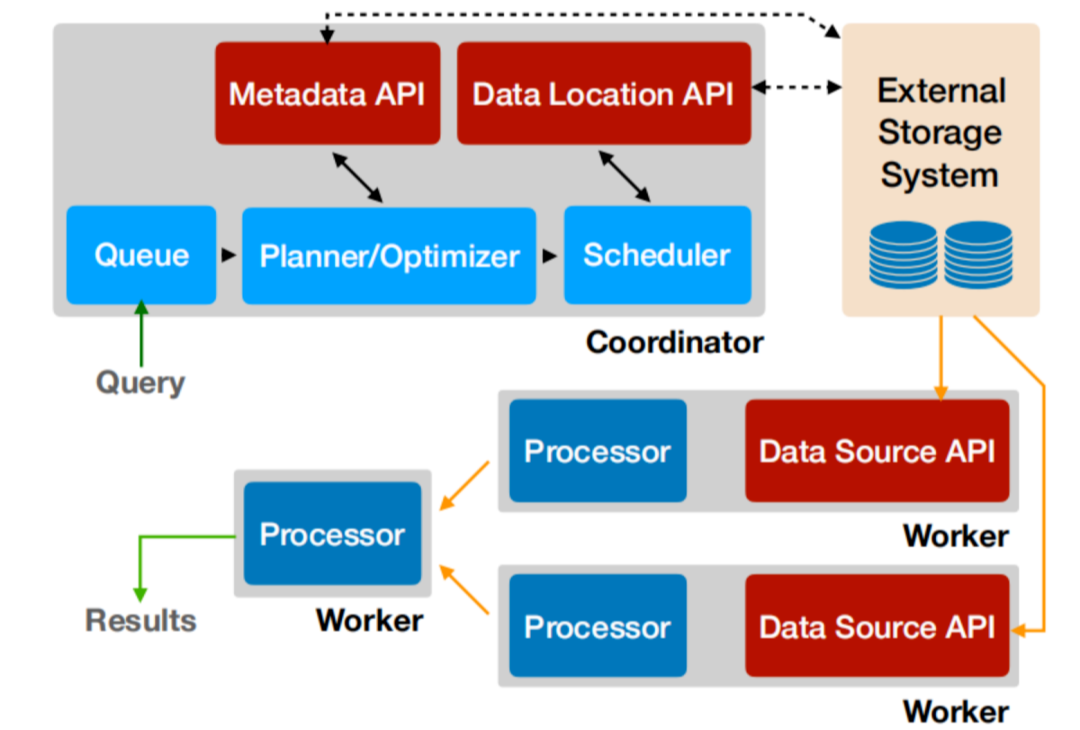
Presto在滴滴内部发展三年,已经成为滴滴内部Ad-Hoc和Hive SQL加速的首选引擎。目前服务6K+用户,每天读取2PB ~ 3PB HDFS数据,处理30万亿~35万亿条记录,为了承接业务及丰富使用场景,滴滴Presto需要解决稳定性、易用性、性能、成本等诸多问题。我们在3年多的时间里,做了大量优化和二次开发,积攒了非常丰富的经验。本文分享了滴滴 w397090770 4年前 (2020-10-21) 1239℃ 0评论4喜欢
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值。本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾讯云EMR产品深度合作的案例解读,还原一个不一样的大数据云端解决方案。一、背景介绍QQ音乐是腾讯音乐旗下一款领先的音乐流媒体产品,平台打造了“听 w397090770 4年前 (2020-10-21) 1115℃ 0评论0喜欢
本文作者:王祥虎,原文链接:https://mp.weixin.qq.com/s/LvKaj5ytk6imEU5Dc1Sr5Q,欢迎关注 Apache Hudi 技术社区公众号:ApacheHudi。Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢 w397090770 4年前 (2020-10-09) 1796℃ 0评论2喜欢
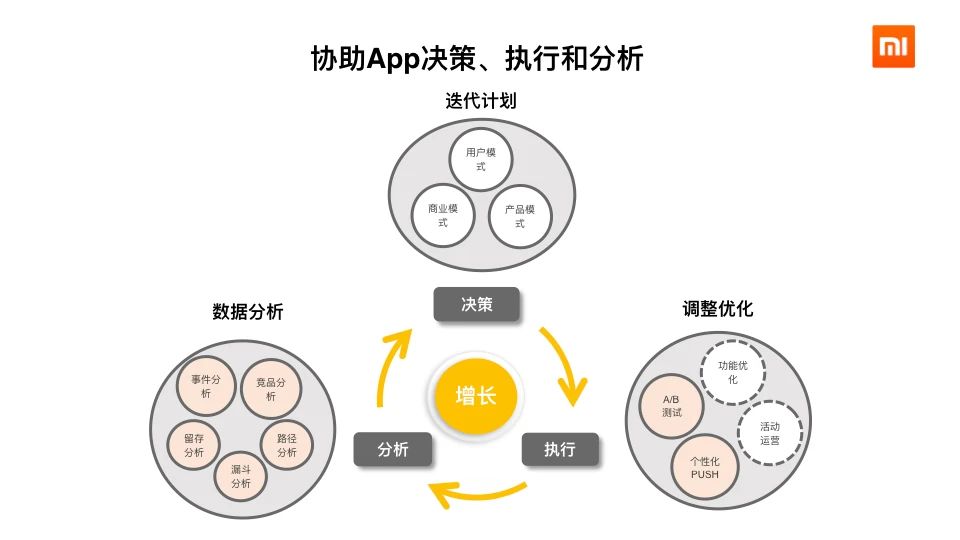
1、背景随着小米互联网业务的发展,各个产品线利用用户行为数据对业务进行增长分析的需求越来越迫切。显然,让每个业务产品线都自己搭建一套增长分析系统,不仅成本高昂,也会导致效率低下。我们希望能有一款产品能够帮助他们屏蔽底层复杂的技术细节,让相关业务人员能够专注于自己的技术领域,从而提高工作效率。 w397090770 4年前 (2020-09-13) 1199℃ 0评论1喜欢
在实践经验中,我们知道数据总是在不断演变和增长,我们对于这个世界的心智模型必须要适应新的数据,甚至要应对我们从前未知的知识维度。表的 schema 其实和这种心智模型并没什么不同,需要定义如何对新的信息进行分类和处理。这就涉及到 schema 管理的问题,随着业务问题和需求的不断演进,数据结构也会不断发生变化。 w397090770 4年前 (2020-09-12) 544℃ 0评论0喜欢
