目前,Apache Kafka 使用 Apache ZooKeeper 来存储它的元数据,比如分区的位置和主题的配置等数据就是存储在 ZooKeeper 集群中。在 2019 年社区提出了一个计划,以打破这种依赖关系,并将元数据管理引入 Kafka 本身。所以 Apache Kafka 为什么要移除 Zookeeper 的依赖?Zookeeper 有什么问题?实际上,问题不在于 ZooKeeper 本身,而在于外部元数据 w397090770 5年前 (2020-05-19) 1468℃ 0评论1喜欢
Apache Kafka 2.5.0 稳定版于美国当地时间2020年4月15日正式发布,这个版本包含了一系列的重要功能发布,比较重要的可以特性重要包括:支持 TLS 1.3 (目前默认是用 1.2)Kafka Streams DSL 中支持 Co-groups; Kafka Consumer 支持增量再平衡(Incremental rebalance)为更好地洞察算子运行,引入了新的指标;Apache Zookeeper 升级到 3.5.7不再支持 Scala w397090770 5年前 (2020-04-19) 1765℃ 0评论3喜欢
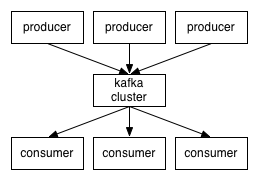
本文主要讲解 Kafka 是什么、Kafka 的架构包括工作流程和存储机制,以及生产者和消费者,最终大家会掌握 Kafka 中最重要的概念,分别是 broker、producer、consumer、consumer group、topic、partition、replica、leader、follower,这是学会和理解 Kafka 的基础和必备内容。1. 定义Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主 w397090770 5年前 (2020-03-14) 1664℃ 0评论10喜欢
2019年12月18日 Apache Kafka 2.4 正式发布了,这个版本有很多新功能,本文将介绍这个版本比较重要的功能,完整的更新可以参见 release notes如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopKafka broker, producer, 以及 consumer 新功能KIP-392: 允许消费者从最近的副本获取数据在 Kafka 2.4 版本之前,消费者 w397090770 6年前 (2019-12-25) 1633℃ 0评论4喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 6年前 (2019-09-23) 12633℃ 0评论34喜欢
最近很多粉丝后台留言问了一些大数据的面试题,其中包括了大量的 Kafka、Spark等相关的问题,所以我特意抽出一些时间整理了一些场景的大数据相关面试题,本文是 Kafka 面试相关问题,其他系列面试题后面会陆续整理,欢迎关注过往记忆大数据公众号。当然,由于个人知识面的限制,还有很多面试题相关的东西本文没有收集整理 w397090770 6年前 (2019-09-14) 17169℃ 3评论37喜欢
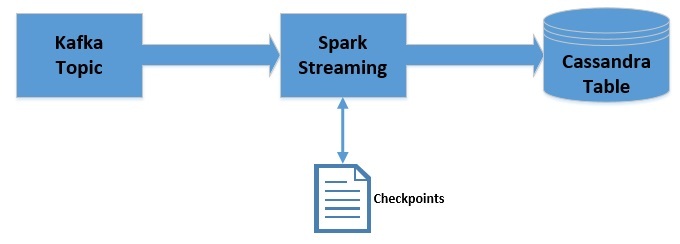
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 6年前 (2019-09-08) 4139℃ 0评论8喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 6年前 (2019-08-13) 5711℃ 2评论33喜欢
Apache Kafka 近期发布了 2.3.0 版本,主要的新特性如下:Kafka Connect REST API 已经有了一些改进。Kafka Connect 现在支持增量协同重新均衡(incremental cooperative rebalancing)Kafka Streams 现在支持内存会话存储和窗口存储;AdminClient 现在允许用户确定他们有权对主题执行哪些操作;broker 增加了一个新的启动时间指标;JMXTool现在可以连接到安 w397090770 6年前 (2019-06-27) 3101℃ 0评论6喜欢
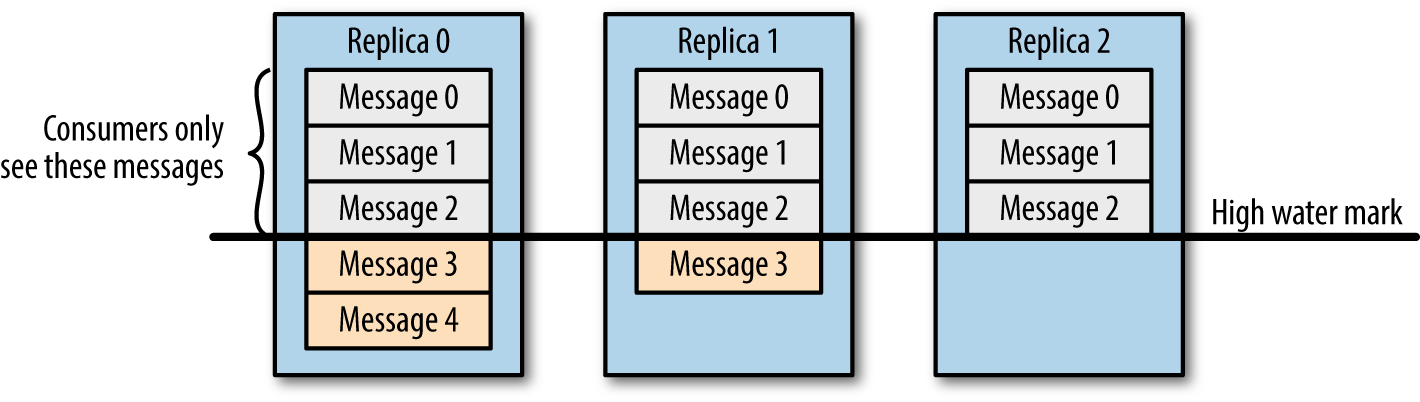
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 w397090770 6年前 (2019-06-11) 12981℃ 2评论42喜欢