摘要:本文整理自 58 同城实时计算平台负责人冯海涛在 Flink Forward Asia 2020 分享的议题《Flink 在 58 同城应用与实践》,内容包括: 实时计算平台架实时 SQL 建设Storm 迁移 Flink 实践一站式实时计算平台后续规划如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据实时计算平台架构 w397090770 3年前 (2021-08-17) 224℃ 0评论0喜欢
本次的分享内容分成四个部分:系统概述:认识kudu,理解Kudu的系统设计与定位生产实践:分享网易内部的典型使用场景遇到的问题:实际使用过程中遇到的问题和问题的排障过程功能展望:对Kudu功能特性的展望Kudu定位与架构Kudu是一个存储引擎,可以接入Impala、Presto、Spark等Olap计算引擎进行数据分析,容易融入Hadoop社区 w397090770 3年前 (2021-07-17) 214℃ 0评论1喜欢
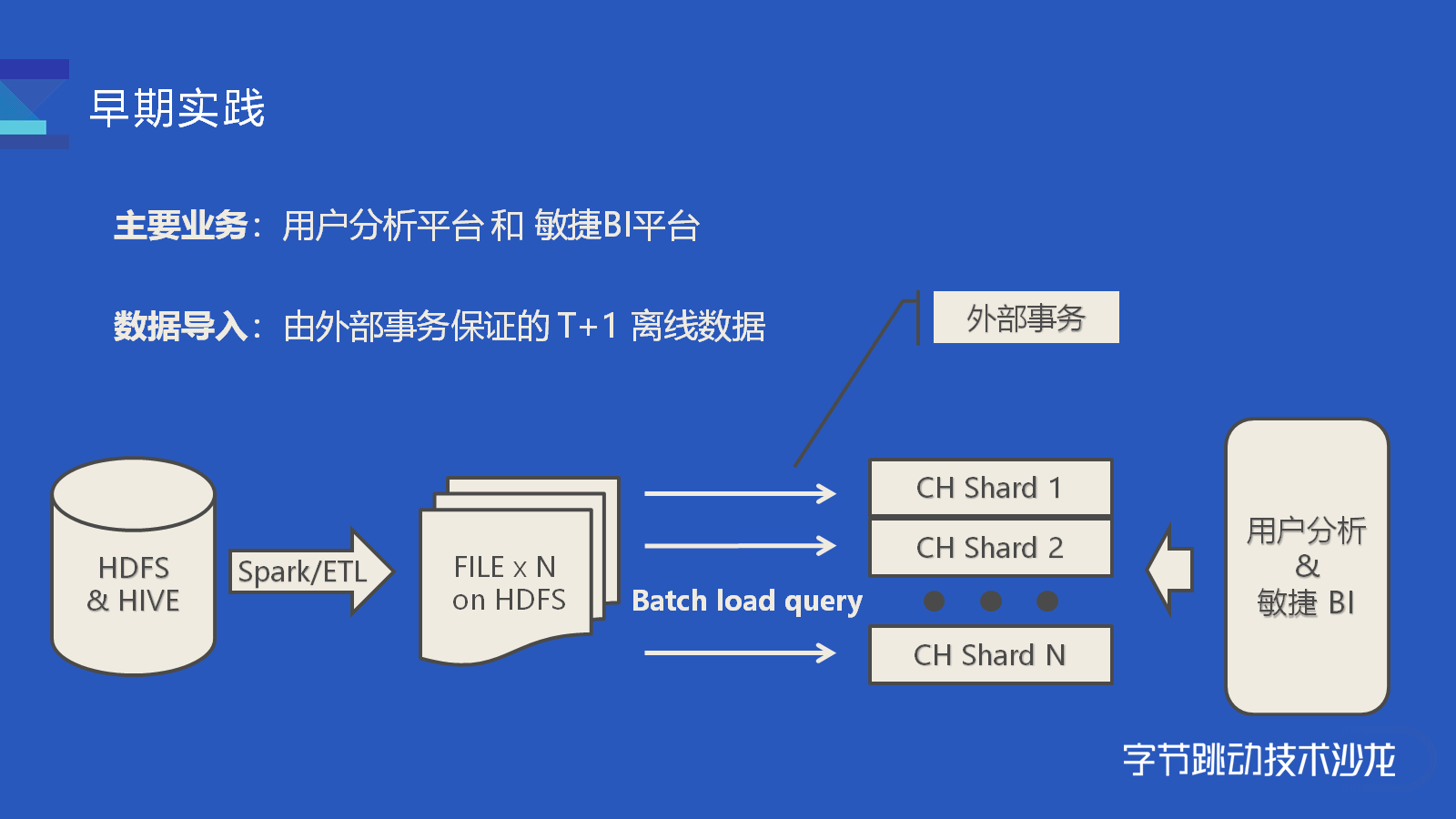
