本文根据贝壳找房资深工程师仰宗强老师在2020年"面向AI技术的工程架构实践"大会上的演讲速记整理而成。1 开场大家下午好,很荣幸来到这跟大家一起分享贝壳一站式大数据开发平台的落地实践。今天的分享主要分为以下四个部分:贝壳的数据业务背景。数据开发平台探索历程。数据开发平台的整体情况介绍未来规划与 w397090770 5年前 (2020-11-25) 1769℃ 0评论5喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 5年前 (2020-11-24) 1206℃ 0评论4喜欢
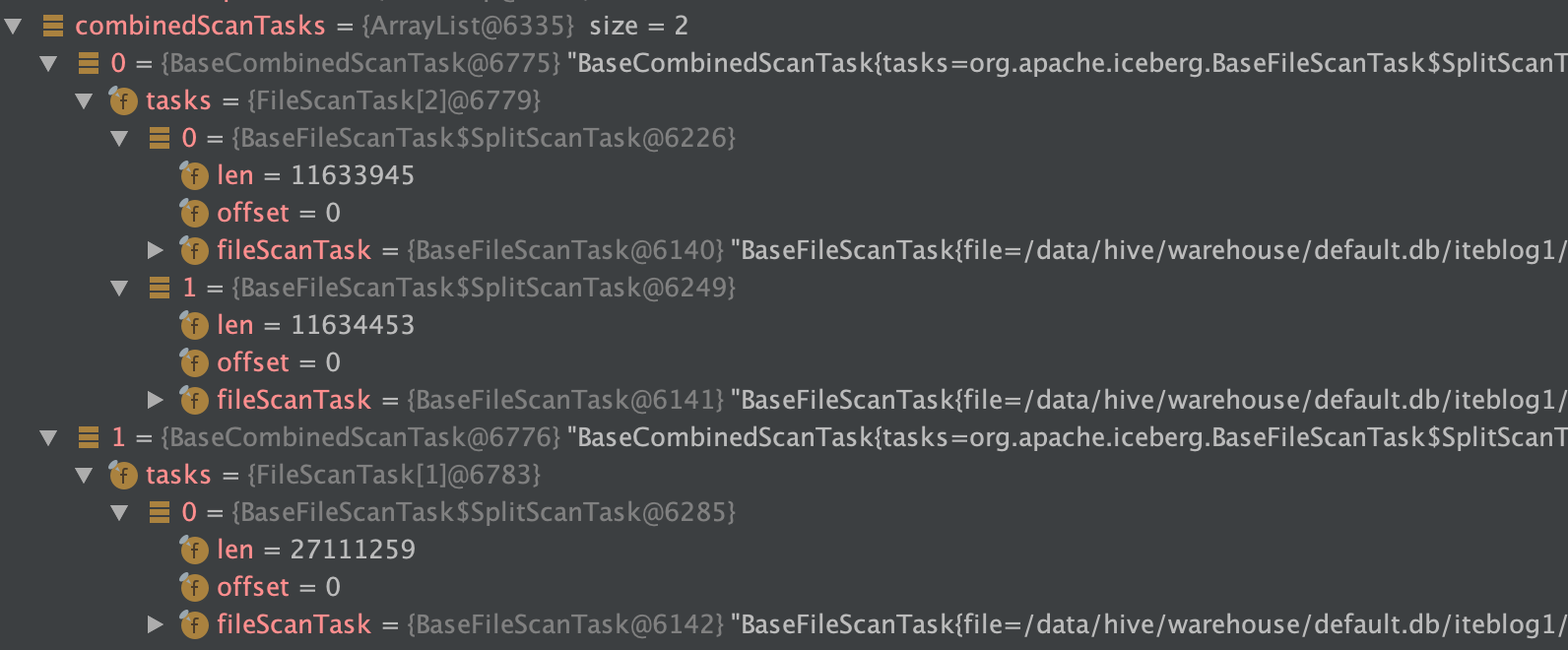
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):[code lang="bash"]/data/hive/warehouse/default.db/iteblog├── data│ └── ts_year=2020│ ├── id_bucket=0│ │ ├── 00000-0-19603f5a-d38a w397090770 5年前 (2020-11-20) 7090℃ 6评论8喜欢
本文基于 Apache Iceberg 0.9.0 最新分支,主要分析 Apache Iceberg 中使用 Spark 2.4.6 来写数据到 Iceberg 表中,也就是对应 iceberg-spark2 模块。当然,Apache Iceberg 也支持 Flink 来读写 Iceberg 表,其底层逻辑也 Spark 类似,感兴趣的同学可以去看看。