Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 4年前 (2022-01-01) 1404℃ 0评论4喜欢
今天给大家分享30款开源的可视化大屏(含源码)。下载到本地后,直接运行文件夹中的index.html,即可看到大屏。01 数据可视化页面设计有动画效果,显得高大上!主要图表:柱状图、水球图、折线图等。02 数据可视化演示系统不仅有动画效果,还有科技感光效。主要图表:柱状图、折线图、饼图、地图等 zz~~ 4年前 (2021-12-23) 4235℃ 0评论4喜欢
本文来自 Data + AI Summit 2021 会议中 Facebook 的Rongrong Zhong(Facebook Presto 团队的 TL) 和 Tejas Patil(Facebook Spark 团队的 TL) 工程师带来的名为 《Portable UDFs : Write Once, Run Anywhere》的分享。 虽然大多数查询引擎都提供了丰富的内置函数,但它并不能满足用户的所有需求。在这种情况下,用户定义函数(UDF)允许用户表达他们的业 w397090770 4年前 (2021-12-17) 569℃ 0评论2喜欢
本文来自 Kyligence 主办的 Data & AI Meetup(第二期),会议时间为 11月16日。本期会议特别邀请了 Spark 社区大佬范文臣带来 Spark 3.2.0 新特性的首发解读。范文臣,Databricks 开源组技术主管,Apache Spark PMC member,Spark 社区最活跃的贡献者之一,目前主要负责 Spark Core/SQL 的设计开发和开源社区管理。Spark 作为目前大数据领域使用最普及的 w397090770 4年前 (2021-11-30) 735℃ 0评论0喜欢
