在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 4年前 (2021-10-13) 922℃ 0评论3喜欢
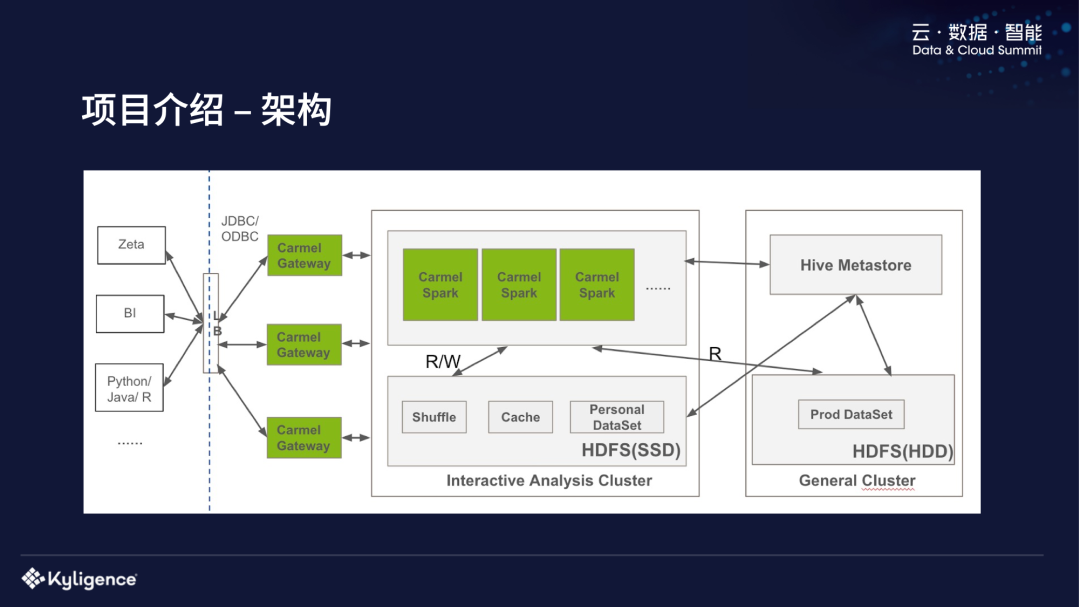
系统介绍我们这个系统的名字叫 Carmel,它是基于开源的 Hadoop 和 Spark 来替换传统的数据仓库,我们是 2019 年开始做我们这个项目的,当时是基于 Spark 2.3.1,最近刚刚升到 Spark 3.0。面临的主要技术挑战,第一个是功能方面的缺失,包括访问控制,还有一些 Update 和 Delete 的支持;在性能方面跟传统数仓,特别是交互式的分析查询中性 zz~~ 4年前 (2021-09-24) 716℃ 0评论2喜欢
在 LinkedIn,我们非常依赖离线数据分析来进行数据驱动的决策。多年来,Apache Spark 已经成为 LinkedIn 的主要计算引擎,以满足这些数据需求。凭借其独特的功能,Spark 为 LinkedIn 的许多关键业务提供支持,包括数据仓库、数据科学、AI/ML、A/B 测试和指标报告。需要大规模数据分析的用例数量也在快速增长。从 2017 年到现在,LinkedIn 的 S w397090770 4年前 (2021-09-08) 1147℃ 0评论4喜欢
Data + AI Summit 2021 于2021年05月24日至28日举行。本次会议是在线举办的,一共为期五天,第一、二天是培训,第三天到第五天是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta Lake、MLflow、Structured Streaming、BI和SQL分析、深度学习和机器学习 w397090770 4年前 (2021-06-20) 1716℃ 0评论3喜欢