使用 Spark2 将数据写到 Apache Iceberg在介绍下面文章之前,我们先来看下在 Apache Spark 2.4.6 中写数 w397090770 5年前 (2020-11-12) 6220℃ 0评论9喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在 这篇 文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:INNER JOINCROSS JOINLEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOINLEFT SEMI JOINLEFT ANTI JOIN在实现上 w397090770 5年前 (2020-10-25) 1759℃ 0评论6喜欢
本文资料来自2020年9月23日举办的 Apache Spark Bogotá 题为《Apache Spark 3.0: Overview of What’s New and Why Care》 的分享。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Spark 3.0 继续坚持更快、更简单、更智能的目标,这个版本解决了3000多个 JIRAs。在这次演讲中,主要和 Bogota Spark 社区分享 Spark 3.0 的 w397090770 5年前 (2020-10-24) 909℃ 0评论3喜欢
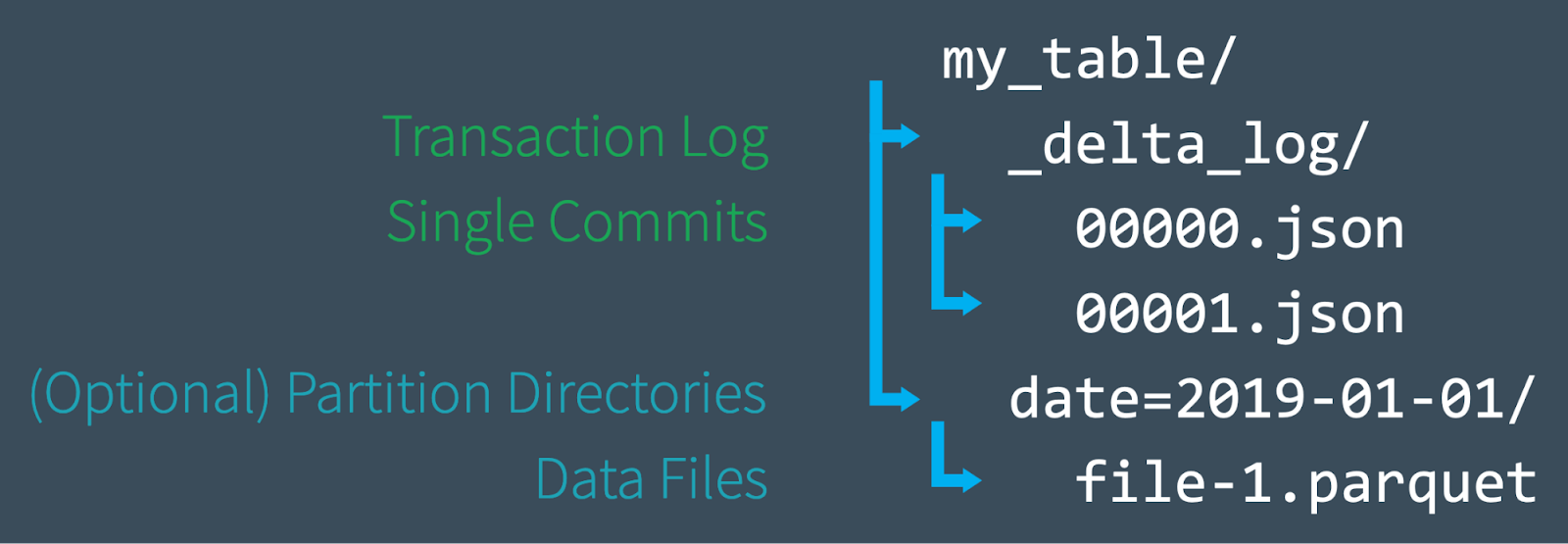
Delta Lake 支持 DML 命令,包括 DELETE, UPDATE, 以及 MERGE,这些命令简化了 CDC、审计、治理以及 GDPR/CCPA 工作流等业务场景。在这篇文章中,我们将演示如何使用这些 DML 命令,并会介绍这些命令的后背实现,同时也会介绍对应命令的一些性能调优技巧。Delta Lake: 基本原理如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 5年前 (2020-10-12) 1687℃ 0评论0喜欢