背景 随着公司这两年业务的迅速扩增,业务数据量和数据处理需求也是呈几何式增长,这对底层的存储和计算等基础设施建设提出了较高的要求。本文围绕计算集群资源使用和资源调度展开,将带大家了解集群资源调度的整体过程、面临的问题,以及我们在底层所做的一系列开发优化工作。资源调度框架---YarnYarn的总体结 zz~~ 4年前 (2021-11-16) 615℃ 0评论0喜欢
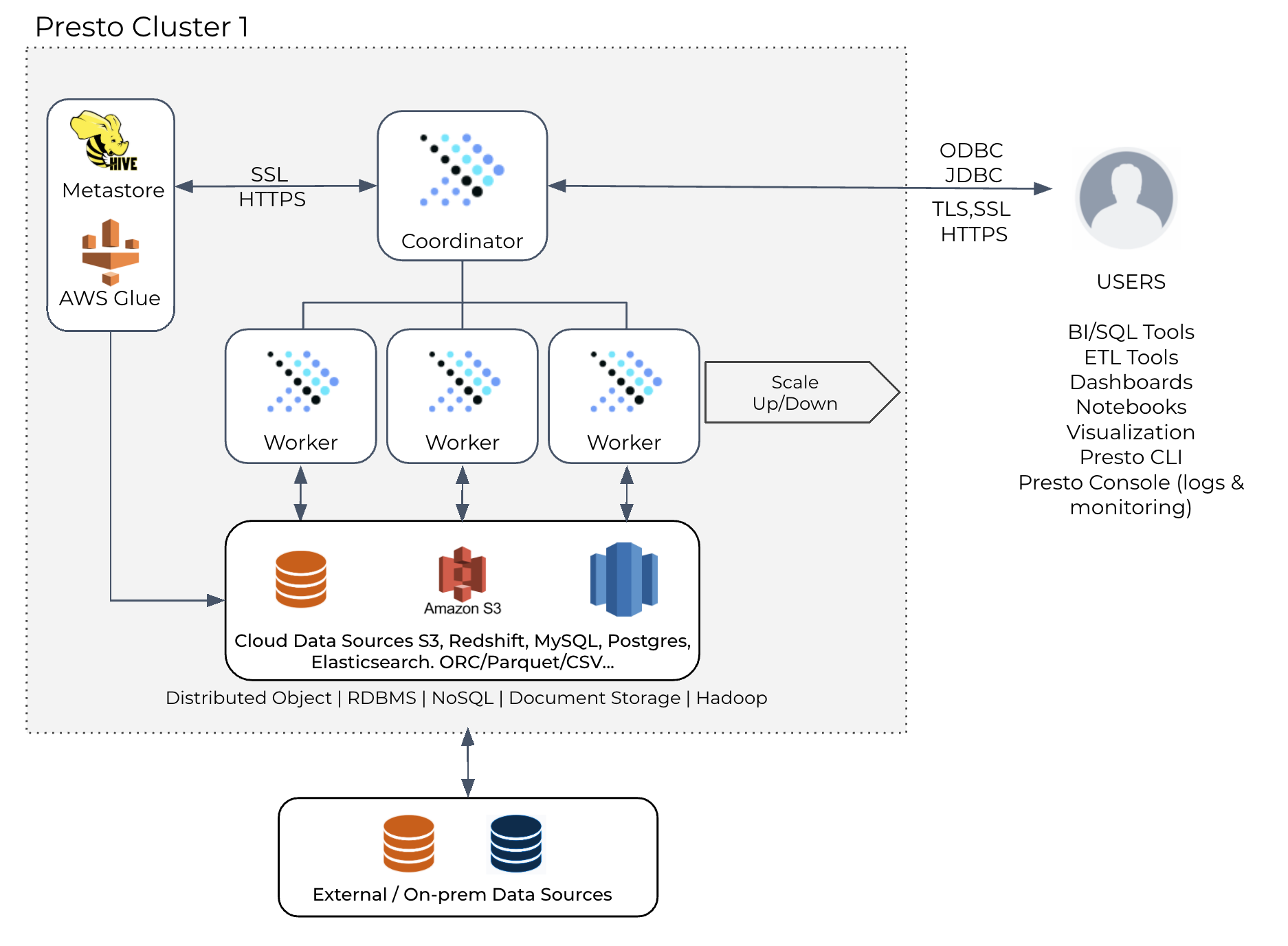
概述Presto 最初设计是对数据仓库中的数据运行交互式查询,但现在它已经发展成为一个位于开放数据湖分析之上的统一 SQL 引擎,用于交互式和批处理工作负载,数据湖上的流行工作负载包括:报告和仪表盘:这包括为内部和外部开发人员提供自定义报告以获取业务洞察力,以及许多使用 Presto 进行交互式 A/B 测试分析的组织 w397090770 4年前 (2021-11-14) 1506℃ 0评论1喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Best Practice in Accelerating Data Applications with Spark+Alluxio》的分享,作者来自 Alluxio 的 David Zhu。本次演讲将分享 Alluxio 和 Spark 集成解决方案的设计和用例,以及在设计和实现 Alluxio分 布式系统时的最佳实践以及不要做什么。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 4年前 (2021-10-28) 621℃ 0评论1喜欢
