在《在Kafka中使用Avro编码消息:Producter篇》 和 《在Kafka中使用Avro编码消息:Consumer篇》 两篇文章里面我介绍了直接使用原生的 Kafka API生成和消费 Avro 类型的编码消息,本文将继续介绍如何通过 Spark 从 Kafka 中读取这些 Avro 格式化的消息。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop其 zz~~ 8年前 (2017-09-26) 4805℃ 0评论19喜欢
我在《在Kafka中使用Avro编码消息:Producter篇》文章中简单介绍了如何发送 Avro 类型的消息到 Kafka。本文接着上文介绍如何从 Kafka 读取 Avro 格式的消息。关于 Avro 我这就不再介绍了。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从 Kafka 中读取 Avro 格式的消息从 Kafka 中读取 Avro 格式的消 w397090770 8年前 (2017-09-25) 6585℃ 0评论16喜欢
本文将介绍如何在 Kafka 中使用 Avro 来序列化消息,并提供完整的 Producter 代码共大家使用。AvroAvro 是一个数据序列化的系统,它可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。因为本文并不是专门介绍 Avro 的文章,如需要更加详细地 zz~~ 8年前 (2017-09-22) 7198℃ 2评论23喜欢
《Apache Kafka消息格式的演变(0.7.x~0.10.x)》《图解Apache Kafka消息偏移量的演变(0.7.x~0.10.x)》《Kafka消息时间戳及压缩消息对时间戳的处理》本博客的《Apache Kafka消息格式的演变(0.7.x~0.10.x)》文章中介绍了 Kafka 各个版本的格式变化。其中 Kafka 0.10.x 消息的一大变化是引入了消息时间戳的字段。本文将介绍 Kafka 消息引入时间戳的必要性 w397090770 8年前 (2017-09-01) 7737℃ 0评论23喜欢
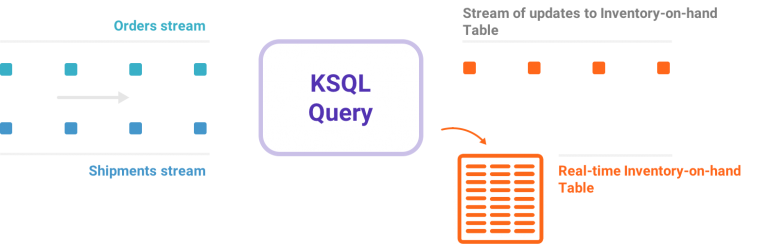
我非常高兴地宣布KSQL,这是面向Apache Kafka的一种数据流SQL引擎。KSQL降低了数据流处理这个领域的准入门槛,为使用Kafka处理数据提供了一种简单的、完全交互的SQL界面。你不再需要用Java或Python之类的编程语言编写代码了!KSQL具有这些特点:开源(采用Apache 2.0许可证)、分布式、可扩展、可靠、实时。它支持众多功能强大的数据流 w397090770 8年前 (2017-08-30) 7981℃ 0评论22喜欢
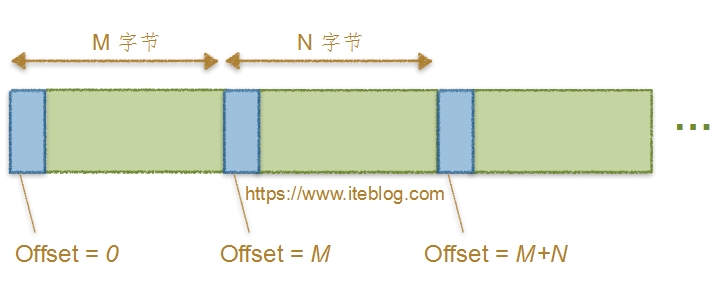
