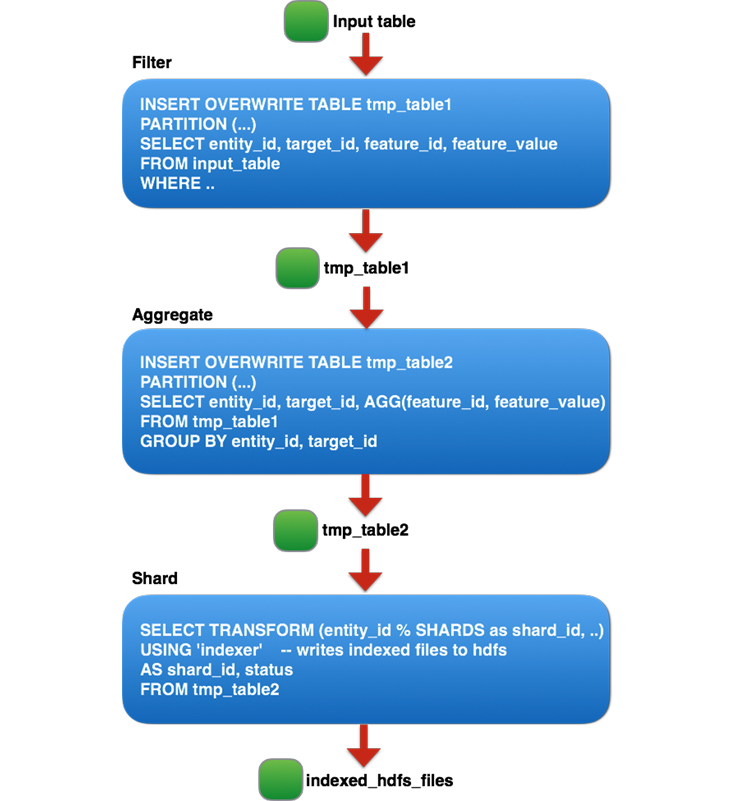
Facebook 经常使用分析来进行数据驱动的决策。在过去的几年里,用户和产品都得到了增长,使得我们分析引擎中单个查询的数据量达到了数十TB。我们的一些批处理分析都是基于 Hive 平台(Apache Hive 是 Facebook 在2009年贡献给社区的)和 Corona( Facebook 内部的 MapReduce 实现)进行的。Facebook 还针对包括 Hive 在内的多个内部数据存储,继续 w397090770 4年前 (2019-12-19) 1707℃ 0评论10喜欢
Delta Lake 0.5.0 于2019年12月13日正式发布,正式版本可以到 这里 下载使用。这个版本支持多种查询引擎查询 Delta Lake 的数据,比如常见的 Hive、Presto 查询引擎。并发操作得到改进。当然,这个版本还是不支持直接使用 SQL 去增删改查 Delta Lake 的数据,这个可能得等到明年1月的 Apache Spark 3.0.0 的发布。好了,下面我们来详细介绍这个版本 w397090770 4年前 (2019-12-15) 1737℃ 0评论2喜欢
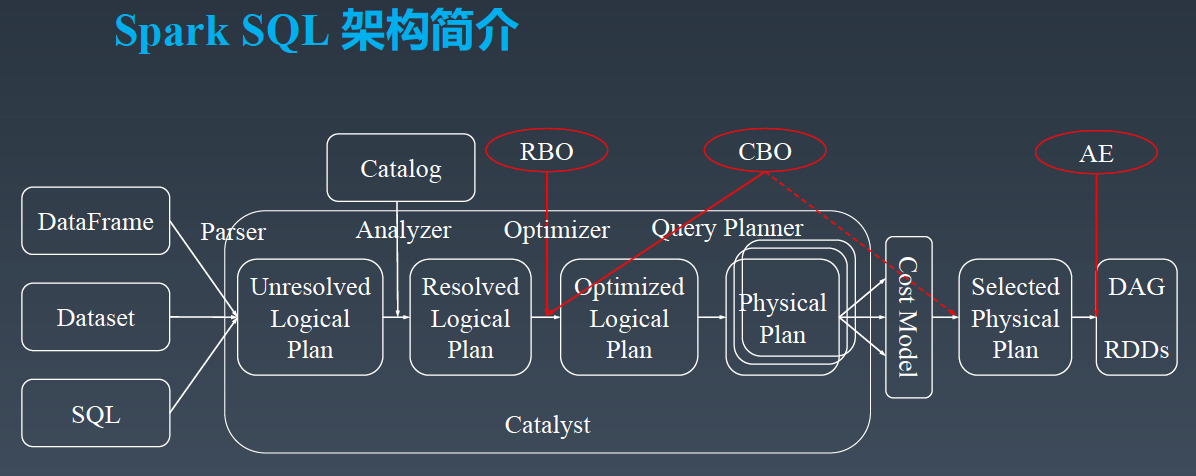
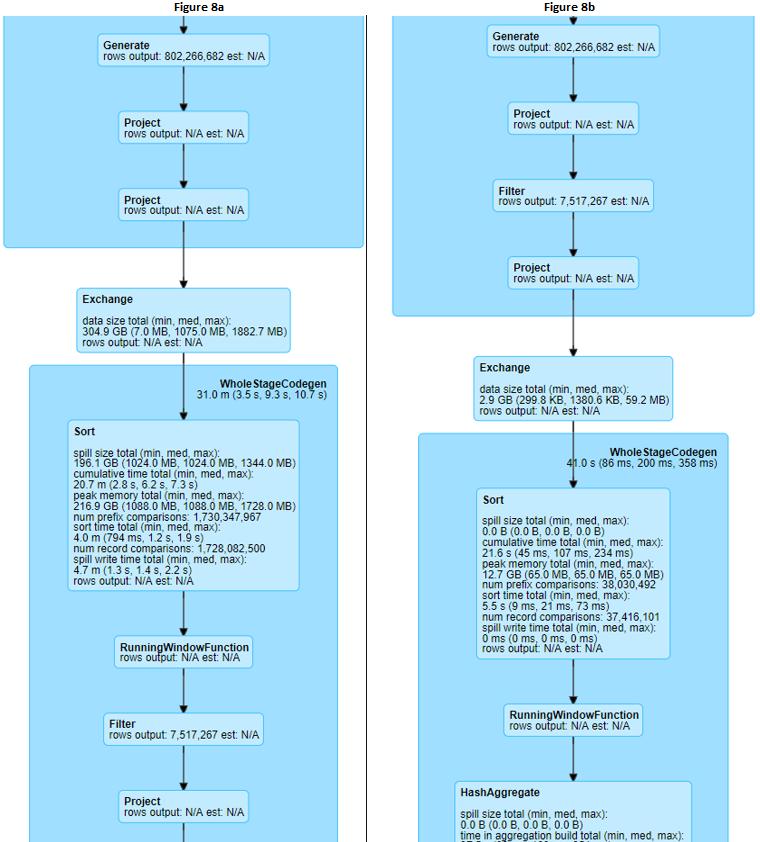
以下是字节跳动数据仓库架构负责人郭俊的分享主题沉淀,《字节跳动在Spark SQL上的核心优化实践》。PPT 请微信关注过往记忆大数据,并回复 bd_sparksql 获取。今天的分享分为三个部分,第一个部分是 SparkSQL 的架构简介,第二部分介绍字节跳动在 SparkSQL 引擎上的优化实践,第三部分是字节跳动在 Spark Shuffle 稳定性提升和性能 w397090770 4年前 (2019-12-03) 4170℃ 0评论3喜欢