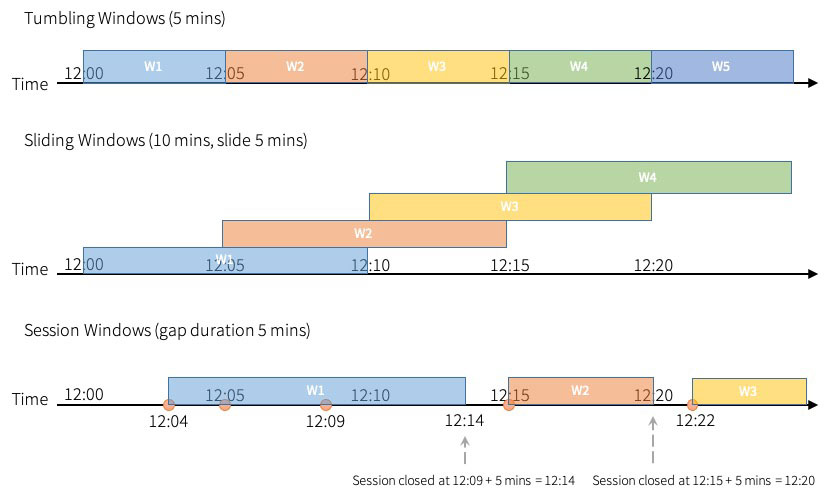
Apache Spark™ Structured Streaming 允许用户在事件时间的窗口上进行聚合。 在 Apache Spark 3.2™ 之前,Spark 支持滚动窗口(tumbling windows)和滑动窗口( sliding windows)。在已经发布的 Apache Spark 3.2 中,社区添加了“会话窗口(session windows)”作为新支持的窗口类型,它适用于流查询和批处理查询什么是会话窗口如果想及时了解Spark、Had w397090770 4年前 (2021-10-21) 963℃ 0评论0喜欢
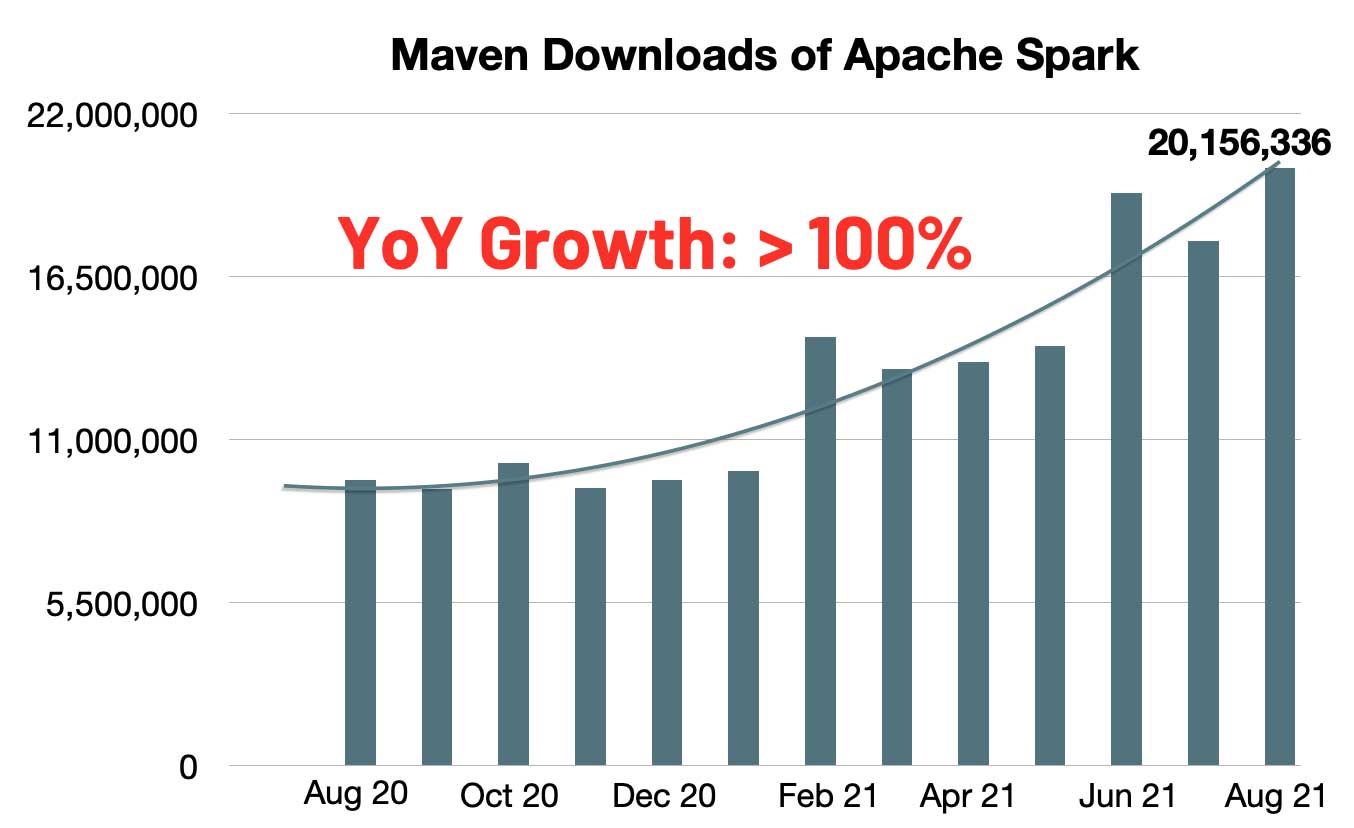
经过七轮投票, Apache Spark™ 3.2 终于在昨天正式发布了。Apache Spark™ 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照惯例,这个版本应该不是稳定版,所以建议大家不要在生产环境中使用。Spark 的每月 Maven 下载数量迅速增长到 2000 万,与去年同期相比,Spark 的月下载量翻了一番。Spark 已成为在单节 w397090770 4年前 (2021-10-20) 1507℃ 0评论3喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 w397090770 4年前 (2021-10-19) 983℃ 0评论2喜欢