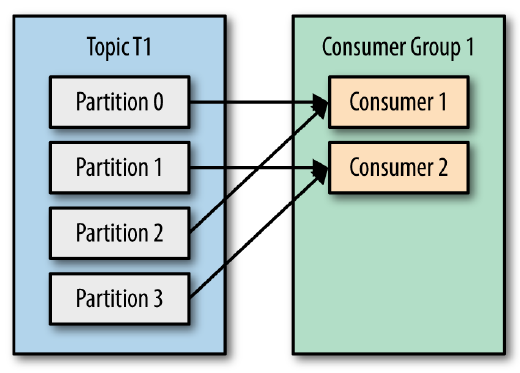
问题用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions。为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会启动一个或多个streams去分别消费 Topic 对应分区中的数据。我们又知道,Kafka 存在 Consumer Group 的概念,也就是 group.id 一样的 Consumer,这些 Consumer 属于同一个Consumer Group w397090770 7年前 (2017-07-22) 17557℃ 3评论27喜欢
本文涉及到的环境:操作系统:Windows 7Idea 版本:IntelliJ IDEA 2016.3.4 Build #IU-163.12024.16, built on January 31, 2017Kafka 版本:Kafka 0.8.2.0Gradle 版本:gradle-4.0.1JDK 版本:jdk1.7.0Scala 版本:2.10.4首先到http://archive.apache.org/dist/kafka/里面下载你需要的Kafka源码,本文选自的是kafka-0.8.2.0。因为Kafka代码自0.8.x之后就使用 Gradle 来进行编译 w397090770 7年前 (2017-07-21) 6118℃ 0评论16喜欢
Apache Kafka 0.10.2.0正式发布,此版本供修复超过200个bugs,合并超过500个 PR。本版本添加了一下的新功能: 1、支持session windows,参见KAFKA-3452 2、提供ProcessorContext中低层次Metrics的访问,参见KAFKA-3537 3、不用配置文件的情况下支持为 Kafka clients JAAS配置,参见KAFKA-4259 4、为Kafka Streams提供全局Table支持,参见KAFKA-4490 w397090770 7年前 (2017-02-23) 2454℃ 0评论1喜欢
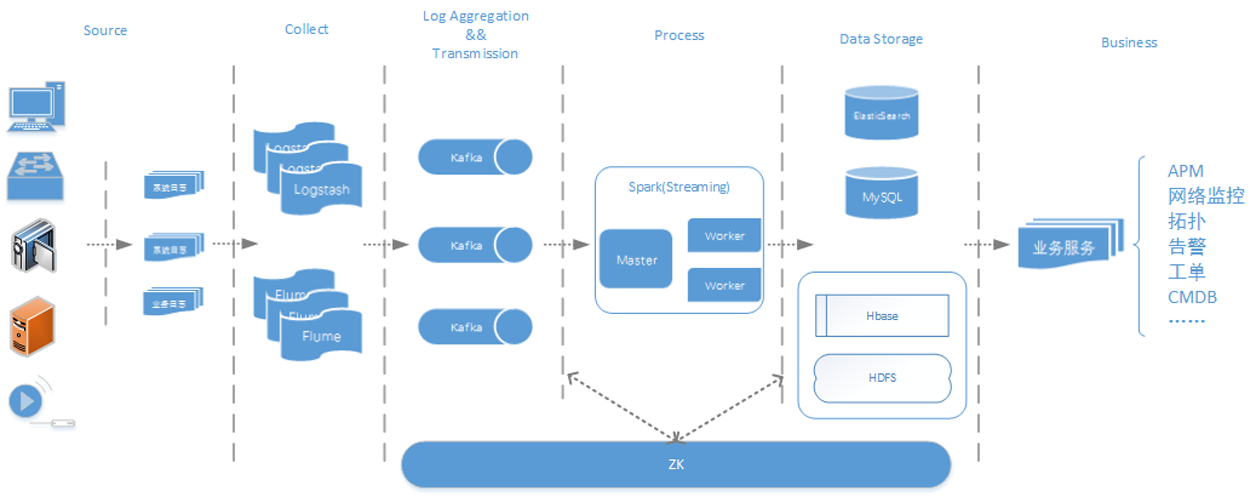
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分析的方式已不能满足实际要求,由于公安内部运维管 w397090770 7年前 (2017-01-01) 11161℃ 1评论37喜欢
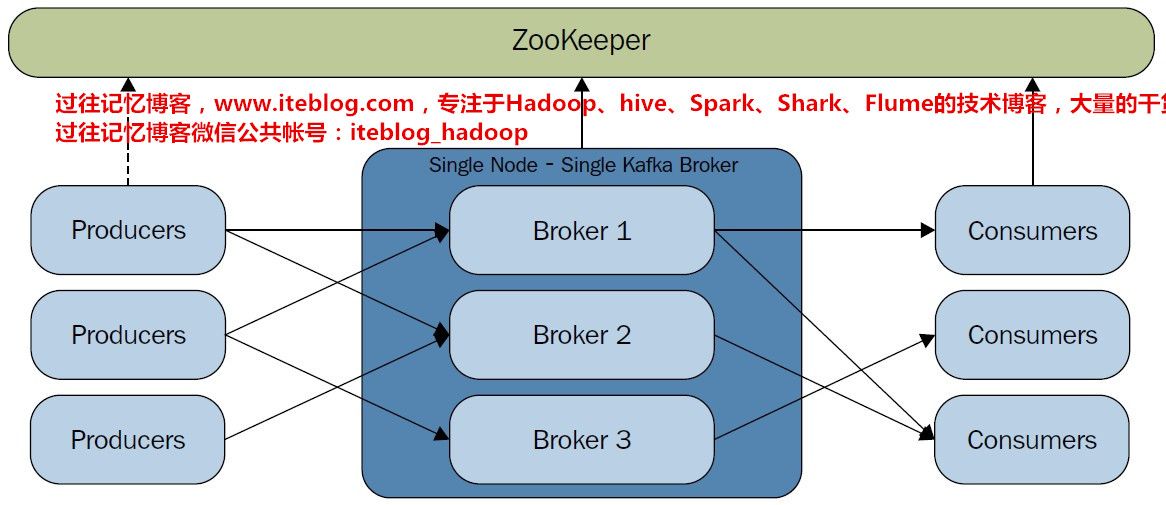