当前数据湖方向非常热门,市面上也出现了三款开源的数据湖产品:Delta Lake、Apache Hudi 以及 Apache Iceberg。这段时间抽了点时间看了下使用 Apache Spark 读写 Apache Iceberg 的代码。完全看代码肯定有些吃力,所以使用了代码调试功能。由于 Apache Iceberg 支持 Apache Spark 2.x 以及 3.x,并在创建了不同的模块。其相当于 Spark 的 Connect。Apache Spa w397090770 5年前 (2020-10-04) 2014℃ 0评论3喜欢
当前 Spark 计算引擎能够利用一些统计信息选择合适的 Join 策略(关于 Spark 支持的 Join 策略可以参见每个 Spark 工程师都应该知道的五种 Join 策略),但是由于各种原因,比如统计信息缺失、统计信息不准确等原因,Spark 给我们选择的 Join 策略不是正确的,这时候我们就可以人为“干涉”,Spark 从 2.2.0 版本开始(参见SPARK-16475),支 w397090770 5年前 (2020-09-15) 3660℃ 0评论3喜欢
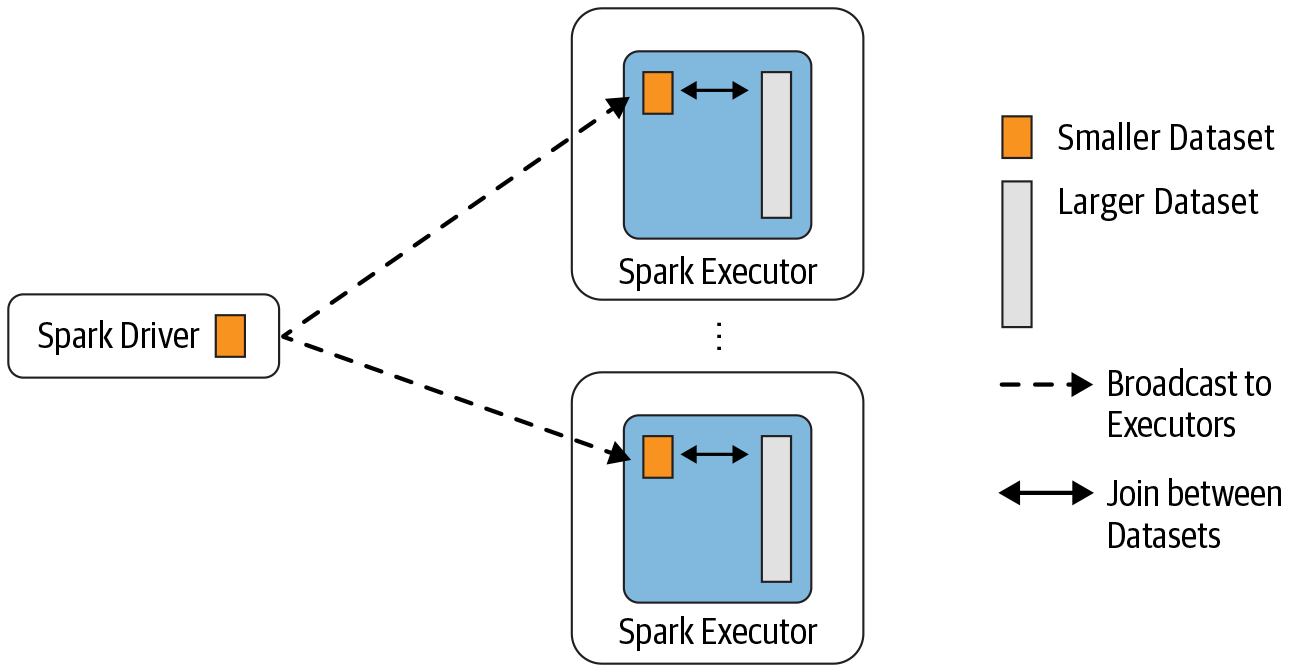
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join(equi-join) 还是不等值(non-equi-joins)以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略(join strategies),最后 Spark 会利用选择好的 Join 策略执行最 w397090770 5年前 (2020-09-13) 5322℃ 0评论13喜欢