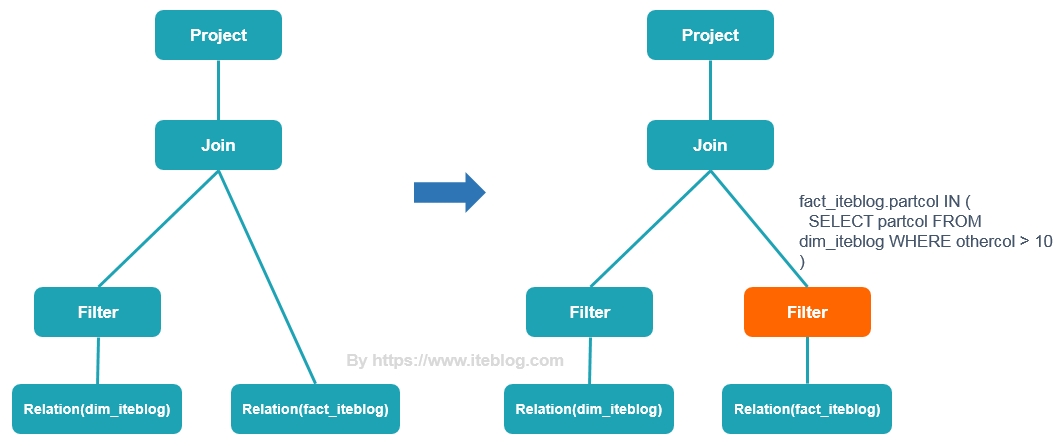
早在2005年,Oracle 数据库就支持比较丰富的 dynamic filtering 功能,而 Spark 和 Presto 在最近版本才开始支持这个功能。本文将介绍 Presto 动态过滤的原理以及具体使用。Apache Spark 的动态分区裁减Apache Spark 3.0 给我们带来了许多的新特性用于加速查询性能,其中一个就是动态分区裁减(Dynamic Partition Pruning,DPP),所谓的动态分区裁剪就 w397090770 4年前 (2021-06-01) 1583℃ 0评论2喜欢
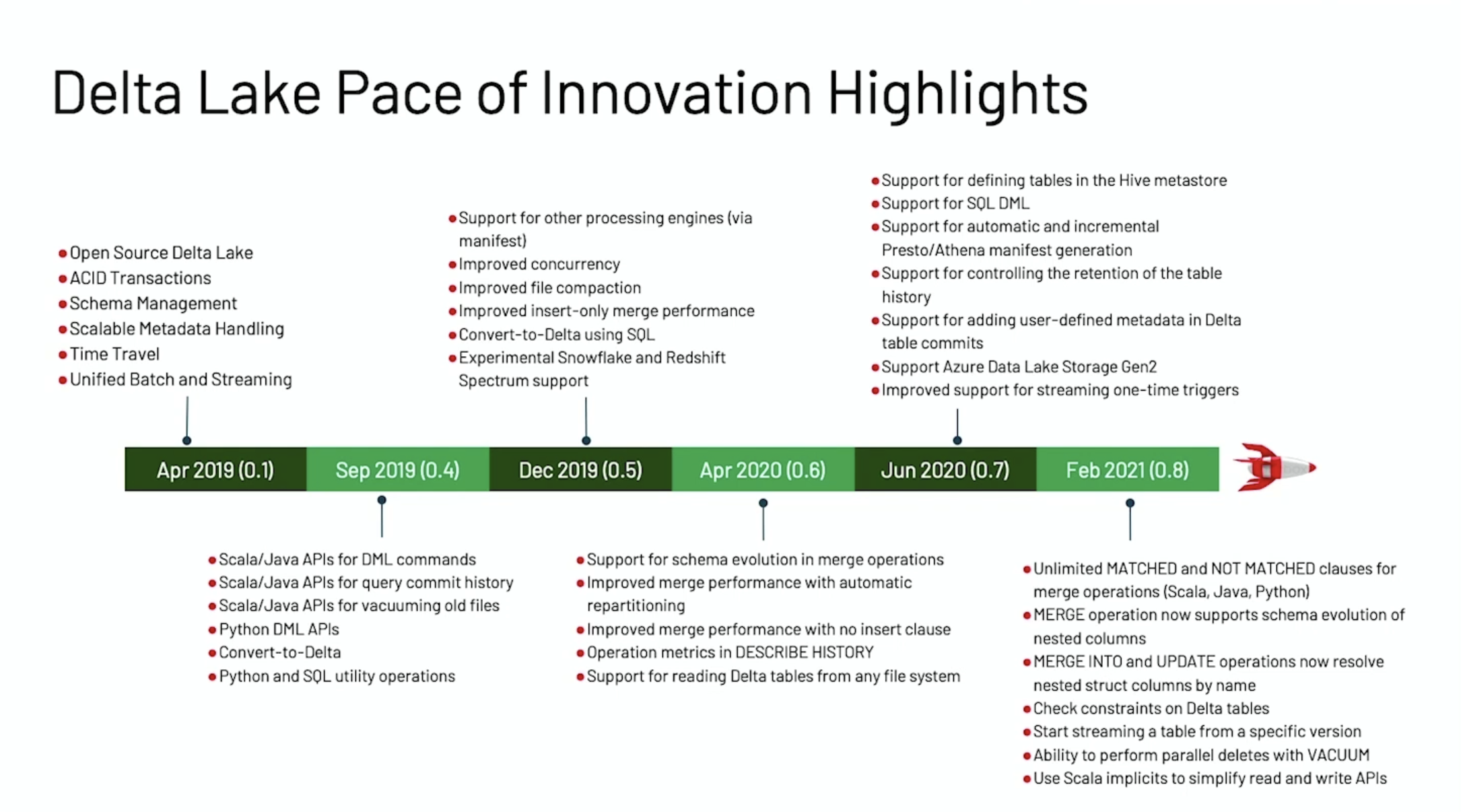
赶在 Data + AI Summit 2021 之前,Delta Lake 1.0.0 重磅发布,这个版本是基于 Spark 3.1 的,带来了许多新特性。本文将结合 Michael Armbrust 大牛在 Data + AI Summit 2021 的演讲《Announcing Delta Lake 1.0》来介绍 Delta Lake 1.0.0 版本的一些重要的新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Delta Lake 0.1 w397090770 4年前 (2021-05-27) 937℃ 0评论2喜欢