讲师:郭映中 字节跳动 ClickHouse 研发工程师此次分享分为三部分内容,第一部分通过讲解推荐和广告业务的两个典型案例,穿插介绍字节内部相应的改进。第二部分会介绍典型案例中未覆盖到的改进和经验。第三部分会提出目前的不足和未来的改进计划。早期实践如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注 w397090770 3年前 (2021-03-05) 4610℃ 0评论5喜欢
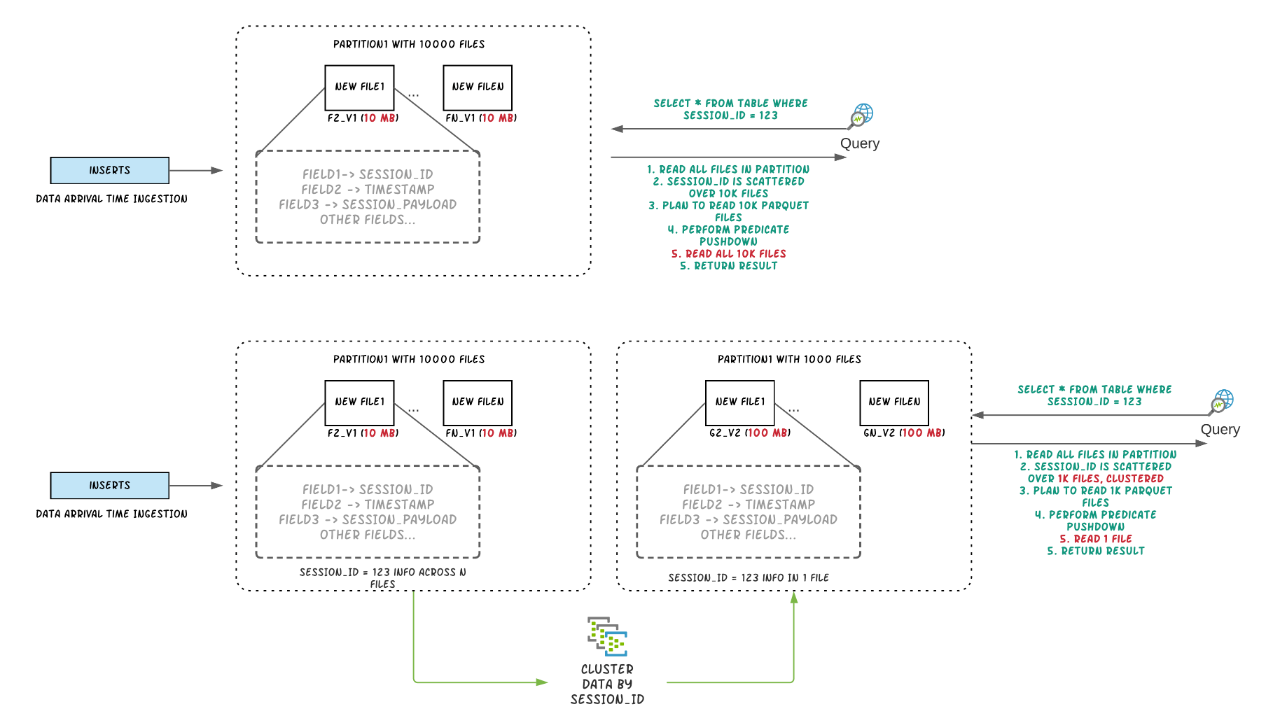
背景Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据。在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查询性能下降。在摄取过程中通常会根据时间在同一位置放置数据,但如果把查询频 w397090770 3年前 (2021-02-24) 1408℃ 0评论4喜欢
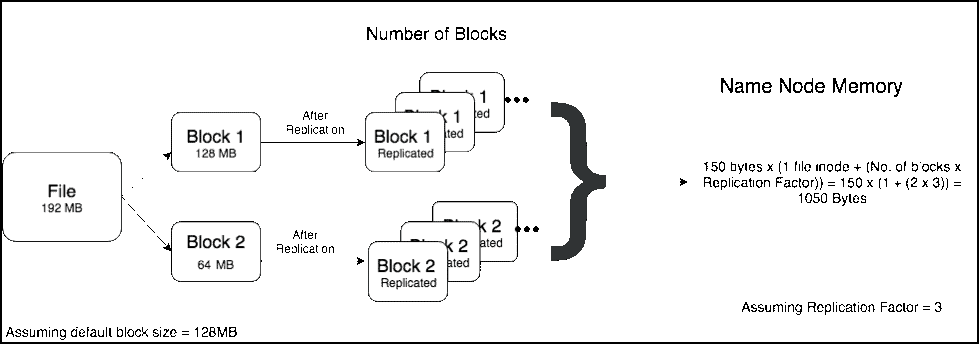
