在《Kafka集群扩展以及重新分布分区》文章中我们介绍了如何重新分布分区,在那里面我们基本上把所有的分区全部移动了,其实我们完全没必要移动所有的分区,而移动其中部分的分区。比如我们想把Broker 1与Broker 7上面的分区数据互换,如下图所示:可以看出,只有Broker 1与Broker 7上面的分区做了移动。来看看移动分区之 w397090770 9年前 (2016-03-31) 3392℃ 0评论4喜欢
我们往Kafka发送消息时一般都是将消息封装到KeyedMessage类中:[code lang="scala"]val message = new KeyedMessage[String, String](topic, key, content)producer.send(message)[/code]Kafka会根据传进来的key计算其分区ID。但是这个Key可以不传,根据Kafka的官方文档描述:如果key为null,那么Producer将会把这条消息发送给随机的一个Partition。If the key is null, the w397090770 9年前 (2016-03-30) 16552℃ 0评论10喜欢
我们都知道,使用Kafka Producer往Kafka的Broker发送消息的时候,Kafka会根据消息的key计算出这条消息应该发送到哪个分区。默认的分区计算类是HashPartitioner,其实现如下:[code lang="scala"]class HashPartitioner(props: VerifiableProperties = null) extends Partitioner { def partition(data: Any, numPartitions: Int): Int = { (data.hashCode % numPartitions) }}[/code] w397090770 9年前 (2016-03-29) 9302℃ 0评论9喜欢
昨天Kafka集群磁盘容量达到了90%,于是赶紧将Log的保存时间设置成24小时,但是发现设置完之后Log仍然没有被删除。于是今天特意去看了一下Kafka日志删除相关的代码,于是有了这篇文章。 在使用Kafka的时候我们一般都会根据需求对Log进行保存,比如保存1天、3天或者7天之类的,我们可以通过以下的几个参数实现:[code lan w397090770 9年前 (2016-03-28) 5632℃ 0评论17喜欢
当一个broker停止或者crashes时,所有本来将它作为leader的分区将会把leader转移到其它broker上去。这意味着当这个broker重启时,它将不再担任何分区的leader,kafka的client也不会从这个broker来读取消息,从而导致资源的浪费。比如下面的broker 7是挂掉重启的,我们可以发现Partition 1虽然在broker 7上有数据,但是由于它挂了,所以Kafka重新 w397090770 9年前 (2016-03-24) 8433℃ 0评论5喜欢
hljs.initHighlightingOnLoad(); 我们往已经部署好的Kafka集群里面添加机器是最正常不过的需求,而且添加起来非常地方便,我们需要做的事是从已经部署好的Kafka节点中复制相应的配置文件,然后把里面的broker id修改成全局唯一的,最后启动这个节点即可将它加入到现有Kafka集群中。 但是问题来了,新添加的Kafka节点并不会 w397090770 9年前 (2016-03-24) 12866℃ 2评论23喜欢
Kafka内部提供了许多管理脚本,这些脚本都放在$KAFKA_HOME/bin目录下,而这些类的实现都是放在源码的kafka/core/src/main/scala/kafka/tools/路径下。Consumer Offset Checker Consumer Offset Checker主要是运行kafka.tools.ConsumerOffsetChecker类,对应的脚本是kafka-consumer-offset-checker.sh,会显示出Consumer的Group、Topic、分区ID、分区对应已经消费的Offset、 w397090770 9年前 (2016-03-18) 16254℃ 0评论13喜欢
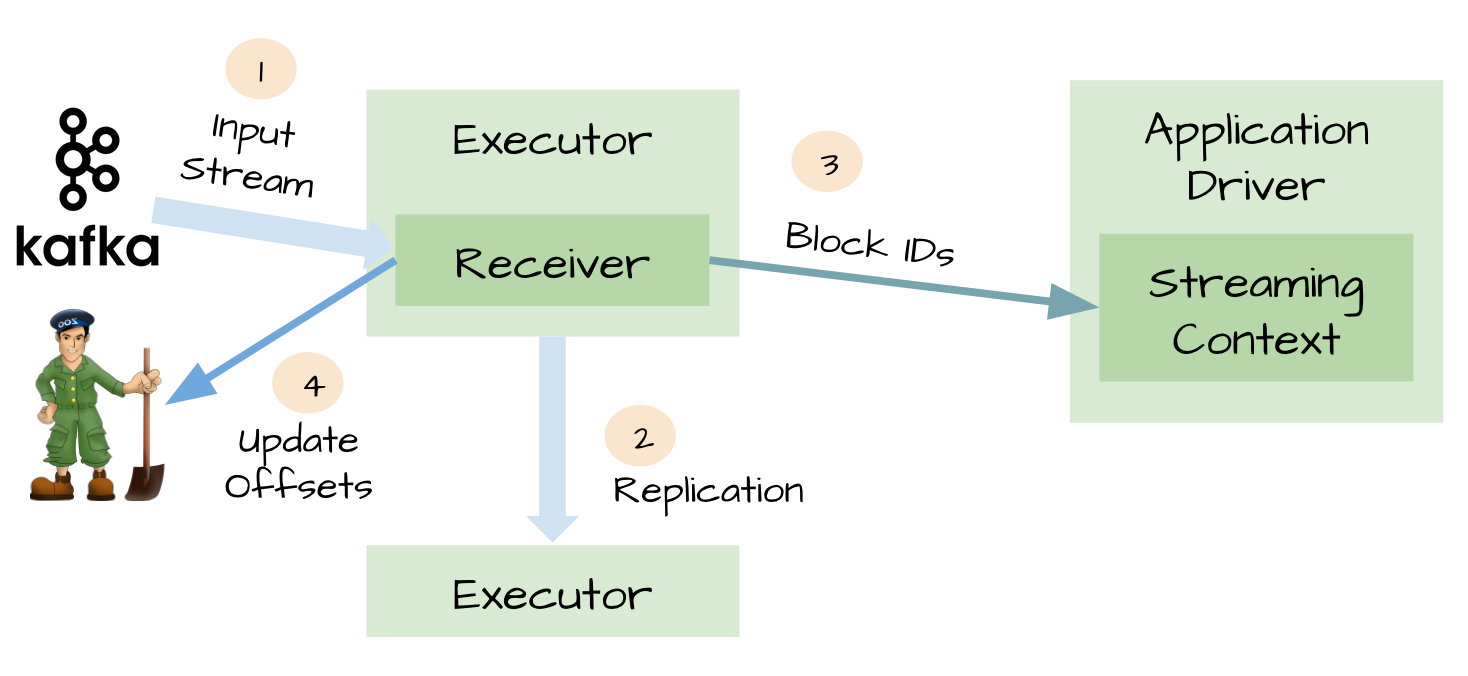
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。为了体验这个关键的特性,你需要满足以下几个先决条件: 1、输入的数据来自可靠的数据源和可靠的接收器; 2、应用程序的metadata被application的driver持久化了(checkpointed ); 3、启用了WAL特性(Write ahead log)。 下面我将简单 w397090770 9年前 (2016-03-02) 17741℃ 16评论50喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 在前面的例子(《Apache Kafka编程入门指南:Producer篇》)中,我们学习了如何编写简单的Kafka Producer程序。在那个例子中,在如果需要发送的topic不存在,Producer将会创建它。我们都知 w397090770 10年前 (2016-02-06) 7647℃ 0评论6喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存 w397090770 10年前 (2016-02-05) 10314℃ 1评论12喜欢