本书作者 Denny Lee, Tathagata Das, Vini Jaiswal,预计2022年4月出版,出版社 O'Reilly Media, Inc.,ISBN:9781098104528分析和机器学习模型的好坏取决于它们所依赖的数据。查询处理过的数据并从中获得见解需要一个健壮的数据管道——以及一个有效的存储解决方案,以确保数据质量、数据完整性和性能。本指南向您介绍 Delta Lake,这是一种开 w397090770 4年前 (2021-05-27) 608℃ 0评论2喜欢
本文是 Forest Rim Technology 数据团队撰写的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被称为是数据仓库之父,最早的数据仓库概念提出者,被《计算机世界》评为计算机行业历史上最具影响力的十大人物之一。原始数据的挑战随着大量应用程序的出现,产生了相同的数据在不同地方出现不同值的情况。为了做出决定,用户必须找 w397090770 4年前 (2021-05-25) 667℃ 0评论0喜欢
在几乎所有处理复杂数据的领域,Spark 已经迅速成为数据和分析生命周期团队的事实上的分布式计算框架。Spark 3.0 最受期待的特性之一是新的自适应查询执行框架(Adaptive Query Execution,AQE),该框架解决了许多 Spark SQL 工作负载遇到的问题。AQE 在2018年初由英特尔和百度组成的团队最早实现。AQE 最初是在 Spark 2.4 中引入的, Spark 3.0 做 w397090770 4年前 (2021-05-23) 1281℃ 0评论2喜欢
Apache Spark 3.1.x 版本发布到现在已经过了两个多月了,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming更多详情请参见这里。在这篇博文中,我们总结了3.1版本中 w397090770 4年前 (2021-05-16) 799℃ 0评论3喜欢