在本文中,我将分享一些关于如何编写可伸缩的 Apache Spark 代码的技巧。本文提供的示例代码实际上是基于我在现实世界中遇到的。因此,通过分享这些技巧,我希望能够帮助新手在不增加集群资源的情况下编写高性能 Spark 代码。背景我最近接手了一个 notebook ,它主要用来跟踪我们的 AB 测试结果,以评估我们的推荐引擎的性能 w397090770 4年前 (2019-11-26) 1561℃ 0评论4喜欢
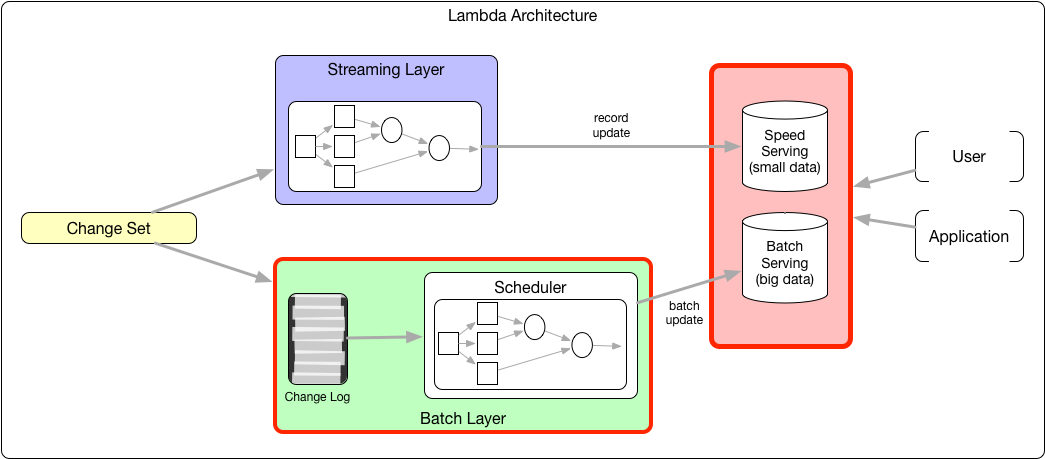
随着 Apache Parquet 和 Apache ORC 等存储格式以及 Presto 和 Apache Impala 等查询引擎的发展,Hadoop 生态系统有可能成为一个面向几分钟延迟工作负载的通用统一服务层。但是,为了实现这一点,需要在 Hadoop 分布式文件系统(HDFS)中实现高效、低延迟的数据摄取和数据准备。为了解决这个问题,Uber 构建了Hudi(被称为“hoodie”),这是一个 w397090770 4年前 (2019-11-21) 5060℃ 2评论9喜欢
今天早上 06:53(2019年11月08日 06:53) 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3.0 版本进行大规模社区测试。无论是从 API 还是从功能上来说,这个预览版都不是一个稳定的版本,它的主要目的是为了让社区提前尝试 Apache Spark 3.0 的新特性。如果大家想 w397090770 5年前 (2019-11-08) 2047℃ 0评论6喜欢