我在《Apache Kafka消息格式的演变(0.7.x~0.10.x)》文章中介绍了 Kafka 几个版本的消息格式。仔细的同学肯定看到了在 MessageSet 中的 Message 都有一个 Offset 与之一一对应,本文将探讨 Kafka 各个版本对消息中偏移量的处理。同样是从 Kafka 0.7.x 开始介绍,并依次介绍到 Kafka 0.10.x,由于 Kafka 0.11.x 正在开发中,而且消息格式已经和之前版本大不 w397090770 8年前 (2017-08-16) 5229℃ 0评论16喜欢
用 Kafka 这么久,从来都没去了解 Kafka 消息的格式。今天特意去网上搜索了以下,发现这方面的资料真少,很多资料都是官方文档的翻译;而且 Kafka 消息支持压缩,对于压缩消息的格式的介绍更少。基于此,本文将以图文模式介绍 Kafka 0.7.x、0.8.x 以及 0.10.x 等版本 Message 格式,因为 Kafka 0.9.x 版本的消息格式和 0.8.x 一样,我就不单独 w397090770 8年前 (2017-08-11) 3808℃ 0评论16喜欢
我们在《Kafka创建Topic时如何将分区放置到不同的Broker中》文章中已经学习到创建 Topic 的时候分区是如何分配到各个 Broker 中的。今天我们来介绍分区分配到 Broker 中之后,会再哪个目录下创建文件夹。我们知道,在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录 w397090770 8年前 (2017-08-09) 5208℃ 0评论15喜欢
熟悉 Kafka 的同学肯定知道,每个主题有多个分区,每个分区会存在多个副本,本文今天要讨论的是这些副本是怎么样放置在 Kafka 集群的 Broker 中的。大家可能在网上看过这方面的知识,网上对这方面的知识是千变一律,都是如下说明的:为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。Kafka分配Replica的 w397090770 8年前 (2017-08-08) 7070℃ 26喜欢
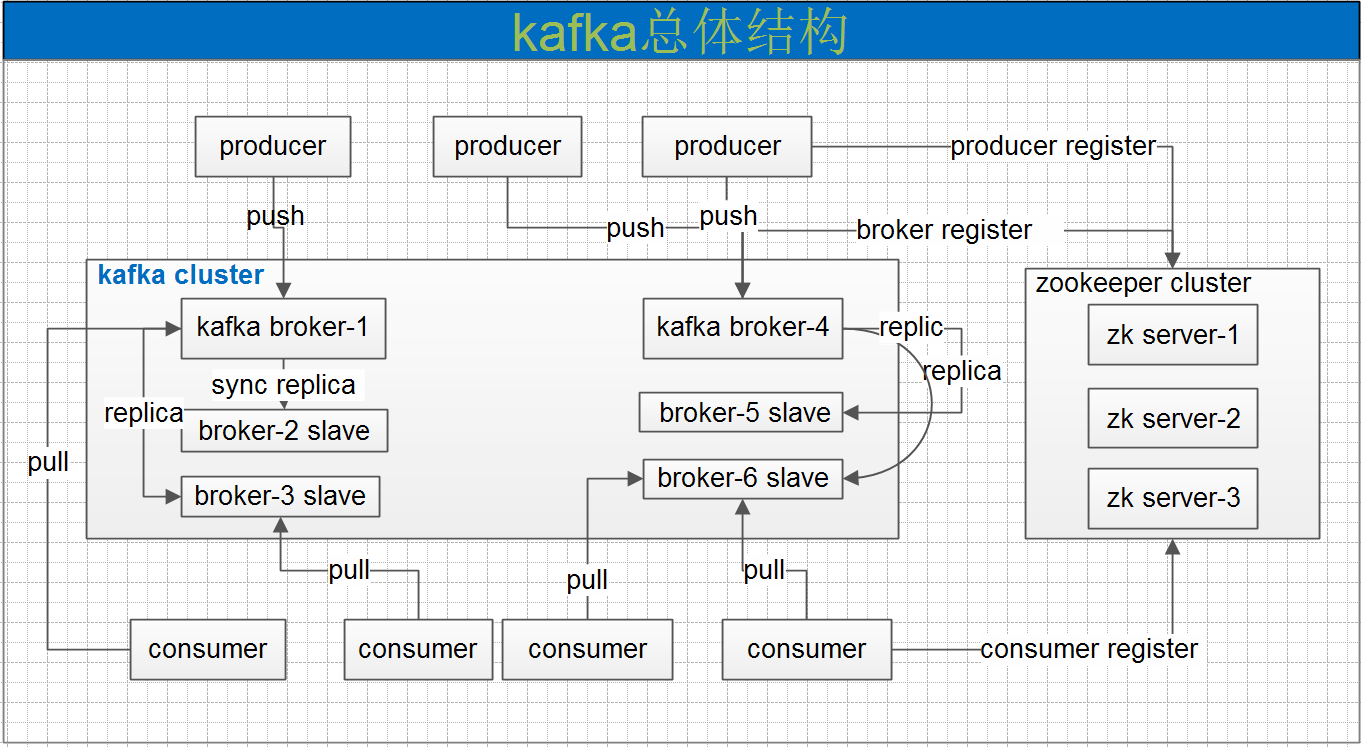
Kafka的基本介绍Kafka最初由Linkedin公司开发,是一个分布式、分区、多副本、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常用于web/nginx日志、访问日志,消息服务等等场景。Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。Kafka主要设计目标如下: w397090770 8年前 (2017-08-03) 5450℃ 0评论14喜欢