Kafka Cluster模式最大的优点:可扩展性和容错性,下图是关于Kafka集群的结构图:Kafka Broker个数决定因素 磁盘容量:首先考虑的是所需保存的消息所占用的总磁盘容量和每个broker所能提供的磁盘空间。如果Kafka集群需要保留 10 TB数据,单个broker能存储 2 TB,那么我们需要的最小Kafka集群大小 5 个broker。此外,如果启用副 w397090770 8年前 (2016-11-18) 13542℃ 0评论28喜欢
流式处理是大数据应用中的非常重要的一环,在Spark中Spark Streaming利用Spark的高效框架提供了基于micro-batch的流式处理框架,并在RDD之上抽象了流式操作API DStream供用户使用。 随着流式处理需求的复杂化,用户希望在流式数据中引入较为复杂的查询和分析,传统的DStream API想要实现相应的功能就变得较为复杂,同时随着Spark w397090770 8年前 (2016-11-16) 6085℃ 0评论13喜欢
在某些情况下,我们可能会在Spring中将一些WEB上的信息发送到Kafka中,这时候我们就需要在Spring中编写Producer相关的代码了;不过高兴的是,Spring本身提供了操作Kafka的相关类库,我们可以直接通过xml文件配置然后直接在后端的代码中使用Kafka,非常地方便。本文将介绍如果在Spring中将消息发送到Kafka。在这之前,请将下面的依赖 w397090770 8年前 (2016-11-01) 6202℃ 0评论11喜欢
这是许多kafka使用者经常会问到的一个问题。本文的目的是介绍与本问题相关的一些重要决策因素,并提供一些简单的计算公式。越多的分区可以提供更高的吞吐量 首先我们需要明白以下事实:在kafka中,单个patition是kafka并行操作的最小单元。在producer和broker端,向每一个分区写入数据是可以完全并行化的,此时,可 w397090770 8年前 (2016-09-08) 10088℃ 2评论22喜欢
Streaming job 的调度与执行 我们先来看看如下 job 调度执行流程图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop为什么很难保证 exactly once 上面这张流程图最主要想说明的就是,job 的提交执行是异步的,与 checkpoint 操作并不是原子操作。这样的机制会引起数据重复消费问题: zz~~ 8年前 (2016-09-08) 8745℃ 5评论12喜欢
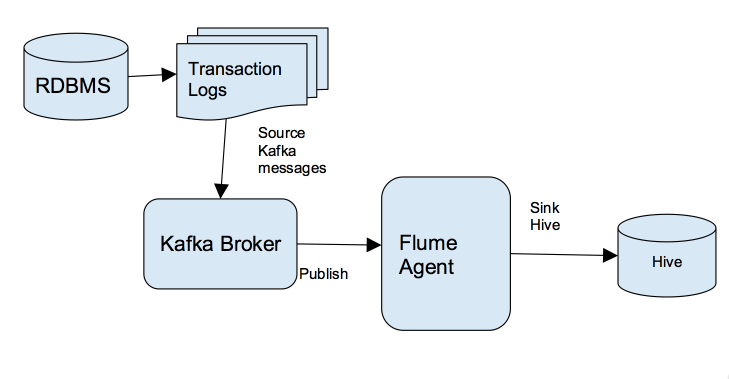
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 8年前 (2016-08-30) 11350℃ 6评论24喜欢