我在 这篇 文章中介绍了 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning),里面涉及到动态分区的优化思路等,但是并没有涉及到如何使用,本文将介绍在什么情况下会启用动态分区裁剪。并不是什么查询都会启用动态裁剪优化的,必须满足以下几个条件:spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true,不过这 w397090770 5年前 (2019-11-08) 2125℃ 0评论3喜欢
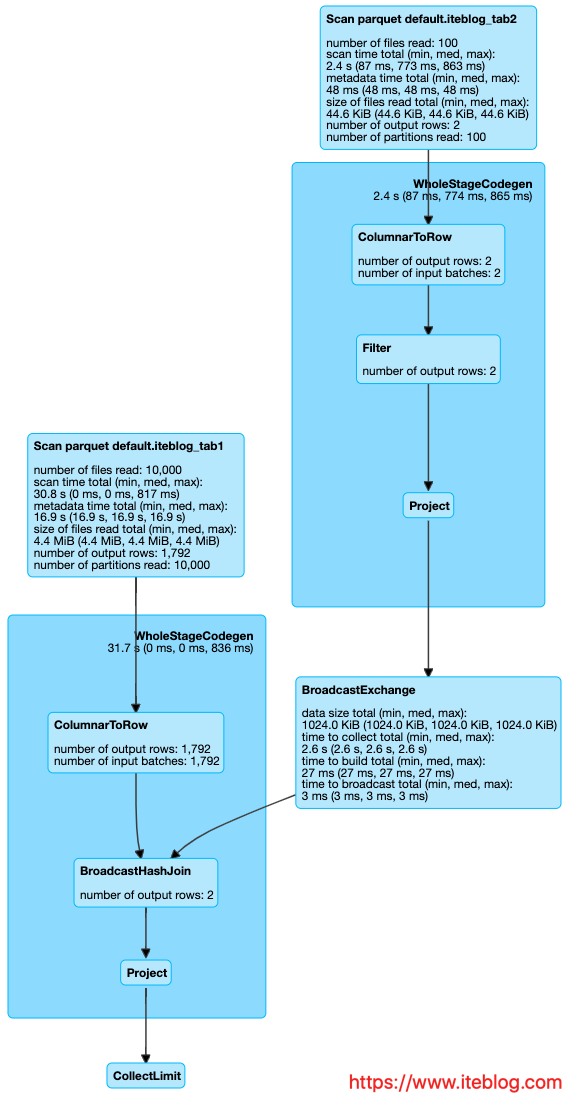
静态分区裁剪(Static Partition Pruning)用过 Spark 的同学都知道,Spark SQL 在查询的时候支持分区裁剪,比如我们如果有以下的查询:[code lang="sql"]SELECT * FROM Sales_iteblog WHERE day_of_week = 'Mon'[/code]Spark 会自动进行以下的优化:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从上图可以看到,S w397090770 5年前 (2019-11-04) 2477℃ 0评论6喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 998℃ 0评论1喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1440℃ 1评论0喜欢




![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)