在 Apache Pulsar 2.6.0 版本发布后的 2 个月,2020 年 8 月 21 日,Apache Pulsar 2.6.1 版本正式发布!如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Pulsar 2.6.1 修复了 2.6.0 版本中的诸多问题,改进了一些功能,新增了对 OAuth2 的支持,覆盖 Broker、Pulsar SQL、Pulsar Functions、Go Function、Java Client 和 C++ w397090770 4年前 (2020-09-02) 485℃ 0评论1喜欢
本文英文原文:https://hudi.apache.org/releases.html下载信息源码:Apache Hudi 0.6.0 Source Release (asc, sha512)二进制Jar包:nexus如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop2. 迁移指南如果您从0.5.3以前的版本迁移至0.6.0,请仔细核对每个版本的迁移指南;0.6.0版本从基于list的rollback策略变更为 w397090770 4年前 (2020-09-02) 849℃ 0评论0喜欢
桔妹导读:滴滴ElasticSearch平台承接了公司内部所有使用ElasticSearch的业务,包括核心搜索、RDS从库、日志检索、安全数据分析、指标数据分析等等。平台规模达到了3000+节点,5PB 的数据存储,超过万亿条数据。平台写入的峰值写入TPS达到了2000w/s,每天近 10 亿次检索查询。为了承接这么大的体量和丰富的使用场景,滴滴ElasticSearch需要 w397090770 4年前 (2020-08-19) 1327℃ 0评论6喜欢
Spark SQL小文件是指文件大小显著小于hdfs block块大小的的文件。过于繁多的小文件会给HDFS带来很严重的性能瓶颈,对任务的稳定和集群的维护会带来极大的挑战。一般来说,通过Hive调度的MR任务都可以简单设置如下几个小文件合并的参数来解决任务产生的小文件问题:[code lang="sql"]set hive.merge.mapfiles=true;set hive.merge.mapredfiles=true w397090770 4年前 (2020-07-03) 2265℃ 0评论3喜欢
导言本文主要介绍如何快速的通过Spark访问 Iceberg table。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。版本对比 w397090770 4年前 (2020-06-10) 9714℃ 0评论4喜欢