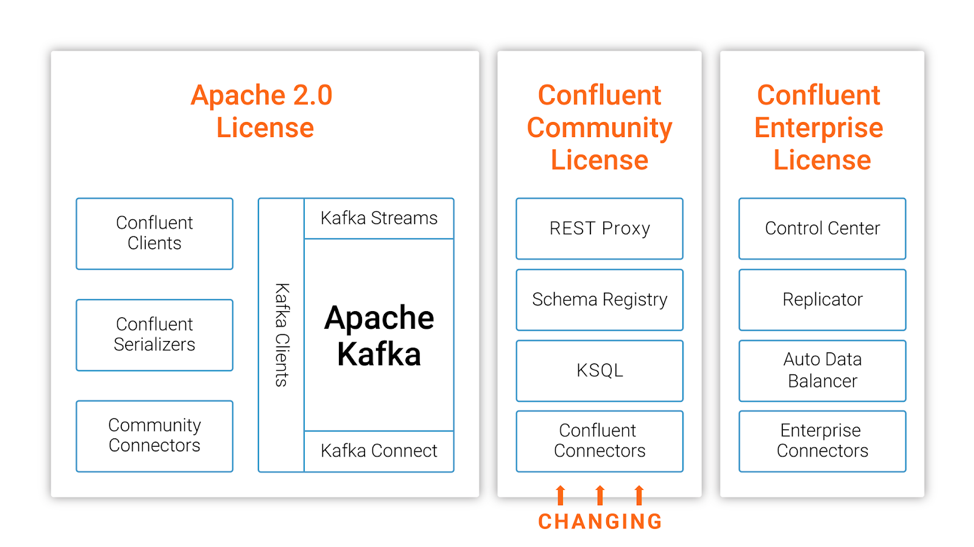
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache 2.0 切换到 Confluent Community License,参见这里,下面是这篇文章的全部翻译。我们正在将 w397090770 5年前 (2018-12-15) 1966℃ 0评论3喜欢