在使用Hadoop过程中,小文件是一种比较常见的挑战,如果不小心处理,可能会带来一系列的问题。HDFS是为了存储和处理大数据集(M以上)而开发的,大量小文件会导致Namenode内存利用率和RPC调用效率低下,block扫描吞吐量下降,应用层性能降低。通过本文,我们将定义小文件存储的问题,并探讨如何对小文件进行治理。什么是小 w397090770 3年前 (2021-02-24) 968℃ 0评论4喜欢
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展 w397090770 3年前 (2021-01-28) 2312℃ 0评论10喜欢
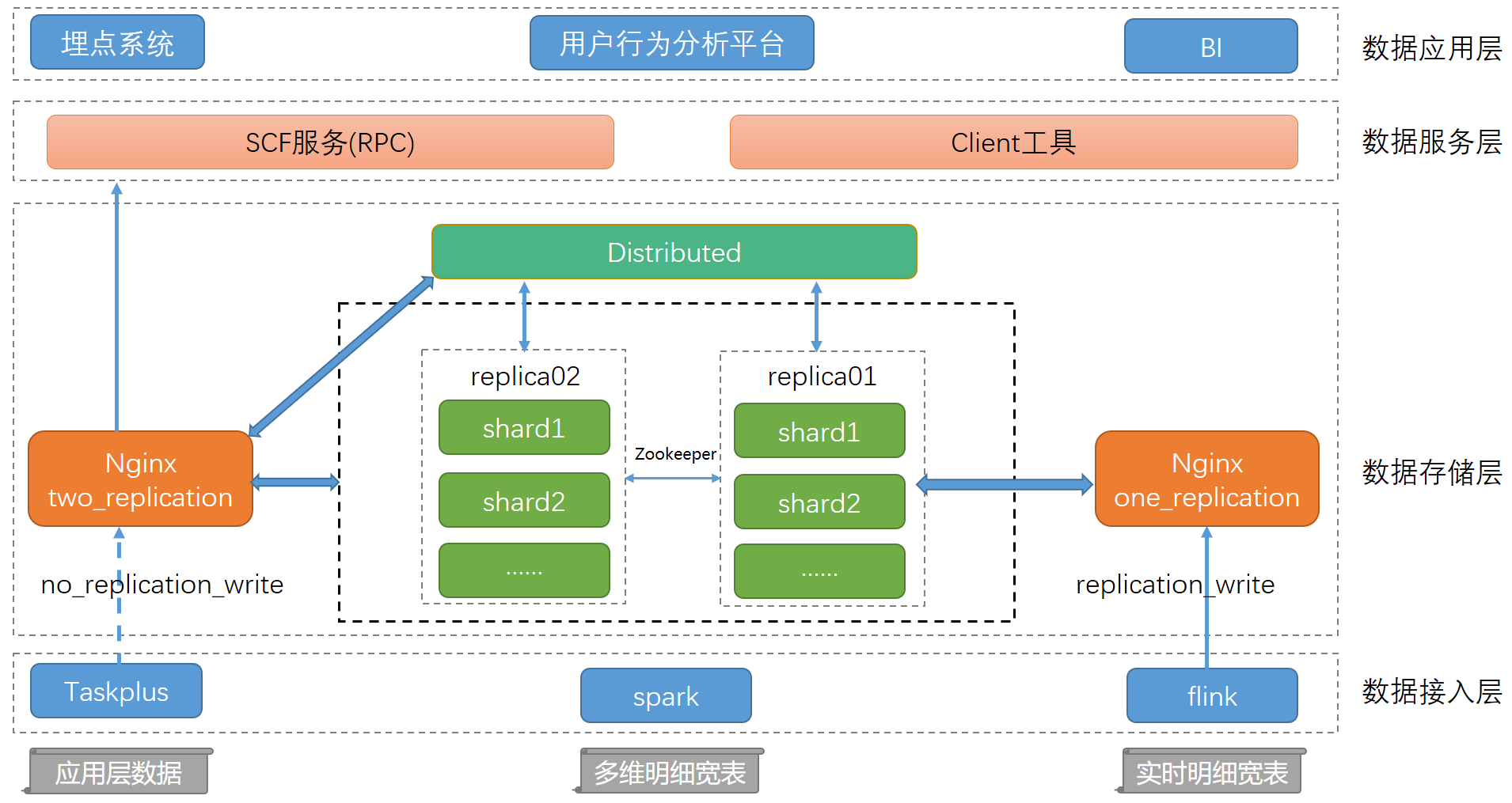
在数据量日益增长的当下,传统数据库的查询性能已满足不了我们的业务需求。而Clickhouse在OLAP领域的快速崛起引起了我们的注意,于是我们引入Clickhouse并不断优化系统性能,提供高可用集群环境。本文主要讲述如何通过Clickhouse结合大数据生态来定制一套完善的数据分析方案、如何打造完备的运维管理平台以降低维护成本,并结合具 w397090770 3年前 (2021-01-22) 1674℃ 0评论2喜欢
前言本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增,从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引 w397090770 3年前 (2020-12-25) 1259℃ 0评论4喜欢
本文根据贝壳找房资深工程师仰宗强老师在2020年"面向AI技术的工程架构实践"大会上的演讲速记整理而成。1 开场大家下午好,很荣幸来到这跟大家一起分享贝壳一站式大数据开发平台的落地实践。今天的分享主要分为以下四个部分:贝壳的数据业务背景。数据开发平台探索历程。数据开发平台的整体情况介绍未来规划与 w397090770 3年前 (2020-11-25) 1617℃ 0评论5喜欢
HDFS集群随着使用时间的增长,难免会出现一些“性能退化”的节点,主要表现为磁盘读写变慢、网络传输变慢,我们统称这些节点为慢节点。当集群扩大到一定规模,比如上千个节点的集群,慢节点通常是不容易被发现的。大多数时候,慢节点都藏匿于众多健康节点中,只有在客户端频繁访问这些有问题的节点,发现读写变慢了, w397090770 4年前 (2020-11-12) 1324℃ 0评论7喜欢